标签:部分 shuf 就是 方便 模型 shuffle ORC pytorch 作用
DataLoader的作用:通常在训练时我们会将数据集分成若干小的、随机的batch,这个操作当然可以手动操作,但是PyTorch里面为我们提供了API让我们方便地从dataset中获得batch,DataLoader就是干这事儿的。
先看官方文档的描述,包括了每个参数的定义:
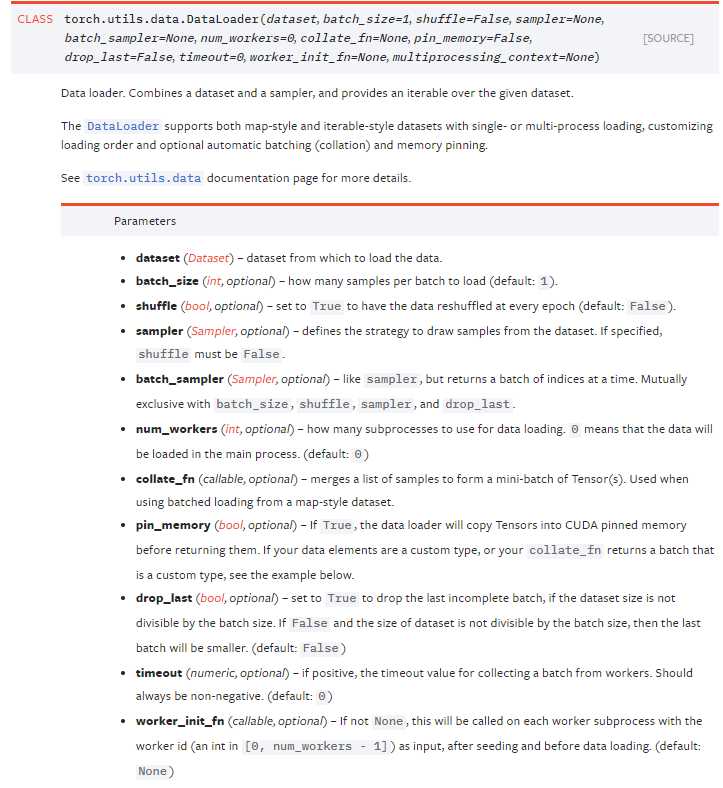
它的本质是一个可迭代对象,一般的操作是:
dataset对象DataLoader对象DataLoader对象,将data, label加载到模型中进行训练#一个粗略的示意
dataset = torchvision.datasets.MNIST() #从torchvision这个包里获得一个dataset对象
train_iter = torch.utils.data.DataLoader(dataset, batch_size = args.batch_size, shuffle = True)#创建DataLoader对象
for epoch in num(epochs):#将数据加载到模型之中
for data, label in train_iter:
...DataLoader还有更多的细节,但现在还没有遇到,所以先记下这部分。
这个博客关于这个话题讲得不错,参考 https://www.cnblogs.com/ranjiewen/p/10128046.html
标签:部分 shuf 就是 方便 模型 shuffle ORC pytorch 作用
原文地址:https://www.cnblogs.com/patrolli/p/11870141.html