标签:单节点 drop dev size tin 列表 服务器 网络环境 python
Prometheus 是由前 Google 工程师从 2012 年开始在 Soundcloud 以开源软件的形式进行研发的系统监控和告警工具包,自此以后,许多公司和组织都采用了 Prometheus 作为监控告警工具。Prometheus 的开发者和用户社区非常活跃,它现在是一个独立的开源项目,可以独立于任何公司进行维护。为了证明这一点,Prometheus 于 2016 年 5 月加入 CNCF 基金会,成为继 Kubernetes 之后的第二个 CNCF 托管项目。
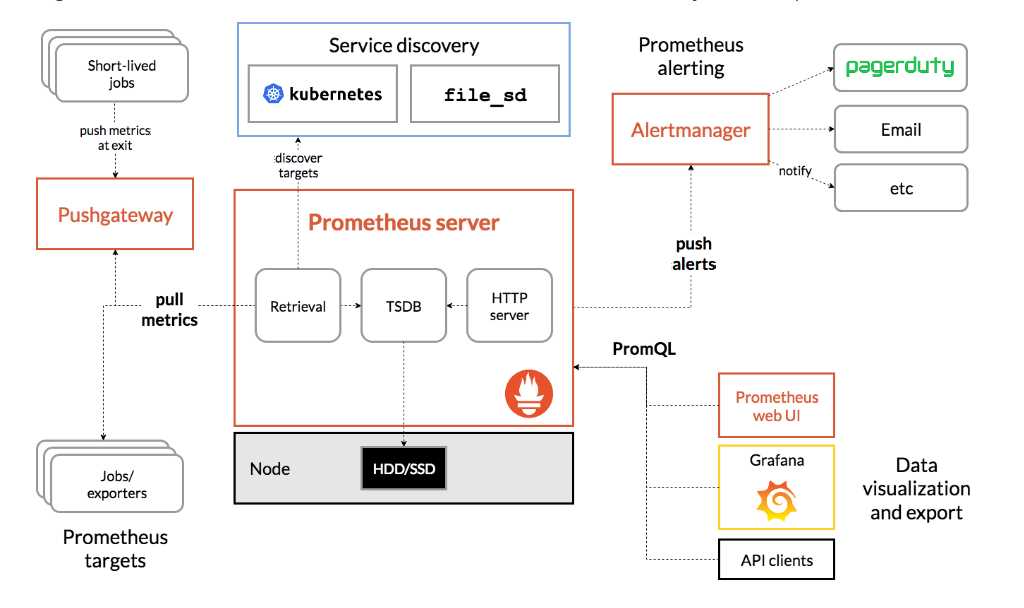
Prometheus Server 直接从监控目标中或者间接通过推送网关来拉取监控指标,它在本地存储所有抓取到的样本数据,并对此数据执行一系列规则,以汇总和记录现有数据的新时间序列或生成告警。可以通过 Grafana 或者其他工具来实现监控数据的可视化。
Prometheus的基本原理是通过HTTP协议周期性抓取被监控组件的状态,任意组件只要提供对应的HTTP接口就可以接入监控。不需要任何SDK或者其他的集成过程。这样做非常适合做虚拟化环境监控系统,比如VM、Docker、Kubernetes等。输出被监控组件信息的HTTP接口被叫做exporter 。目前互联网公司常用的组件大部分都有exporter可以直接使用,比如Varnish、Haproxy、Nginx、MySQL、Linux系统信息(包括磁盘、内存、CPU、网络等等)。
在Prometheus中,每一个暴露监控样本数据的HTTP服务称为一个实例。例如在当前主机上运行的node exporter可以被称为一个实例(Instance)。
负责数据的收集和存储,并且对外提供PromQL实现监控数据的查询以及聚合分析。
广义上讲所有可以向Prometheus提供监控样本数据的程序都可以被称为一个Exporter。而Exporter的一个实例称为target。Exporter将监控数据采集的端点通过HTTP服务的形式暴露给Prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
从间接采集的Exporter的来源上来讲,主要分为两类:
Prometheus社区提供了丰富的Exporter实现,涵盖了从基础设施,中间件以及网络等各个方面的监控功能。这些Exporter可以实现大部分通用的监控需求。下表列举一些社区中常用的Exporter:
|
范围 |
常用Exporter |
|
数据库 |
MySQL Exporter, Redis Exporter, MongoDB Exporter, MSSQL Exporter等 |
|
硬件 |
Apcupsd Exporter,IoT Edison Exporter, IPMI Exporter, Node Exporter等 |
|
消息队列 |
Beanstalkd Exporter, Kafka Exporter, NSQ Exporter, RabbitMQ Exporter等 |
|
存储 |
Ceph Exporter, Gluster Exporter, HDFS Exporter, ScaleIO Exporter等 |
|
HTTP服务 |
Apache Exporter, HAProxy Exporter, Nginx Exporter等 |
|
API服务 |
AWS ECS Exporter, Docker Cloud Exporter, Docker Hub Exporter, GitHub Exporter等 |
|
日志 |
Fluentd Exporter, Grok Exporter等 |
|
监控系统 |
Collectd Exporter, Graphite Exporter, InfluxDB Exporter, Nagios Exporter, SNMP Exporter等 |
|
其它 |
Blockbox Exporter, JIRA Exporter, Jenkins Exporter, Confluence Exporter等 |
除了直接使用社区提供的Exporter程序以外,用户还可以基于Prometheus提供的Client Library创建自己的Exporter程序,目前Promthues社区官方提供了对以下编程语言的支持:Go、Java/Scala、Python、Ruby。同时还有第三方实现的如:Bash、C++、Common Lisp、Erlang,、Haskeel、Lua、Node.js、PHP、Rust等。
顾名思义,用来生成自定义的exporters的java库。
由于Prometheus数据采集基于Pull模型进行设计,因此在网络环境的配置上必须要让Prometheus Server能够直接与Exporter进行通信。 当这种网络需求无法直接满足时(短周期或者临时采集的样本数据),就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
推送数据的方式:
1、API 方式 Push 数据到 PushGateway
2、用 Client SDK Push 数据到 Pushgateway
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
1. 由指标名称和和键/值对标签标识的时间序列数据组成的多维数据模型。
2. 强大的查询语言 PromQL。
3. 不依赖分布式存储;单个服务节点具有自治能力。
4. 时间序列数据是服务端通过 HTTP 协议主动拉取获得的。
5. 也可以通过中间网关来推送时间序列数据。
6. 可以通过静态配置文件或服务发现来获取监控目标。
7. 支持多种类型的图表和仪表盘。
引自官网:
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4中不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。Summary和Histogram的用法基本保持一致(主用用于统计和分析样本的分布情况),区别在于Summary可以指定在客户端统计的分位数。
Prometheus 适用于记录文本格式的时间序列,它既适用于以机器为中心的监控,也适用于高度动态的面向服务架构的监控。在微服务的世界中,它对多维数据收集和查询的支持有特殊优势。
Prometheus 是专为提高系统可靠性而设计的,它可以在断电期间快速诊断问题,每个 Prometheus Server 都是相互独立的,不依赖于网络存储或其他远程服务。当基础架构出现故障时,你可以通过 Prometheus 快速定位故障点,而且不会消耗大量的基础架构资源。
Prometheus 非常重视可靠性,即使在出现故障的情况下,你也可以随时查看有关系统的可用统计信息。如果你需要百分之百的准确度,例如按请求数量计费,那么 Prometheus 不太适合你,因为它收集的数据可能不够详细完整。这种情况下,你最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 来监控系统的其余部分。
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global ‘evaluation_interval‘.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it‘s Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: ‘prometheus‘
# metrics_path defaults to ‘/metrics‘
# scheme defaults to ‘http‘
static_configs:
- targets: [‘localhost:9090‘]
其中scrape_config包含一个或多个job(即job_name),每一个Job可以对应多个Instance,即配置文件中的targets. 通过Prometheus UI可以更直观的看到其中的关系。
Prometheus 2.x 采用自定义的存储格式将样本数据保存在本地磁盘当中。如下所示,按照两个小时(最少时间)为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
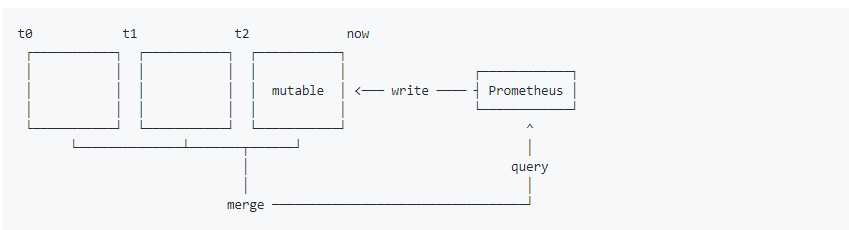
最新写入的数据保存在内存block中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
在文件系统中这些块保存在单独的目录当中,Prometheus保存块数据的目录结构如下所示:如上所示,Prometheus 2.x采用自定义的存储格式将样本数据保存在本地磁盘当中。按照两个小时为一个时间窗口,将两小时内产生的数据存储在一个块(Block)中,每一个块中包含该时间窗口内的所有样本数据(chunks),元数据文件(meta.json)以及索引文件(index)。
当前时间窗口内正在收集的样本数据,Prometheus则会直接将数据保存在内存当中。为了确保此期间如果Prometheus发生崩溃或者重启时能够恢复数据,Prometheus启动时会从写入日志(WAL)进行重播,从而恢复数据。此期间如果通过API删除时间序列,删除记录也会保存在单独的逻辑文件当中(tombstone)。
./data
|- 01BKGV7JBM69T2G1BGBGM6KB12 # 块
|- meta.json # 元数据
|- wal # 写入日志
|- 000002
|- 000001
|- 01BKGTZQ1SYQJTR4PB43C8PD98 # 块
|- meta.json #元数据
|- index # 索引文件
|- chunks # 样本数据
|- 000001
|- tombstones # 逻辑数据
|- 01BKGTZQ1HHWHV8FBJXW1Y3W0K
|- meta.json
|- wal
|-00000
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。而对于历史数据的删除,也变得非常简单,只要删除相应块所在的目录即可。
对于单节点的Prometheus而言,这种基于本地文件系统的存储方式能够让其支持数以百万的监控指标,每秒处理数十万的数据点。为了保持自身管理和部署的简单性,Prometheus放弃了管理HA的复杂度。
Prometheus的本地存储设计可以减少其自身运维和管理的复杂度,同时能够满足大部分用户监控规模的需求。但是本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展和迁移。
为了保持Prometheus的简单性,Prometheus并没有尝试在自身中解决以上问题,而是通过定义两个标准接口(remote_write/remote_read),让用户可以基于这两个接口对接将数据保存到任意第三方的存储服务中,这种方式在Promthues中称为Remote Storage。
用户可以在Prometheus配置文件中指定Remote Write(远程写)的URL地址,一旦设置了该配置项,Prometheus将采集到的样本数据通过HTTP的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。

如下图所示,Promthues的Remote Read(远程读)也通过了一个适配器实现。在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,ranges),Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。

当获取到样本数据后,Promthues在本地使用PromQL对样本数据进行二次处理。
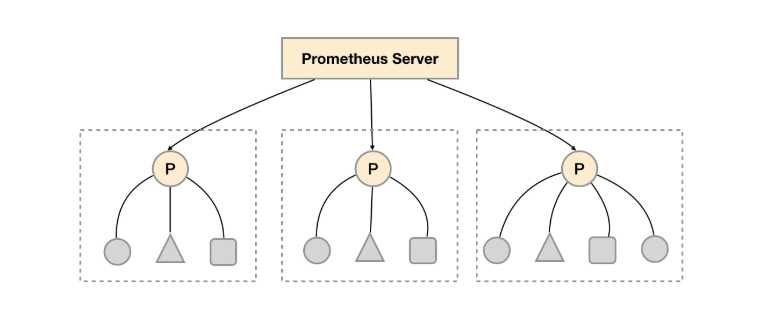
如下图所示,在每个数据中心部署单独的Prometheus Server,用于采集当前数据中心监控数据。并由一个中心的Prometheus Server负责聚合多个数据中心的监控数据。这一特性在Promthues中称为联邦集群。
基本的HA模式只能确保Promthues服务的可用性问题,但是不解决Prometheus Server之间的数据一致性问题以及持久化问题(数据丢失后无法恢复),也无法进行动态的扩展。因此这种部署方式适合监控规模不大,Promthues Server也不会频繁发生迁移的情况,并且只需要保存短周期监控数据的场景。
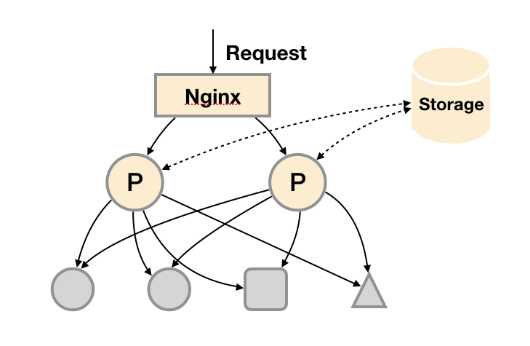
在解决了Promthues服务可用性的基础上,同时确保了数据的持久化,当Promthues Server发生宕机或者数据丢失的情况下,可以快速的恢复。 同时Promthues Server可能很好的进行迁移。因此,该方案适用于用户监控规模不大,但是希望能够将监控数据持久化,同时能够确保Promthues Server的可迁移性的场景。
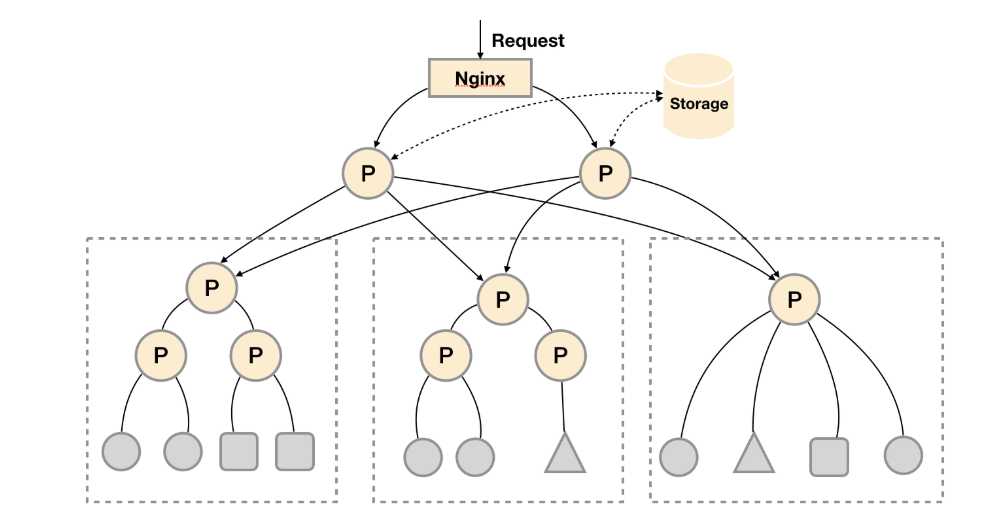
这种部署方式一般适用于两种场景:
场景一:单数据中心 + 大量的采集任务
这种场景下Promthues的性能瓶颈主要在于大量的采集任务,因此用户需要利用Prometheus联邦集群的特性,将不同类型的采集任务划分到不同的Promthues子服务中,从而实现功能分区。例如一个Promthues Server负责采集基础设施相关的监控指标,另外一个Prometheus Server负责采集应用监控指标。再有上层Prometheus Server实现对数据的汇聚。
场景二:多数据中心
这种模式也适合与多数据中心的情况,当Promthues Server无法直接与数据中心中的Exporter进行通讯时,在每一个数据中部署一个单独的Promthues Server负责当前数据中心的采集任务是一个不错的方式。这样可以避免用户进行大量的网络配置,只需要确保主Promthues Server实例能够与当前数据中心的Prometheus Server通讯即可。 中心Promthues Server负责实现对多数据中心数据的聚合。
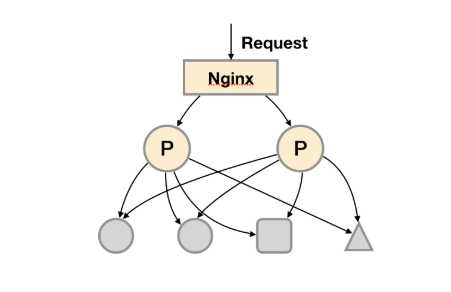
这时在考虑另外一种极端情况,即单个采集任务的Target数也变得非常巨大。这时简单通过联邦集群进行功能分区,Prometheus Server也无法有效处理时。这种情况只能考虑继续在实例级别进行功能划分。
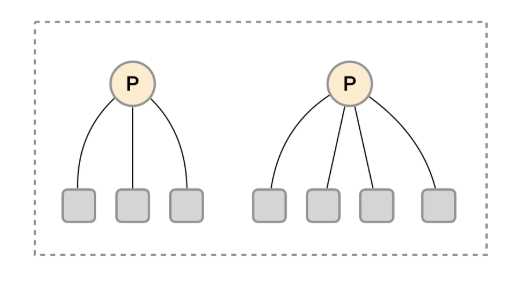
如上图所示,将统一任务的不同实例的监控数据采集任务划分到不同的Prometheus实例。通过relabel设置,我们可以确保当前Prometheus Server只收集当前采集任务的一部分实例的监控指标。
上面的部分,根据不同的场景演示了3种不同的高可用部署方案。当然对于Promthues部署方案需要用户根据监控规模以及自身的需求进行动态调整,下表展示了Promthues和高可用有关3个选项各自解决的问题,用户可以根据自己的需求灵活选择。
|
选项\需求 |
服务可用性 |
数据持久化 |
水平扩展 |
|
主备HA |
v |
x |
x |
|
远程存储 |
x |
v |
x |
|
联邦集群 |
x |
x |
v |
云原生、容器场景下按需的资源使用方式对于监控系统而言就意味着没有了一个固定的监控目标,所有的监控对象(基础设施、应用、服务)都在动态的变化,这对基于Push模式传统监控软件带来挑战。
对于Prometheus这一类基于Pull模式的监控系统,显然也无法继续使用的static_configs的方式静态的定义监控目标。而对于Prometheus而言其解决方案就是引入一个中间的代理人(服务注册中心),这个代理人掌握着当前所有监控目标的访问信息,Prometheus只需要向这个代理人询问有哪些监控目标控即可, 这种模式被称为服务发现。
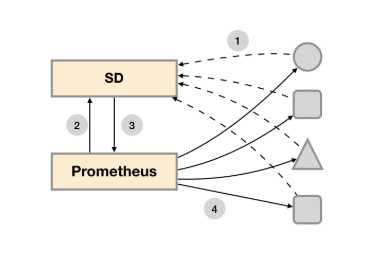
4.2基于文件的服务发现通过服务发现的方式,管理员可以在不重启Prometheus服务的情况下动态的发现需要监控的Target实例信息。
用户可以通过JSON或者YAML格式的文件,定义所有的监控目标。例如,在下面的JSON文件中分别定义了3个采集任务,以及每个任务对应的Target列表:
[
{
"targets": [ "localhost:8080"],
"labels": {
"env": "localhost",
"job": "cadvisor"
}
},
{
"targets": [ "localhost:9104" ],
"labels": {
"env": "prod",
"job": "mysqld"
}
},
{
"targets": [ "localhost:9100"],
"labels": {
"env": "prod",
"job": "node"
}
}
]
创建Prometheus配置文件/etc/prometheus/prometheus-file-sd.yml,并添加以下内容:
global:
scrape_interval: 15s
scrape_timeout: 10s
evaluation_interval: 15s
scrape_configs:
- job_name: ‘file_ds‘
file_sd_configs:
- refresh_interval: 1m
files:
- targets.json
通过这种方式,Prometheus会自动的周期性读取文件中的内容。当文件中定义的内容发生变化时,不需要对Prometheus进行任何的重启操作。
Consul是由HashiCorp开发的一个支持多数据中心的分布式服务发现和键值对存储服务的开源软件,被大量应用于基于微服务的软件架构当中。
Consul作为一个通用的服务发现和注册中心,记录并且管理了环境中所有服务的信息。Prometheus通过与Consul的交互可以获取到相应Exporter实例的访问信息。在Prometheus的配置文件当可以通过以下方式与Consul进行集成:
- job_name: node_exporter
metrics_path: /metrics
scheme: http
consul_sd_configs:
- server: localhost:8500 #指定了consul的访问地址
services: #为注册到consul中的实例信息
- node_exporter
- cadvisor
在consul_sd_configs定义当中通过server定义了Consul服务的访问地址,services则定义了当前需要发现哪些类型服务实例的信息,这里限定了只获取node_exporter和cadvisor的服务实例信息。
如何过滤选择Target实例?relabel
目前为止,只要是注册到Consul上的Node Exporter或者cAdvisor实例是可以自动添加到Prometheus的Target当中。现在请考虑下面的场景:
对于线上环境我们可能会划分为:dev, stage, prod不同的集群。每一个集群运行多个主机节点,每个服务器节点上运行一个Node Exporter实例。Node Exporter实例会自动测试到服务注册中心Consul服务当中,Prometheus会根据Consul返回的Node Exporter实例信息产生Target列表,并且向这些Target轮训数据。
然而,如果我们可能还需要:
1.需要按照不同的环境dev, stage, prod聚合监控数据?
2.对于研发团队而言,我可能只关心dev环境的监控数据?
3.为每一个团队单独搭建一个Prometheus Server? 如何让不同团队的Prometheus Server采集不同的环境监控数据?
Relabel可以在Prometheus采集数据之前,通过Target实例的Metadata信息,动态重新写入Label的值。除此之外,我们还能根据Target实例的Metadata信息选择是否采集或者忽略该Target实例。
在默认情况下,我们从所有环境的Node Exporter中采集到的主机指标如下:
|
1 |
node_cpu{cpu="cpu0",instance="172.21.0.3:9100",job="consul_sd",mode="guest"} |
基于Consul动态发现的Target实例,具有以下Metadata信息:
在Prometheus UI中,也可以直接查看target的metadata信息。
这里我们使用__meta_consul_dc信息来标记当前target所在的data center。并且通过regex来匹配source_label的值,使用replacement来选择regex表达式匹配到的mach group。通过action来告诉prometheus在采集数据之前,需要将replacement的内容写入到target_label dc当中
|
1 |
scrape_configs: |
对于直接保留标签的值时,也可以简化为:
|
1 |
- source_labels: ["__meta_consul_dc"] |
查询Prometheus查询监控数据,所有metrics都被写入了所在的数据中心标签dc
|
1 |
node_cpu{cpu="cpu0",dc="dc1",instance="172.21.0.6:9100",job="consul_sd",mode="guest"} 0 |
当需要过滤target目标时,我们则将action定义为keep或者drop。在Job的配置当中使用一下配置,当匹配到target的元数据标签__meta_consul_tags中匹配到”.,development,.“,则keep当前实例。
relabel_configs:
- source_labels: ["__meta_consul_tags"]
regex: ".*,development,.*"
action: keep
总结:
通过relabeling可以在写入metrics数据之前,动态修改metrics的label;
通过relabeling可以对target实例进行过滤和选择。
标签:单节点 drop dev size tin 列表 服务器 网络环境 python
原文地址:https://www.cnblogs.com/chenmingming0225/p/12072149.html