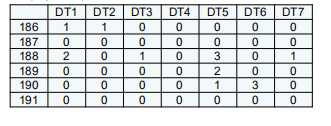
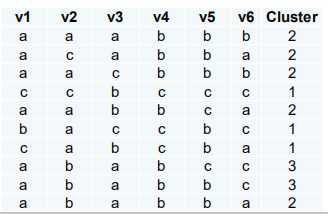
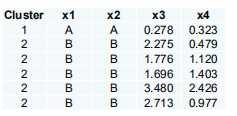
标签:个数 蓝色 适用于 自己的 预测 变换 连接 无法 分布
13聚类分析和判别分析
==================================
聚类分析
什么是聚类分析?
聚类:数据对象的集合
在同一集群内彼此相似
与其他集群中的对象不同
==================================
聚集分析
将一组数据对象分组为群集,即为分组
聚类是无监督的分类:没有预定义的类。
典型应用
作为了解数据分布的独立工具。
作为其它算法的预处理步骤
=================================
什么是好的聚类?
良好的聚类方法将产生高质量的簇,
簇类内相似性
簇类间相似性
聚类结果的质量取决于相似性度量,即相似性要求高聚类的质量就差。
聚类方法的质量也通过它发现一些或全部隐藏模式的能力来测量,即是否在组中发现隐藏模式如果有隐藏模式则聚类效果差。
====================================
测度聚类质量
不同/相似度量:相似性用距离函数表示,距离函数通常是度量:d(i,j)
对于布尔变量、范畴变量、序数变量、区间缩放变量和比率变量,距离函数的定义通常有很大的不同。
权重应该根据应用程序和数据语义与不同的变量相关联。
很难定义“足够相似”或“足够好”--答案通常是高度主观的。
聚类方法
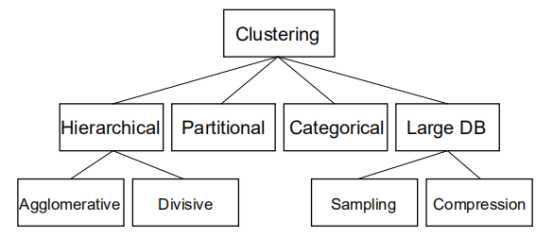
数据结构
数据矩阵
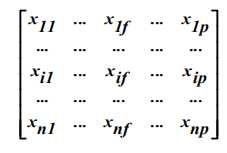
相异矩阵
==========================================
分区算法:基本概念
分区方法:将N个对象的数据库D的分区构造成一组K个簇
给定一个k,找到一个k簇的分区,以优化所选的分区准则。
全局最优:彻底枚举所有分区
启发式方法:K-mean和k-medoid算法
k-means:每个群集由群集的中心表示
K-medoid或PAM(围绕medoid的分区):每个集群由集群中的一个对象表示
==========================================
K-means聚类
基本思路:使用集群中心(表示)表示集群。
将数据元素分配给收敛集群(中心)
目标:尽量减少平方误差(类内差异)
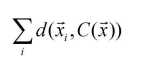
给定k,k-均值算法分四个步骤实现:
将对象划分为k个非空子集
计算种子点作为当前分区的群集的质心(质心为中心,即群集的平均点)
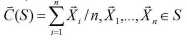
使用最近的种子点将每个对象分配给群集
回到步骤2,当不再有新的任务时停止
就是在已知要分为4类之后,将K=4,随便找到4个点,计算每个原始点的到这四个点中心的距离,选择距离最近的点归类,这就有4类点,再在这些点内部计算每一点的质心,这就有了新的4个点,再对所有点计算到这四个点的距离,然后比较,以此类推。
================================
流程:
初始化1
指定组k的数目:
例如,k=4
选择4个点(随机)
每个点根据4个距离分配到最近的集群。
迭代直到装置收敛
============================================
关于k-means方法的评述
优点:相对高效:O(TKN),其中n是#对象,k是#集群,t是#迭代。通常,k,t<n
注释:通常以局部最佳状态终止。
全局最优的方法包括:确定性退火和遗传算法。
缺点:
仅在均值被定义时才适用,而不适用于分类数据。
需要预先指定k,集群的数目。
无法处理噪声数据和异常值。
不适合发现具有非凸形状的簇
=================================================
处理数值数据的方法:k-means
类似于K的聚类方法
一些不同于K-means算法的不同在于
对于原始K-means值的选择
不同计算
计算集群均值的策略
处理分类数据:K-modes
用模式替换均值
使用新的不同的措施来处理分类对象。
使用基于频率的方法来更新群集模式
分类数据和数值数据的混合:K-prototype
===========================================
K-medoid聚类方法
在集群中找到有代表性的对象,称为medoid。
PAM围绕MeDOID进行分区
使用真实对象代表群集,
任意选择k表示对象
对于每对非选定的对象h和选定的对象i,计算总交换成本TCIDH。
对于每对i和h,
如果TCIDH<0,则将I替换为H
然后将每个非选定对象分配给最相似的具有代表性的对象。
重复步骤2-3,直到没有变化
即若K=2,则选择原始数据中的某两个点作为原始medoids,计算每个点到该点的距离,形成两个簇,再选择一个非之前的点作为medoid,如果花费得到改善则将medoid值替换为改点,如果没有得到改善则不变。
从一组初始的medoid开始,如果它改善了所产生的聚类的总距离,则迭代地将其中一个medoid替换为非medoid之一。
PAM有效地适用于小型数据集,但对于大型数据集,PAM不能很好地进行扩展。
CLARA
CLARANS:随机抽样
===========================================
对PAM的评论
在存在噪声和异常值的情况下,pam比k均值更健壮,因为Medoid受异常值或其他极值的影响小于k-means。
PAM有效地适用于小型数据集,但对于大型数据集,PAM不能很好地扩展。
因为迭代次数较多,每个迭代的O(k(n-k)2)。
其中n是数据的个数,k是簇的个数。
===========================================
CLARA集群大型应用程序
它绘制数据集的多个样本,对每个样本应用PAM,并给出最佳的聚类作为输出。
优点:处理比PAM更大的数据集。
劣势:效率取决于样本量。
-如果样本被偏置,则基于样本的良好聚类不一定代表整个数据集的良好聚类
即将原来的所有样本划分为更小单元,即单个样本来进行PAM
=======================================
分层群聚
使用距离矩阵作为聚类准则。此方法不需要将群集k的数目作为输入,而是需要一个终止条件。
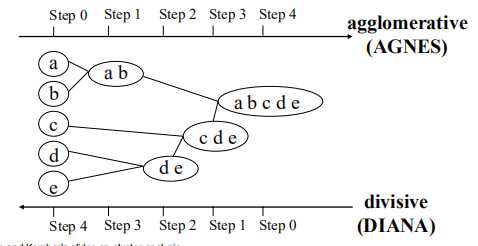
给定一组待聚类的项目和NxN距离(或相似度)矩阵,基本过程分层聚类是这样的:
就像哈弗曼树得到的过程一样。
========================================
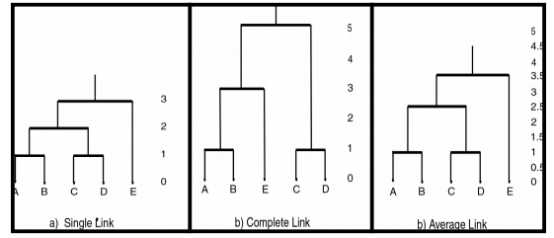
簇间距离
单点距离:点间最小距离
完全点距离:最大点间距离
平均点距离:点间平均距离
质心距离:质心距离
===============================
合并或连接规则-计算距离
================================
距离测量:明可夫斯基度规
假设两个对象(x和y)都有p个特性:
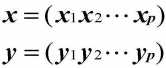
明可夫斯基度规为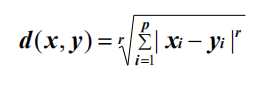
=====================================
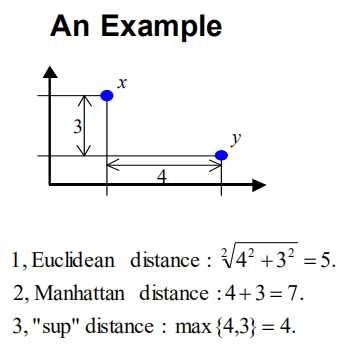
常用的Minkowski度量
R=2时是欧几里得距离:
R=1时是曼哈顿距离
R=正无穷是(“sup”距离),即数据集合中取最大值。
============================================
当所有特征都是二进制时,曼哈顿距离被称为Hamming距离。
17个条件下基因表达水平(1-高,0-低)

即二进制的01+10=11=5
=========================================
其他相似指数
权重距离: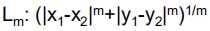
Sop距离: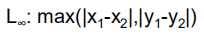
内积: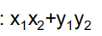
皮尔逊相关系数
斯皮尔曼等级相关系数
==========================================
系统树图
一种树数据结构,它说明了层次聚类技术。
每个级别显示该级别的群集
叶子-个体群集
根-一个群集
i级的群集是i+1级子群集的联盟
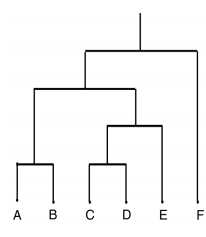
==========================================
聚类级别
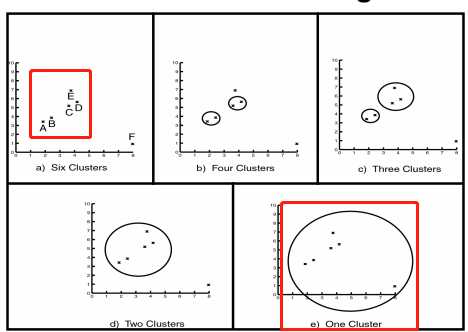
凝聚实例
首先计算各点之间的距离,然后将距离最小的相组合,以此类推,直到根节点。
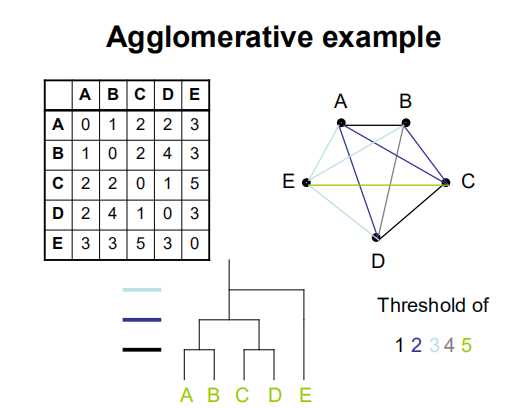
单链路、完全链接和平均链接群集
==========================================================
聚簇分析中的问题
大量的聚类算法
许多距离/相似性度量
哪种聚类算法运行得更快,使用的内存更少
到底有多少簇?
这些簇稳定吗?
这些集群(簇)有意义吗?
=======================================================
统计显着性检验不是一个典型的统计测试
聚类分析是不同算法的“集合”,“根据定义良好的相似性规则将对象放入聚类”。
聚类分析方法大多是在没有先验假设的情况下使用,但还处于探索阶段。
事实上,集群分析发现"最重要的解决方案是可能的。"
统计学显著性检验在此不合适,即使在报告p水平的情况下(如在K-均值聚类中)
========================================
判别分析,判别式分析DA
DA用于通过距离度量来标识对象组之间的边界。
例如:
一些昆虫属于什么种类,属于一些措施的基础。
某人是否有良好的信用风险?
学生应该被大学录取吗?
类似于回归,除了标准(或因变量)是分类变量的而不是连续变量的。
可替代地,判别式分析与(MANOVA)相反。
MANOVA:自变量是分类变量的,因变量是连续变量。
在Manova中,自变量是群(分类变量),因变量是连续测度。
在DA中,自变量是连续测度和因变量是团体(分类变量)。
===========================
DA的原始数据:
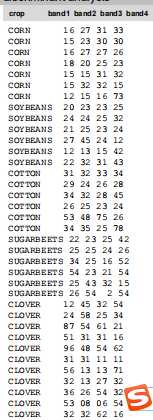
目的是让再来一个数据,据数据结构进行目录分类。
============================================
线性判别分析
线性判别分析试图找到最佳分离人口的选定措施的线性组合。

红色和蓝色即已经找到了划分方法。
程序:
判别函数分析分为两个步骤:
第一步骤在计算上与ManoVA相同。存在总方差-协方差矩阵;同样,存在集合内方差-协方差矩阵。
通过多元F检验对这两个矩阵进行比较,以确定组间是否存在显著差异(对于所有变量)。
首先进行多元检验,如果具有统计学意义,则继续查看哪一个变量在各组中具有显著不同的均值。
一旦发现组平均值具有统计学显著性,就进行变量分类。
判别分析自动确定变量的最优组合,从而使第一个函数提供最全面的变量组合。
群体间的区别,第二种提供第二全面,以此类推。
此外,这些职能将是独立的或正交的,也就是说,它们对群体之间的歧视的贡献不会重叠。
此外,这些函数将是独立的或正交的,也就是说,它们对群体之间的歧视的贡献不会重叠。
=========================================
假定前提
样本量:即薯竖条型变量。
可接受不同的样本尺寸。最小组的样本大小需要超过预测变量的数量。作为“经验法则”,最小的样本大小应该是 对于几个(4或5)的预测因子,至少会有20。自变量的最大数目是n-2,其中n是样本的大小.虽然这种低样本量可能有效,但不鼓励这样做,而且通常它最好是有4或5倍的观察和独立变量。
正态分布:
假设数据(对于变量)表示来自多元正态分布的样本。您可以检查变量是否通常分布有频率分布的直方图。 然而,请注意,违反正态假设并不是“致命的”,只要非正态是由偏斜而非异常引起的,则由此产生的显着性检验仍然是可靠的。
方差/协方差的同质性
判别分析对方差协方差矩阵的异质性非常敏感。在接受重要研究的最终结论之前,最好先回顾一下组内方差和相关矩阵。同步性通过散射图进行评估,并通过变量变换加以修正。
=================================================
极端值
判别分析对离群点的包含非常敏感。
运行每个组的单变量和多变量异常值的测试,并对其进行转换或消除。
如果一项研究中的一组包含影响平均值的极端离群值,则它们也会增加变异性。总体显着性测试基于集合方差,即所有组之间的平均方差。因此,相对较大的均值(具有较大的方差)的显着性检验将基于相对较小的集合方差,从而导致错误的统计显着性。即方差和均值都比实际情况要大。
非线性:
如果其中一个自变量与另一个独立变量高度相关,或者一个是其他独立变量的函数(例如和),那么矩阵就没有唯一的判别解。
在独立凹坑相关的程度上,标准化的鉴别函数系数将不能可靠地评估预测变量的相对重要性。既没有偏相关系数这一类的函数来评估。
============================================================
判别分析与聚类
判别分析:
已知的类数量
基于训练集
用于对未来的观测进行分类
分类是监督学习的一种形式
Y =X1 + X2 + X3
聚类:
未知类数
无先验知识
用于理解(探索)数据
聚类是一种无监督学习形式。
X1 + X2 + X3
标签:个数 蓝色 适用于 自己的 预测 变换 连接 无法 分布
原文地址:https://www.cnblogs.com/yuanjingnan/p/12025044.html