标签:join() work 参数 ext 同步 应用 mat spl 数据库
某个应用场景需要从数据库中取出几十万的数据时,需要对每个数据进行相应的操作。逐个数据处理过慢,于是考虑对数据进行分段线程处理:
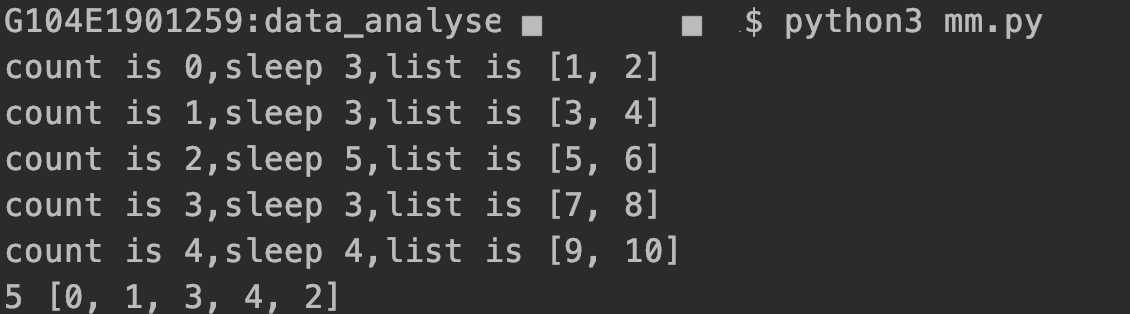
1 # -*- coding: utf-8 -*- 2 import math 3 import random 4 import time 5 from threading import Thread 6 7 _result_list = [] 8 9 10 def split_df(): 11 # 线程列表 12 thread_list = [] 13 # 需要处理的数据 14 _l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 15 # 每个线程处理的数据大小 16 split_count = 2 17 # 需要的线程个数 18 times = math.ceil(len(_l) / split_count) 19 count = 0 20 for item in range(times): 21 _list = _l[count: count + split_count] 22 # 线程相关处理 23 thread = Thread(target=work, args=(item, _list,)) 24 thread_list.append(thread) 25 # 在子线程中运行任务 26 thread.start() 27 count += split_count 28 29 # 线程同步,等待子线程结束任务,主线程再结束 30 for _item in thread_list: 31 _item.join() 32 33 34 def work(df, _list): 35 """ 36 每个线程执行的任务,让程序随机sleep几秒 37 :param df: 38 :param _list: 39 :return: 40 """ 41 sleep_time = random.randint(1, 5) 42 print(f‘count is {df},sleep {sleep_time},list is {_list}‘) 43 time.sleep(sleep_time) 44 _result_list.append(df) 45 46 47 if __name__ == ‘__main__‘: 48 split_df() 49 print(len(_result_list), _result_list)
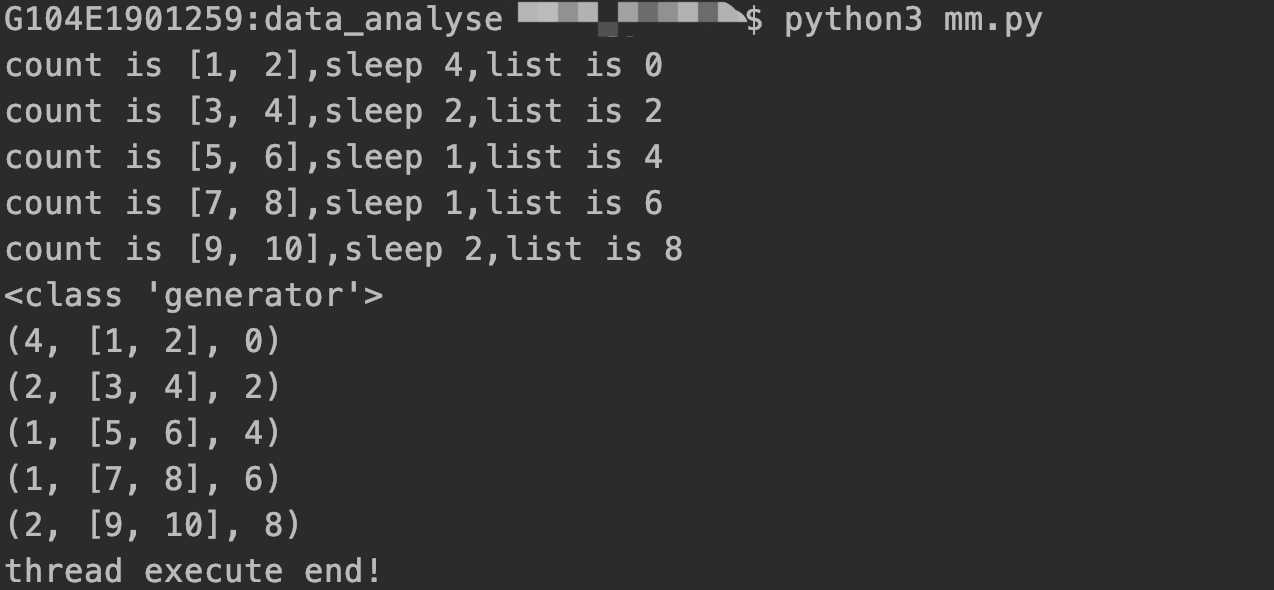
1 # -*- coding: utf-8 -*- 2 import math 3 import random 4 import time 5 from concurrent.futures import ThreadPoolExecutor 6 7 8 def split_list(): 9 # 线程列表 10 new_list = [] 11 count_list = [] 12 # 需要处理的数据 13 _l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] 14 # 每个线程处理的数据大小 15 split_count = 2 16 # 需要的线程个数 17 times = math.ceil(len(_l) / split_count) 18 count = 0 19 for item in range(times): 20 _list = _l[count: count + split_count] 21 new_list.append(_list) 22 count_list.append(count) 23 count += split_count 24 return new_list, count_list 25 26 27 def work(df, _list): 28 """ 线程执行的任务,让程序随机sleep几秒 29 :param df: 30 :param _list: 31 :return: 32 """ 33 sleep_time = random.randint(1, 5) 34 print(f‘count is {df},sleep {sleep_time},list is {_list}‘) 35 time.sleep(sleep_time) 36 return sleep_time, df, _list 37 38 39 def use(): 40 new_list, count_list = split_list() 41 with ThreadPoolExecutor(max_workers=len(count_list)) as t: 42 results = t.map(work, new_list, count_list) 43 44 # 或执行如下两行代码 45 # pool = ThreadPoolExecutor(max_workers=5) 46 # 使用map的优点是 每次调用回调函数的结果不用手动的放入结果list中 47 # results = pool.map(work, new_list, count_list) 48 49 # map返回一个迭代器,其中的回调函数的参数 最好是可以迭代的数据类型,如list;如果有 多个参数 则 多个参数的 数据长度相同; 50 # 如: pool.map(work,[[1,2],[3,4]],[0,1]]) 中 [1,2]对应0 ;[3,4]对应1 ;其实内部执行的函数为 work([1,2],0) ; work([3,4],1) 51 # map返回的结果 是 有序结果;是根据迭代函数执行顺序返回的结果 52 print(type(results)) 53 # 如下2行 会等待线程任务执行结束后 再执行其他代码 54 for ret in results: 55 print(ret) 56 print(‘thread execute end!‘) 57 58 59 if __name__ == ‘__main__‘: 60 use()
参考链接:https://www.cnblogs.com/rgcLOVEyaya/p/RGC_LOVE_YAYA_1103_3days.html
python多线程之threading、ThreadPoolExecutor.map
标签:join() work 参数 ext 同步 应用 mat spl 数据库
原文地址:https://www.cnblogs.com/sunshine-blog/p/12027606.html