标签:print 直接 rabl 顺序 基于 返回 参考资料 特殊 循环
1.树的概念:
2.树的分类
public void preorder (ArrayList<T> iter) {
iter.add (element);
if (left != null)
left.inorder (iter);
if (right != null)
right.inorder (iter);
}public void inorder(ArrayIterator<T> iter){
if(left != null)
left.inorder(iter);
iter.add(element);
if(right != null)
right.inorder(iter);
}public void postorder(ArrayIterator<T> iter){
if(left != null)
left.postorder(iter);
if(right != null)
right.postorder(iter);
iter.add(element);
}public void levelorder(TreeNode root)
{
ArrayDeque<TreeNode> deque=new ArrayDeque<TreeNode>();
deque.add(root);//根节点入队
while(!deque.isEmpty()){
TreeNode temp=deque.remove();
System.out.print(temp.val+"--");
if(temp.left!=null){
deque.add(temp.left);
}
if(temp.right!=null){
deque.add(temp.right);
}
}
}递归实现
public void find(T element)
{
return find(root, element);
}
private void find(BinaryTreeNode root, T element)
{
if (root == null) {
return element;
}
int comparable = element.CompareTo(root.getElement);
if (comparable > 0){
find(root.right,element);
}
else if (comparable < 0){
find(root.left,element);
}
else {
return root.getElement;
}
}public Leaf findparent(int a){
Leaf current=root;
Leaf parent;
while(true){
parent=current;
if(a<current.data){
current=current.left;
if(current.data==a){
break;
}
}
else if(a>current.data) {
current=current.right;
if(current.data==a){
break;
}
}
else
break;
}
return parent;
}删除的结点只有左子树或右子树时,将所删除结点的父结点的指针指向所删除结点仅有的孩子。
public void delete(int a){
Leaf current=find(a);
if(current.left==null&¤t.right==null){
Leaf parent = findparent(a);
if(parent.right==current){
parent.right=null;
}
else if(parent.left==current){
parent.left=null;
}
}
else if(current.right!=null&¤t.left!=null){
int p=findbefore(a);
delete(p);
current.data=p;
}
else if(current.left!=null&¤t.right==null) {
current.data=current.left.data;
current.left=null;
}
else{
current.data=current.right.data;
current.right=null;
}
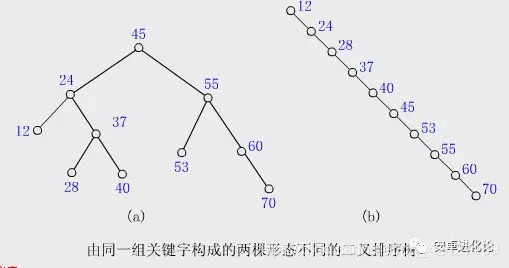
}
问题1:在做二叉树结点删除操作时,删掉叶子结点和仅有一个叉的结点时都很顺利,但是当删除有两个叉的结点时,出现了循环到数组(前驱结点)最小值的情况,最终导致数组下标溢出。
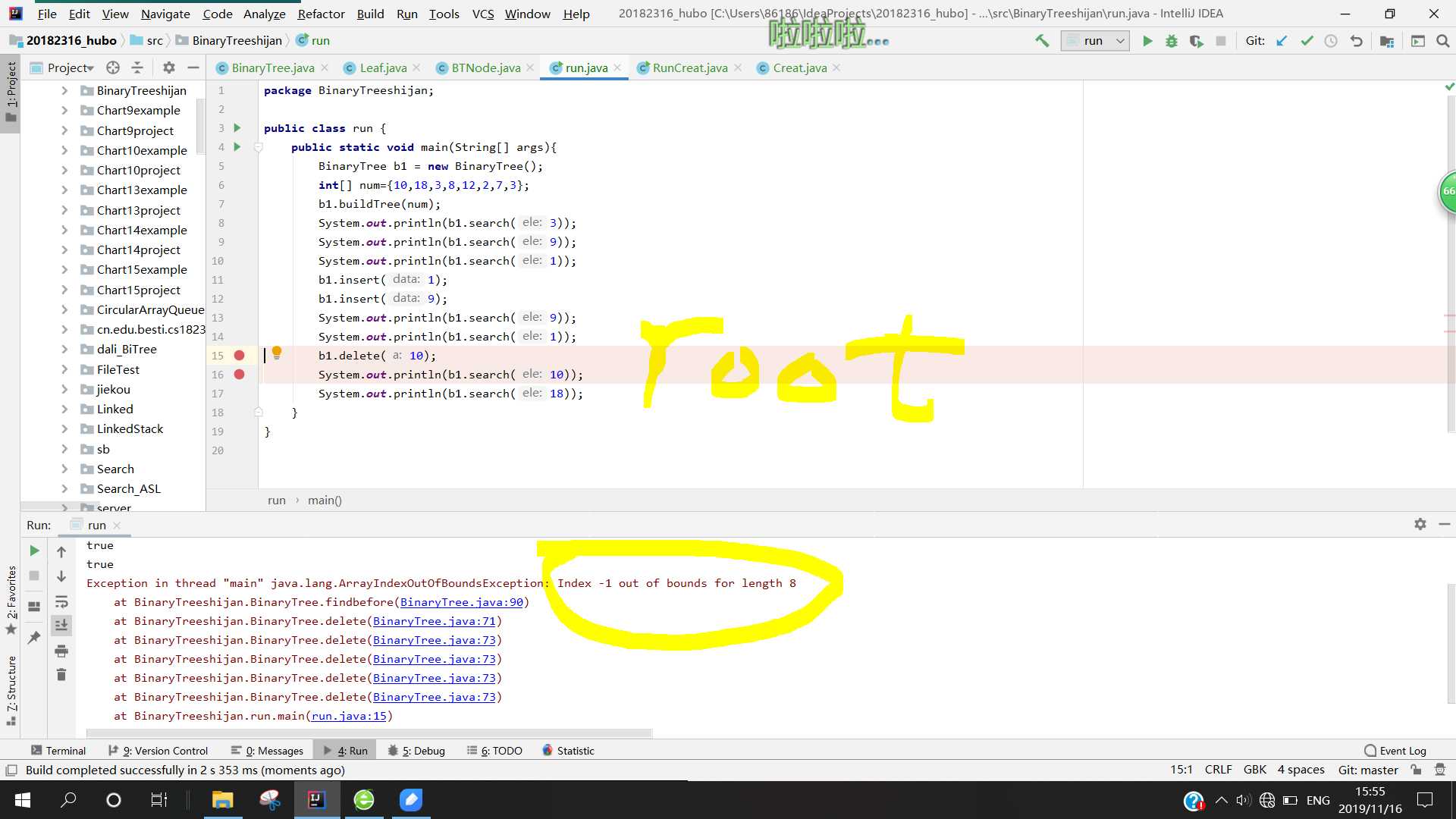
else if(current.right!=null&¤t.left!=null){
int p=findbefore(a);
current.data=p;
delete(p);
}代码的功能就是找到前驱结点,将值赋给删除结点,然后递归删除前驱结点(这里删的是值等于p的结点!!)
也就是说我在将前驱结点的值赋给了被删结点后,再调用delete方法删除值等于p的结点,于是就反复删除该结点,而真正要被删除的前驱结点却依然存在,最终导致一直滑到了最小的结点
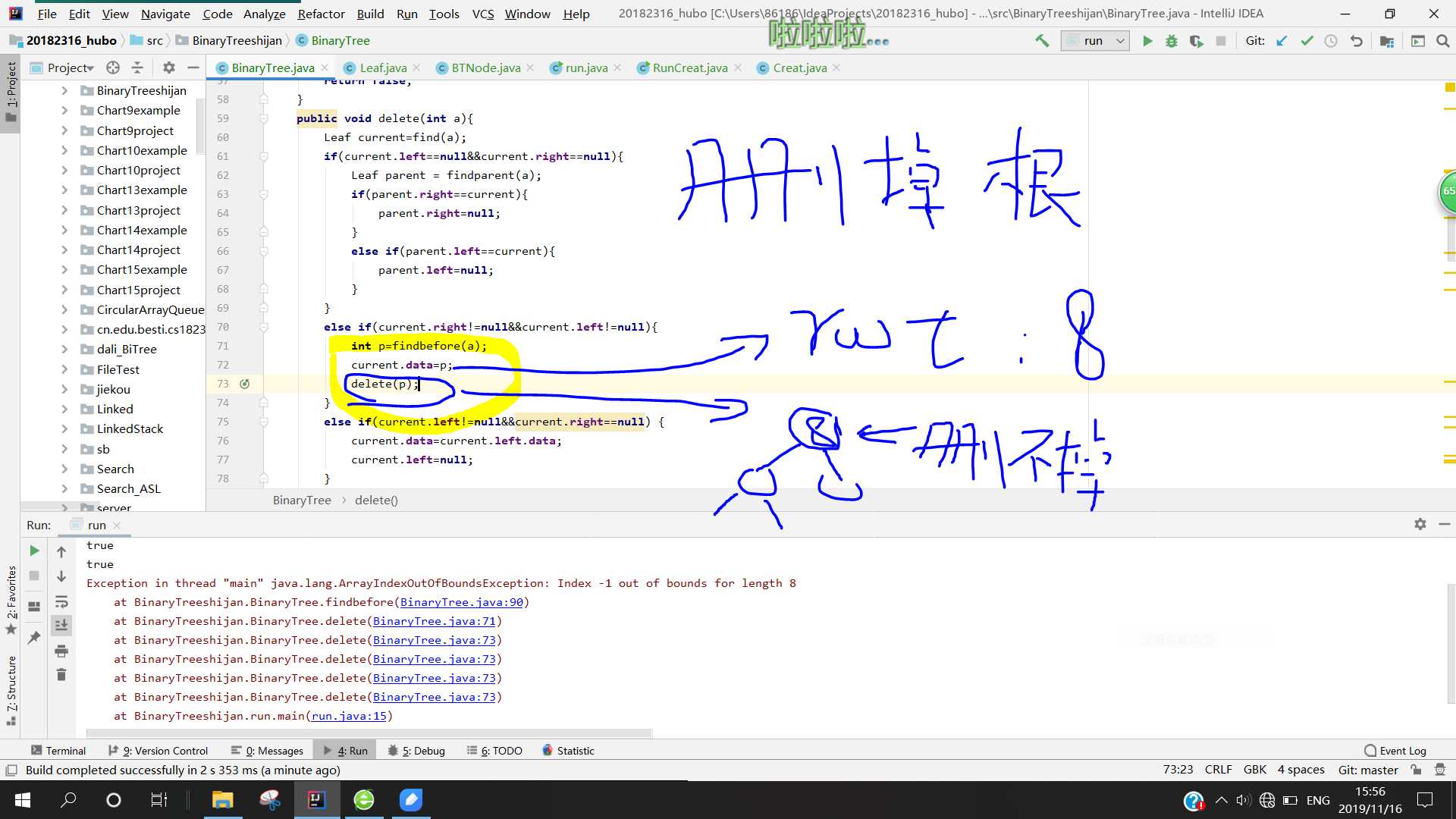
else if(current.right!=null&¤t.left!=null){
int p=findbefore(a);
delete(p);
current.data=p;
}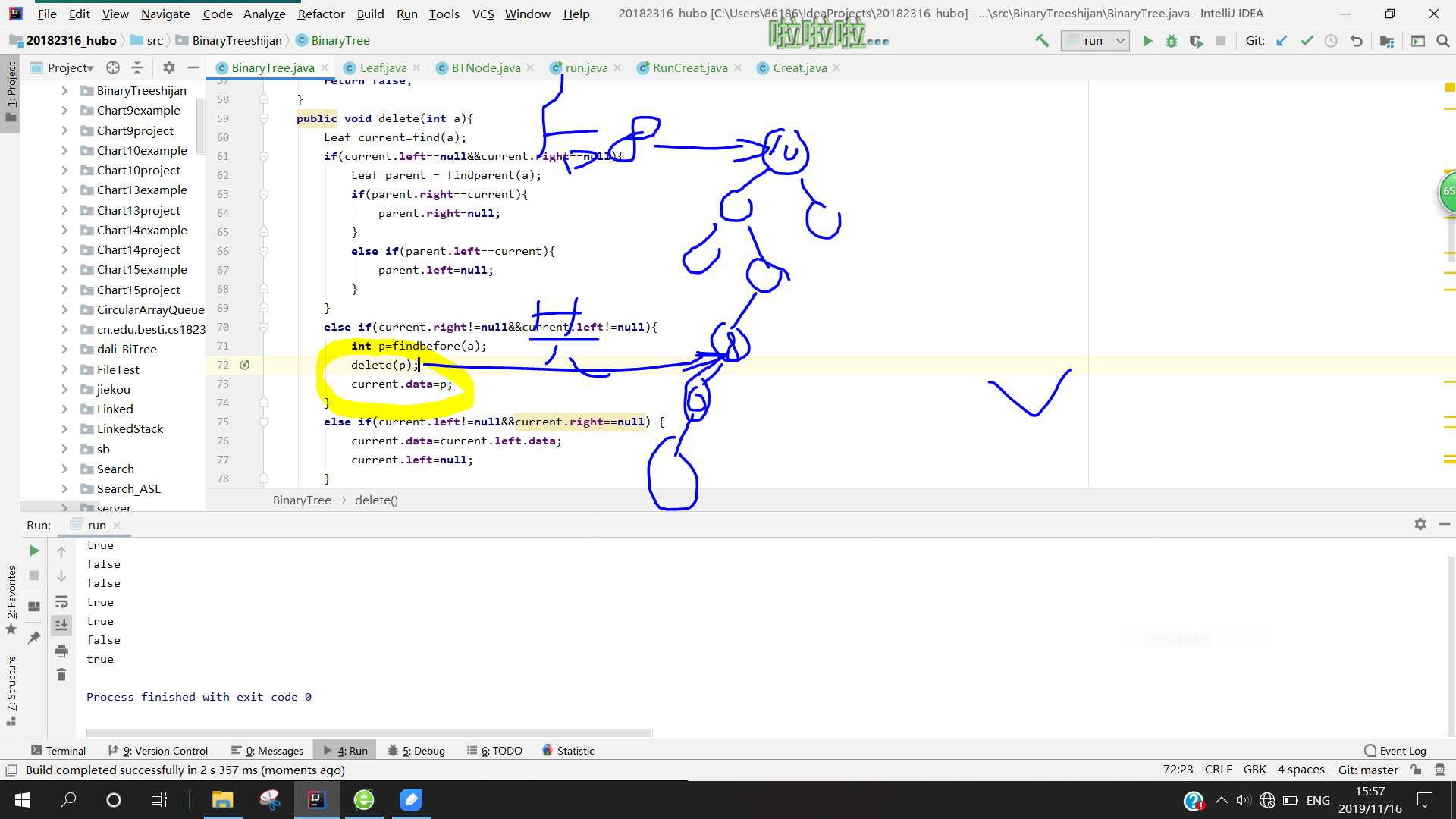
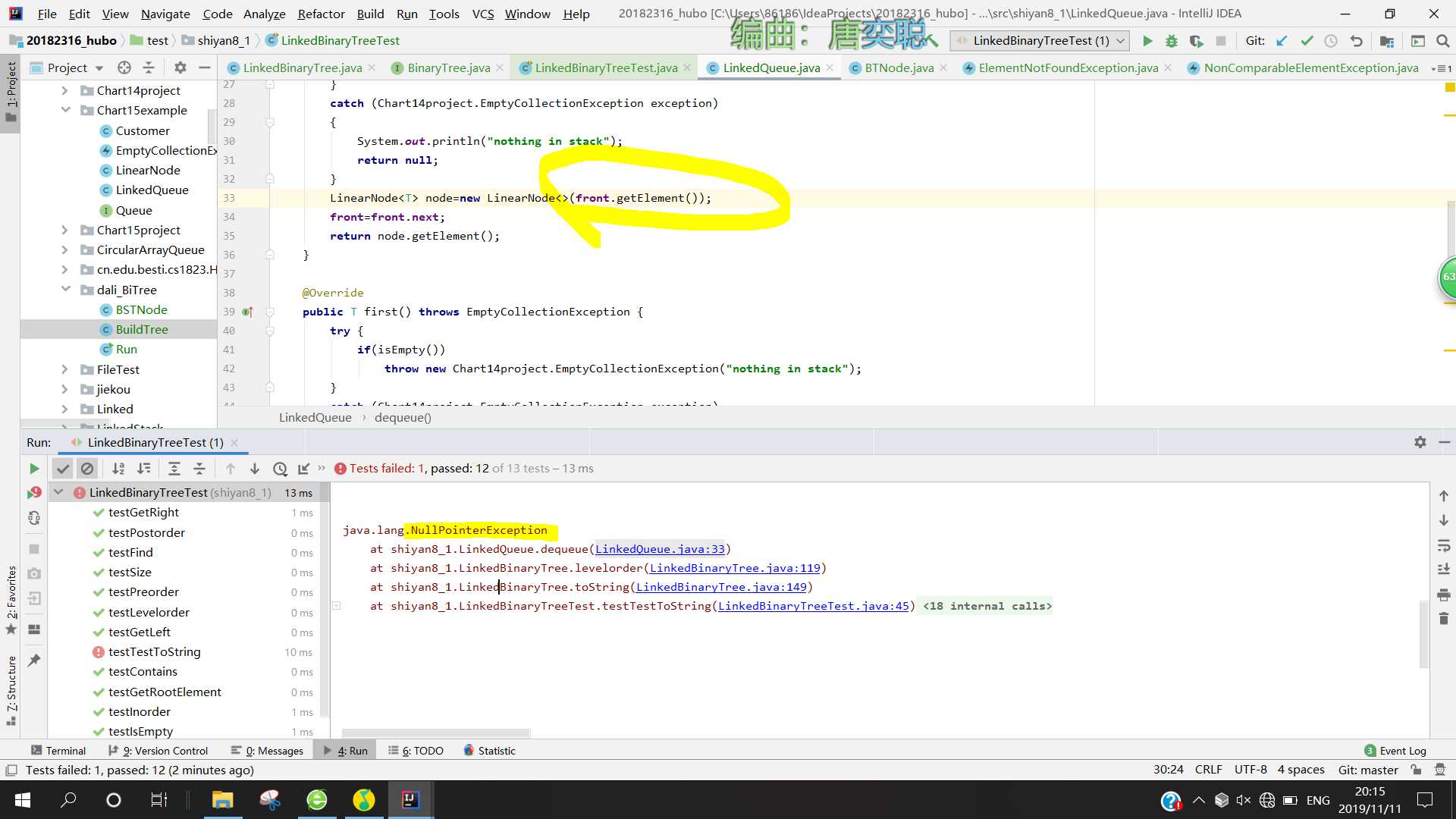
问题2:当我在调用队列头的数据时,出现了空指针报错
1.In removing an element from a binary search tree, another node must be ___________ to replace the node being removed.
A .duplicated
B .demoted
C .promoted
D .None of the above
正确答案: C 我的答案: B
教材学习中的问题和解决过程(2分)
代码调试中的问题和解决过程(3分)
本周有效代码超过300分行的(加1分)
结对照片
结对学习内容
对上周及本周的考试内容进行了探讨,并通过上网查询等方式深入分析,直到将问题理解。
一起制作博客,markdown,遇到问题相互询问,并解决。
| 代码行数(实际/预期) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 10000行 | |||
| 第一周 | 119/119 | 3/3 | 20/20 | |
| 第二周 | 302/300 | 2/5 | 25/45 | |
| 第三周 | 780/800 | 2/7 | 25/70 | |
| 第四周 | 1500/1300 | 2/9 | 25/95 | |
| 第五周 | 3068/2500 | 3/12 | 25/120 | |
| 第六周 | 4261/4000 | 2/14 | 25/145 | |
| 第七、八周 | 7133/7000 | 3/17 | 25/170 | |
| 第九周 | 10330/10000 | 3/20 | 25/195 |
计划学习时间:25小时
实际学习时间:25小时
标签:print 直接 rabl 顺序 基于 返回 参考资料 特殊 循环
原文地址:https://www.cnblogs.com/hp12138/p/11875747.html