标签:time 结果 chain min cve tor 依次 方法 rap
一、解决的问题
这篇文章研究了如何平衡探索(exploration)和利用(exploitation)使得多智能体能够在有限次重复尝试中尽快找到收益最大化的joint action,即解决了多智能体系统中的探索-利用困境。
学习环境:Multi-Agent Multi-Armed Bandits,多智能体多臂赌博机问题。
文章研究的环境模型是多臂赌博机问题的一个拓展。整个系统由多个松散耦合的多臂赌博机构成,并被分为有限个多臂赌博机子集$e$,每个子集$e$中的多臂赌博机(agent)之间存在协同动作(joint action)。
我们定义每个多臂赌博机子集$e$的价值函数为$f^{e}$,它仅仅依赖于该子集$e$中的每个赌博机的动作。整个多臂赌博机系统中的整体价值函数为$F(a)=\sum_{e=1}^{\rho }f^{e}(a^{e})$
二、核心方法
针对多智能体多臂赌博机问题中的探索利用问题,文章提出了一个基于上置信区间(Upper Confidence Bound)的策略选择算法Multi-Agent Upper Confidence Exploration(MAUCE)。对于每一个子集$e$的局部评估,使用一个二维的向量表示:
$v^{e}(a^{e}) = (\hat{\mu }^{e}(a^{e}), n_{t}^{e}(a^{e})^{-1}(r_{max}^{e})^{2})$
其中,$v[1]$表示子集$e$的局部回报评估均值,$v[2]$用于计算整体的置信上界。
整体的置信上界计算方法:
$z_{t}(v(a)) = \hat{\mu }(a) + c_{t}(a) = v[1] + \sqrt{\frac{1}{2}v[2]log(tA)}$
其中
$v(a) = \sum_{e=1}^{\rho }v^{e}(a^{e})$
MAUCE的执行过程:
对于每个迭代次:
1.找最优联合动作$a_{t} = argmax_{a}z_{t}(v(a))$
2.执行动作$a_{t}$分别得到局部reward
$r_{t} = \sum_{e=1}^{\rho }r_{t}^{e}(a_{t}^{e})$
3.使用$r_{t}^{e}(a_{t}^{e})$更新$\hat{\mu }_{t}^{e}(a^{e})$,(更新过程文章没有提及,实验源码中使用了蒙特卡罗评估方法)
$\hat{\mu }_{t}^{e}(a^{e}) = \hat{\mu }_{t}^{e}(a^{e}) + \frac{r_{t}^{e}(a_{t}^{e}-\hat{\mu }_{t}^{e}(a^{e}))}{n_{t}^{e}(a^{e})}$
4.将$n_{t}^{e}(a^{e})$加1
值得注意的是,我们在选取$a_{t}$时,我们可以遍历整个joint action集合找到最优,但是joint action集的大小随agent数量呈指数增长。
针对这一问题,文章使用了基于Variable Elimination的$a_{t}$选取算法Upper Confidence Variable Elimination (UCVE),用于选取最优joint action的策略。
UCVE的核心思想:Eliminating an agent i, is performed by replacing all $u^{e}(a^{e})$ which have i in scope, by a new function that incorporates the possibly optimal responses of i. For each $f^{e}$ of $F(a)$, $F$ contains an identically scoped UCVSF $u^{e}$. Each $u^{e}$ initially contains a singleton set.
$u^{e}(a^{e}) = {v^{e}(a^{e})}$
在这个新的function中,包含了所有i所贡献的可能是最优的joint action。
文章通过一下算式获得所有i参与的向量$v$:
$\nu = \bigcup_{a_{i}\epsilon A_{i}} \bigoplus _{u^{e}\epsilon F_{i}} u^{e}(a_{-i}^{e} \times \left \{ a_{i} \right \})$,
获得所有i参与的向量$v$的集合后,剔除那些不可能参与最优决策的$v^{e}(a^{e})$。
方法:取$F$中与agent i 无关的$u^{e}$,求解其探索部分的最大值和最小值
$x_{u} = \sum_{u^{e}\epsilon F\setminus F_{i}} max_{a^{e}}max_{v\epsilon v^{e}(a^{e})}v[2]$
$x_{l} = \sum_{u^{e}\epsilon F\setminus F_{i}} min_{a^{e}}min_{v\epsilon v^{e}(a^{e})}v[2]$
如果存在$v, v‘ \epsilon \nu $,使得$v[1] + \sqrt{\frac{1}{2}(v[2] + x_{u})log(tA)} < v‘[1] + \sqrt{\frac{1}{2}(v‘[2] + x_{l})log(tA)} $,则$v$不可能组成最优的joint action,将其剔除。将所有的agent视为一个队列,依次消除队列中agent直至空队,最终$F$中只有一个$u$剩余,里面只有一个upper confidence vector $v(a)$,对应的$a$即为选出的最优joint action.
三、实验——使用累积遗憾评估算法的好坏
The expected cumulative regret:
$E\left [ \sum_{t=1}^{T}\Delta (a_{t}) \right ], where \Delta (a) = E\left [ F(a_{*}) \right ]-E\left [ F(a) \right ]$
文章对比了四种算法:
A Uniformly Random Action Selector: 无任何策略,每次随机选取;
Sparse Cooperative Q-Learning(SCQL):使用乐观初始估计以及epsilon-greedy;
Learning with Linear Rewards(LLR):每个多臂赌博机使用UCB算法进行决策,整体的Q值为每一个多臂赌博机Q值的线性和;
MAUCE
采用了三种实际场景:0101-Chain,Gem Mining,Wind Farm(三种实际场景的介绍参照原文)
实验结果:
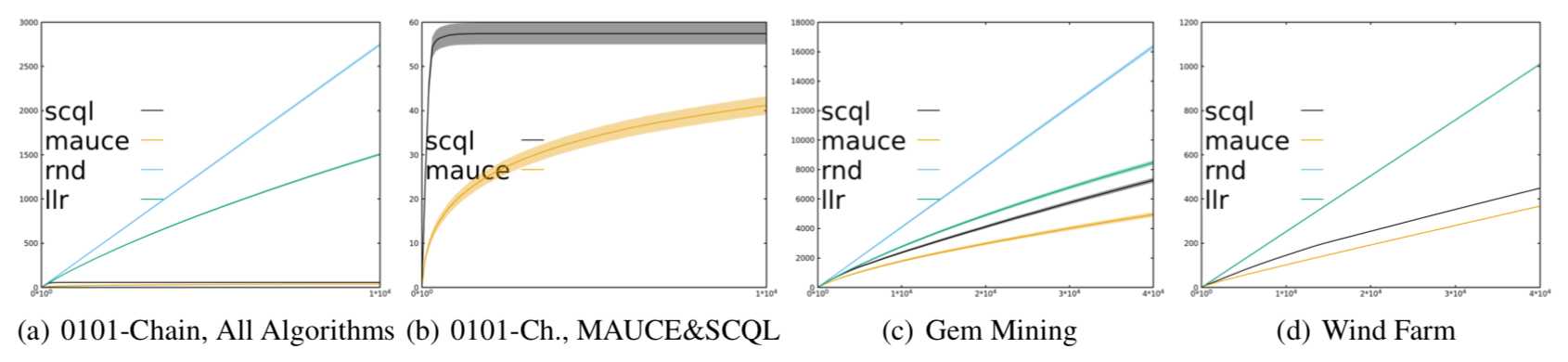
实验结果表明,MAUCE算法在三个实际场景中均获得更好的效果。值得注意的是,0101链中,MAUCE的累积遗憾远低于SCQL(原因:MAUCE的探索策略基于局部探索区间的聚合;SCQL使用epsilon-greedy探索策略)。SCQL基于乐观初始化和极具激进的探索策略很快学习到了最优joint action,但是在探索过程中epsilon-greedy中的参数需要多次微调以获取最好的学习效果,相比之下,MAUCE更为高效。

标签:time 结果 chain min cve tor 依次 方法 rap
原文地址:https://www.cnblogs.com/znnby1997/p/11788546.html