标签:提取 ide orm 时间 write reducer result 分割 取出
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
初步实现数据的分割,没有对时间以及IP进行转换
原始数据:
分割后数据:
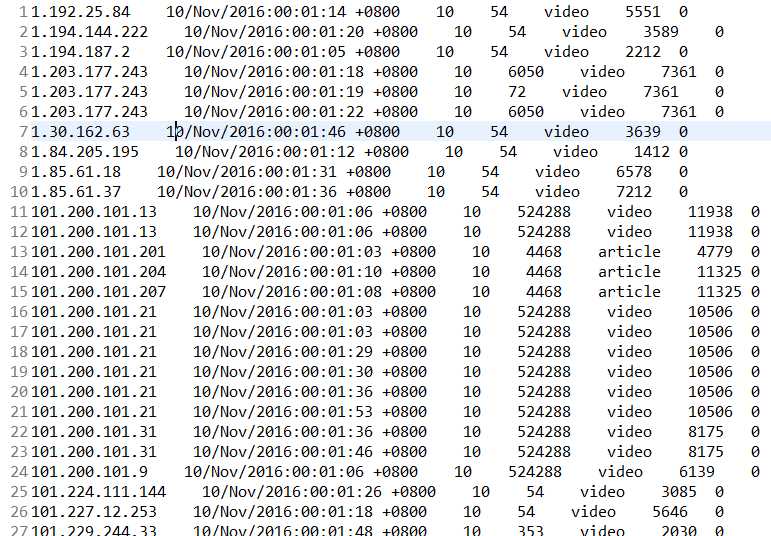
代码使用了之前wordcount样例进行修改,按照,进行了简单分割,但是分割后末尾会出现0,且没有进行数据的转换。

package result; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Mapper.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class Result1 { public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { Job job = Job.getInstance(); job.setJobName("WordCount"); job.setJarByClass(Result1.class); job.setMapperClass(doMapper.class); //job.setReducerClass(doReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); Path in = new Path("hdfs://192.168.187.130:9000/result/result.txt"); Path out = new Path("hdfs://192.168.187.130:9000/result/out"); FileInputFormat.addInputPath(job, in); FileOutputFormat.setOutputPath(job, out); System.exit(job.waitForCompletion(true) ? 0 : 1); } public static class doMapper extends Mapper<Object, Text, Text, IntWritable> { public static final IntWritable one = new IntWritable(); public static Text word = new Text(); Text outputValue = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { String line=value.toString(); String arr[]=line.split(","); word.set(arr[0]+" "+arr[1]+" "+arr[2]+" "+arr[3]+" "+arr[4]+" "+arr[5]); context.write(word,one); } } }
标签:提取 ide orm 时间 write reducer result 分割 取出
原文地址:https://www.cnblogs.com/lixv2018/p/11864231.html
