标签:obj 数据库数据 cut 移动 抽样 profile ORC 浮点型 位置
facebook的数据仓库计算框架,后来开源给了Apache
主要做离线计算即就是不要求实时获取结果
数据库一般分为:OLAP OLTP
就是通过以往的数据分析,对现在的业务或者发展发现提供数据的支持
就是从历史数据中心发掘价值
一般有一下几种模式
星型模式--雪花模型--星系模型
数据仓库基本用来数据的查询或者统计,基本上不会删除或者修改
hive是一个基于Hadoop的数据仓库工具;偏重于数据的分析和处理;Hbase查询数据,那么数据必须已经被存入到hbase数据库;Hive使用的是映射关系,可以将结构化的数据映射成一张表;
命令行模式
JDBC/ODBC模式 Thrift
WebUI
元数据信息:Hive的建表语句(描述Hive与数据映射关系的语句);包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录.
元数据信息会存放在关系型数据库中(推荐Mysql)
解析器:将hql(Hive Sql)语句解析成语法树
编译器:将语法树转成为逻辑执行计划
优化器:优化逻辑执行计划
执行器:将逻辑执行计划转化成为物理执行计划(MR JOB)
Hadoop-Yarn+Mapredce+Hdfs
基于MySQL和Hadoop环境下
为Mysql数据库添加一个库create database hive;
将HIVE上传到linux,解压拷贝并修改名称
ar -zxvf apache-hive-1.2.1-bin.tar.gz
cp -r apache-hive-1.2.1-bin /opt/sxt/
mv apache-hive-1.2.1-bin hive-1.2.1
修改配置文件
复制hive-default.xml.template并修改名称为hive-site.xml
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
//数据库名称
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive_single</value>
</property>
//是否运用本地数据库
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
//本地连接端口
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_single?createDatabaseIfNotExist=true</value>
</property>
//MySQL驱动包
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
//账户名称
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
//账户密码
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
上传mysql-connector-java-5.1.32-bin.jar
拷贝Mysql的mysql-connector-java-5.1.32-bin.jar包到hive的lib文件夹下
解决Hadoop与Hive的jar版本差异
cd /opt/sxt/hadoop-2.6.5/share/hadoop/yarn/lib/
rm -rf jline-0.9.94.jar
cp /opt/sxt/hive-1.2.1/lib/jline-2.12.jar ./
配置环境变量
vim /etc/profile //添加HIVE_HOME和PATH
source /etc/profile
启动
hive
查看拥有的表
show databases;
创建表
int tinyint(相当于byte) smallint(相当于short) bigint(相当于long)
float double
Boolean
string char(定长) varchar(变长)
timestamp date
优点类似于容器,便于我们操作数据
复合类型可以和复合类型相互嵌套
存放相同的数据类型
数据按照索引进行查找,索引默认从0开始
一组键值对,通过key可以访问到value
key不能相同,相同的key会相互覆盖
定义对象的属性,结构体的属性都是固定的
通过属性获取值,例如:user.uname
任何整数类型都可以隐式地转换为一个范围更广的类型
所有整数类型、FLOAT和STRING类型都可以隐式地转换成DOUBLE。
TINYINT、SMALLINT、INT都可以转换为FLOAT。
BOOLEAN类型不可以转换为任何其它的类型。
在设计表的时候,尽量将数据类型设置为合适的类型
防止以后操作中没必要的麻烦
库,表,字段等命名要注意命名规范
执行数据库组件的定义(创建,修改,删除)功能
执行任何的hivesql语句在语句末尾都要加上分号(;)
每创建一张表都会在HDFS文件系统中创建一个目录
create database if not exists sxt;-->if not exists 判断表是否存在
创建数据库并制定存放位置
create database 表名 location 指定的路径
create database sxt location ‘/hive_singe/sxt_pudong‘;
drop database if exists sxt;-->if exists 判断表是否存在
如果当前库不为空,级联删除
drop database if exists sxt cascade;
数据库的其他元数据信息都是不可更改的
数据库名
数据库所在的目录位置。
alter database sxt set dbproperties(‘createtime‘=‘20170830‘);
show databases;
show databases like ‘s*‘;-->模糊匹配
desc database shsxt;
use shsxt;
表的创建方式:表示对数据的映射,所以表示根据数据来设计的.
创建表写语句的时候,千万不要出现tab键,会出现乱码
创建数据文件,上传到Linux
创建userinfo表,会在数据库的文件夹中创建一个表名文件夹
将数据载入到表中
1,admin,00000
2,sxtly,11111
3,sxtyw,22222
4,sxtls,33333
create table userinfo(
id int,
uname string,
password string
)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘;
load data local inpath ‘/root/userinfo.txt‘ overwrite into table userinfo;
select * from userinfo
select id from userinfo where id = 2;
select * from userinfo limit 3;-->查询前三列数据
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
(col_name data_type [COMMENT col_comment], ...)
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[CLUSTERED BY (col_name, col_name, ...) ]
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format]
[STORED AS file_format]
[LOCATION hdfs_path]
CREATE
关键字,创建表
[EXTERNAL]
表的类型,内部表还是外部表
TABLE
创建的类型
[IF NOT EXISTS]
判断这个表是否存在
table_name
表名,要遵循命名规则
(col_name data_type [COMMENT col_comment], ...)
定义一个列 (列名1 数据类型1,列名2 数据类型1)
列与列之间用逗号隔开,最后一个列不需要加,
[COMMENT table_comment]
表的注释信息
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
创建分区表
[CLUSTERED BY (col_name, col_name, ...)
分桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
分桶
[ROW FORMAT row_format]
每一行数据切分的格式
[STORED AS file_format]
数据存放的格式
[LOCATION hdfs_path]
数据文件的地址
修改表的时候文件夹也会修改名字
ALTER TABLE person RENAME TO sxtperson;
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name];
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...);
desc table_name;
DROP TABLE [IF EXISTS] table_name;
{
"name": "songsong",
"friends": ["bingbing" , "lili"] , //列表Array,
"children": { //键值Map,
"xiao song": 18 ,
"xiaoxiao song": 19
}
"address": { //结构Struct,
"street": "hui long guan" ,
"city": "beijing"
}
}
?
songsong,bingbing_lili,xiao song:18_xiaoxiao song:19,hui long guan_beijing
yangyang,caicai_susu,xiao yang:18_xiaoxiao yang:19,chao yang_beijing
create table person(
name string,
friends array<string>,
children map<string,int>,
address struct<street:string,city:string>
)
row format delimited fields terminated by ‘,‘
collection items terminated by ‘_‘
map keys terminated by ‘:‘
lines terminated by ‘\n‘;
select friends[0],children[‘xiao song‘],address.street from person;
1,zshang,18,game-girl-book,stu_addr:beijing-work_addr:shanghai
2,lishi,16,shop-boy-book,stu_addr:hunan-work_addr:shanghai
3,wang2mazi,20,fangniu-eat,stu_addr:shanghai-work_addr:tianjing
create table sxtuser(
id int,
name string,
age int,
fav array<string>,
addr struct<stu_addr:string,work_addr:string>
)
row format delimited fields terminated by ‘,‘
collection items terminated by ‘-‘
map keys terminated by ‘:‘
lines terminated by ‘\n‘;
select friends[0],children[‘xiao song‘],address.street from person;
数据一旦被导入就不可以被修改-->数据会被存放到HDFS上,HDFS不支持数据的修改
load data [local] inpath ‘/opt/module/datas/student.txt‘ overwrite | into table student [partition (partcol1=val1,…)];
load data 固定语法 [local] :如果有local说明分析本地数据,如果去掉local说明分析hdfs上的数据 inpath ‘/opt/module/datas/student.txt‘ 导入数据的路径 overwrite 新导入的数据覆盖以前的数据 into table student 导入到那张表中
load data local inpath ‘/root/sxtuser666.txt‘ into table sxtuser;
load data local inpath ‘/root/sxtuser666.txt‘ overwrite into table sxtuser;
上传xx路径下的xx文件到xx表的文件中
load data inpath ‘/shsxt/hive/sxtuser666.txt‘ into table sxtuser;
load data inpath ‘/shsxt/hive/sxtuser666.txt‘ overwrite into table sxtuser;
上传xx路径下的xx文件到xx表的文件中
不管数据文件在哪,只要是内部表,数据文件都会拷贝一份到数据库表的文件夹中
如果是追加拷贝,查询数据的时候会查询所有的数据文件
1,admin
2,zs
3,ls
4,ww
?
create table t1(
id string,
name string
)
row format delimited fields terminated by ‘,‘
lines terminated by ‘\n‘;
?
load data local inpath ‘/root/t1.txt‘ into table t1;
?
create table t2(
name string
);
//会开启Mapreduce任务
insert overwrite table t2 select name from t1;
//在上面数据的基础上
create table t3(
id string
);
?
//会开启Mapreduce任务
from t1
INSERT OVERWRITE TABLE t2 SELECT name
INSERT OVERWRITE TABLE t3 SELECT id ;
insert into t1 values (‘id‘,‘5‘),(‘name‘,‘zhangwuji‘);
一般处理自己独享的数据,防止别人的误删除;删除表的时候,会一起将数据文件删除内部表不适合和其他工具共享数据。
可以和别的表共享数据;删除表的时候,不会将数据文件删除
create EXTERNAL table sxtuser_ex(
id int,
name string,
age int,
fav array<string>,
addr struct<stu_addr:string,work_addr:string>
)
row format delimited fields terminated by ‘,‘
collection items terminated by ‘-‘
map keys terminated by ‘:‘
lines terminated by ‘\n‘;
?
//加载本地文件到外部表,文件会保存到表文件夹
load data local inpath ‘/root/sxtuser666.txt‘ into table sxtuser_ex;
//加载HDFS到外部表,依然会并拷贝一份到表文件夹
load data inpath ‘/shsxt/ex/sxtuser666.txt‘ into table sxtuser_ex;
为了数据的共享,可以将外部表地址直接设置到数据地址
create EXTERNAL table sxtuser_ex_location(
id int,
name string,
age int,
fav array<string>,
addr struct<stu_addr:string,work_addr:string>
)
row format delimited fields terminated by ‘,‘
collection items terminated by ‘-‘
map keys terminated by ‘:‘
lines terminated by ‘\n‘
location ‘/shsxt/ex‘;
外部表与内部表的切换(内-->外)
alter table sxtuser set tblproperties(‘EXTERNAL‘=‘TRUE‘);
alter table sxtuser set tblproperties(‘EXTERNAL‘=‘FALSE‘);
修改表数据的存放地址
创建表的时候,会预先清空改文件夹中所有的数据
create table sxtuserpath111(
id int,
name string,
age int,
fav array<string>,
addr struct<stu_addr:string,work_addr:string>
)
row format delimited fields terminated by ‘,‘
collection items terminated by ‘-‘
map keys terminated by ‘:‘
lines terminated by ‘\n‘
location ‘/shsxt/ex‘;
location ‘/shsxt/ex‘;设置表的存放地址
1.将查询的结果导出到本地
insert overwrite local directory ‘/root/t11‘ select * from t1;
2.将查询的结果格式化导出到本地
insert overwrite local directory ‘/root/t12‘
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘ select * from t1;
3.将查询的结果导出到HDFS上
insert overwrite local directory ‘/shsxt/t13‘ select * from t1;
4.使用export/import导出数据
export table t1 to ‘/shsxt/hive/t1‘;
import from ‘/shsxt/hive/t1‘;
当我们创建表的时候,会创建对应的文件目录,如果我们load数据
所有的数据都会存放到这个目录
对表进行查询,默认查询这个表下的所有的文件
随着时间的推移,数据量的增长,查询的时间会越来越长
分区表的最主要目标就是减少每次扫描文件夹的范围
ALTER TABLE t_user ADD PARTITION (addr=‘gz‘);
ALTER TABLE t_user DROP PARTITION (addr=‘sh‘);
当我们删除分区,分区中的子分区和数据也会被全部删除
show partitions t_user;
单分区:只有一类分区
多分区:有两类分区,这两类分区是父子关系;1包含2分区
静态分区:手动指定分区;载入数据的时候,需要手动指定数据属于哪个分区 load方式
动态分区:自动识别分区;通过临时表插入数据,插入数据时会动态的创建分区文件夹
1,admin1,123456,bj
2,admin2,123456,bj
3,admin3,123456,bj
?
4,shsxt4,123456,sh
5,shsxt5,123456,sh
6,shsxt6,123456,sh
?
7,shsxt7,123456,sh
8,shsxt8,123456,sh
9,shsxt9,123456,sh
create table t_user(
id int,
uname string,
password string
)
partitioned by (addr string)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘;
?
//将数据载入到表中
load data local inpath ‘/root/t_user1‘ into table t_user partition (addr=‘bj‘);
load data local inpath ‘/root/t_user2‘ into table t_user partition (addr=‘sh‘);
//即使分区数据和具体数据不一致,默认使用数据分区信息
load data local inpath ‘/root/t_user3‘ into table t_user partition (addr=‘sh‘);
?
//查询数据
select * from t_user where addr=‘bj‘;
额外举例
1,linghuchong,xajh,huashan
2,yuelingshan,xajh,huashan
3,zhangwuji,yttlj,wudang
4,zhangcuishan,yttlj,wudang
5,zhangsanfeng,yttlj,wudang
6,duanziyu,jyjy,huashan
7,fengqingyang,jsfqy,huashan
8,zhangsanfeng,jsfqy,wudang
?
//建立多分区 小说--门派
?
//开启动态分区
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
//创建表
create table t_rw(
id int,
name string
)
partitioned by (novel string,sect string)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘;
?
//不能load数据,load数据还是静态分区,创建一张临时表,辅助导入数据
create EXTERNAL table t_rw_tmp(
id int,
name string,
novel string,
sect string
)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘
location ‘/shsxt/t_rw‘;
?
//将临时表的数据插入到动态多分区表
insert overwrite table t_rw partition(novel,sect) select id,name,novel,sect from t_rw_tmp;
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.css HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /tomcat.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
//创建表
CREATE TABLE logtbl (
host STRING,
identity STRING,
t_user STRING,
time STRING,
request STRING,
referer STRING,
agent STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.RegexSerDe‘
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
//将数据导入到表中
load data inpath ‘/shsxt/access/accessLog.txt‘ into table logtbl;
?
//解析数据
select * from logtbl;
select host from logtbl;
SQL注意点:
SQL 语言大小写不敏感。 SQL 可以写在一行或者多行;关键字不能被缩写也不能分行;各子句一般要分行写。
组函数与单行函数
max min avg sum count
nvl(obj,default) --> obj==null?default:obj
Hive SQL的使用和数据库SQL基本上是一样的
101,scott,10
102,smith,20
103,tom,20
104,kitty,10
?
10,sale
20,java
30,python
?
?
create table t_emp(
empno int,
ename string,
deptno int
)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘;
?
create table t_dept(
deptno int,
dname string
)
row format delimited fields terminated by ‘,‘ lines terminated by ‘\n‘;
?
?
//将数据加载到表
load data inpath ‘/shsxt/dql/emp.txt‘ into table t_emp;
load data inpath ‘/shsxt/dql/dept.txt‘ into table t_dept;
?
//开始查询
select * from t_emp;
select * from t_dept;
?
//查询每个员工对应的部门名称
select e.ename,d.dname from t_emp e,t_dept d where e.deptno = d.deptno;
----原生MapReduce解决思路
10 scott:0
10 smith:0
10 sale:1
list.add(scott,smith)
deptname = sale
sale:scott
sale:smith
?
//计算每个部门的员工总数
select e.deptno,count(e.empno) from t_emp e group by e.deptno;
--92等值
select d.dname,count(e.empno)
from t_emp e ,t_dept d
where e.deptno = d.deptno
group by d.dname;
--99等值
select d.dname,count(e.empno)
from t_emp e join t_dept d on(e.deptno = d.deptno)
group by d.dname;
--99外连接
select d.dname,count(e.empno)
from t_emp e right join t_dept d on(e.deptno = d.deptno)
group by d.dname
order by count(e.empno);
nezha js,gx,qq,dm
meirenyu gx,kh,aq
xingjidazhan kh,js
huoyingrenzhe dm,qj,yq,aq
?
create table t_movie(
name string,
type string
)
row format delimited fields terminated by ‘ ‘ lines terminated by ‘\n‘;
?
load data inpath ‘/shsxt/movie/movie.txt‘ into table t_movie;
?
//查看惊悚片
select * from t_movie where type like ‘%js%‘;
?
select name,split(type,‘,‘) from t_movie;
select explode(split(type,‘,‘)) from t_movie;
--语法错误
select name,explode(split(type,‘,‘)) from t_movie;
?
select name,c1 from t_movie
LATERAL VIEW explode(split(type,‘,‘)) typeTable AS c1;
都是为了提升我们查询数据的速度
分桶非常类似于MapReduce的分区操作(计算key的hash值,然后根据reduce的数量取余)
对数据进行再一次的划分,计算列的hash值,然后对桶的数量取余,计算出数据在桶的位置
相对而言桶里面的数据是比较均匀的----数据抽样 1000G ---> 1/1000 1G
分桶就是对列值取hash(什么列?)
经常被查询的列,或者散列比较好的列
对于hive中每一个表、分区都可以进一步进行分桶
桶数尽量能拥有更多的公约数 12
操作流程:创建表-->导入数据-->开启分桶-->创建分桶表-->将表的数据导入分桶表-->操作数据
1,tom,11
2,cat,22
3,dog,11
4,hive,44
5,hbase,11
6,mr,66
7,alice,11
8,scala,88
?
//开启分桶模式
set hive.enforce.bucketing=true;
?
//创建表普通表
CREATE TABLE t_psn(
id INT,
name STRING,
age INT
)ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘;
//创建分桶表
CREATE TABLE t_psnbucket(
id INT,
name STRING,
age INT
)CLUSTERED BY (name) SORTED BY (name) INTO 6 BUCKETS
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘;
?
//载入数据
load data inpath ‘/shsxt/psn/psn.txt‘ into table t_psn;
insert into table t_psnbucket select id, name, age from t_psn;
?
//对数据取样查询
select * from t_psnbucket tablesample(bucket 1 out of 6 on name);
x必须小于等于y
y必须是桶数的整约数(6--1236)
x 1 y 3-->将桶分为三个一组,取出每组中的第一个,共取出2桶数据
x 2 y 2-->将桶分为两个一组,取出每组中的第二个,共取出3桶数据
x 1 y 6
x1y1
x2y3
Mr. and Mrs. Dursley, of number four, Privet Drive, were proud to say that they were perfectly normal, thank you very much. They were the last people you‘d expect to be involved in anything strange or mysterious, because they just didn‘t hold with such nonsense.
?
Mr. Dursley was the director of a firm called Grunnings, which made drills. He was a big, beefy man with hardly any neck, although he did have a very large mustache. Mrs. Dursley was thin and blonde and had nearly twice the usual amount of neck, which came in very useful as she spent so much of her time craning over garden fences, spying on the neighbors. The Dursleys had a small son called Dudley and in their opinion there was no finer boy anywhere.
?
The Dursleys had everything they wanted, but they also had a secret, and their greatest fear was that somebody would discover it. They didn‘t think they could bear it if anyone found out about the Potters. Mrs. Potter was Mrs. Dursley‘s sister, but they hadn‘t met for several years; in fact, Mrs. Dursley pretended she didn‘t have a sister, because her sister and her good-for-nothing husband were as unDursleyish as it was possible to be. The Dursleys shuddered to think what the neighbors would say if the Potters arrived in the street. The Dursleys knew that the Potters had a small son, too, but they had never even seen him. This boy was another good reason for keeping the Potters away; they didn‘t want Dudley mixing with a child like that.When Mr. and Mrs. Dursley woke up on the dull, gray Tuesday our story starts, there was nothing about the cloudy sky outside to suggest that strange and mysterious things would soon be happening all over the country. Mr. Dursley hummed as he picked out his most boring tie for work, and Mrs. Dursley gossiped away happily as she wrestled a screaming Dudley into his high chair.
?
None of them noticed a large, tawny owl flutter past the window.
?
At half past eight, Mr. Dursley picked up his briefcase, pecked Mrs. Dursley on the cheek, and tried to kiss Dudley good-bye but missed, because Dudley was now having a tantrum and throwing his cereal at the walls.
?
“Little tyke,” chortled Mr. Dursley as he left the house. He got into his car and backed out of number four‘s drive.
?
It was on the corner of the street that he noticed the first sign of something peculiar — a cat reading a map. For a second, Mr. Dursley didn‘t realize what he had seen — then he jerked his head around to look again. There was a tabby cat standing on the corner of Privet Drive, but there wasn‘t a map in sight. What could he have been thinking of? It must have been a trick of the light. Mr. Dursley blinked and stared at the cat. It stared back. As Mr. Dursley drove around the corner and up the road, he watched the cat in his mirror. It was now reading the sign that said Privet Drive — no, looking at the sign; cats couldn‘t read maps or signs. Mr. Dursley gave himself a little shake and put the cat out of his mind. As he drove toward town he thought of nothing except a large order of drills he was hoping to get that day.
?
But on the edge of town, drills were driven out of his mind by something else. As he sat in the usual morning traffic jam, he couldn‘t help noticing that there seemed to be a lot of strangely dressed people about. People in cloaks. Mr. Dursley couldn‘t bear people who dressed in funny clothes — the getups you saw on young people! He supposed this was some stupid new fashion. He drummed his fingers on the steering wheel and his eyes fell on a huddle of these weirdos standing quite close by. They were whispering excitedly together. Mr. Dursley was enraged to see that a couple of them weren‘t young at all; why, that man had to be older than he was, and wearing an emerald-green cloak! The nerve of him! But then it struck Mr. Dursley that this was probably some silly stunt — these people were obviously collecting for something… yes, that would be it. The traffic moved on and a few minutes later, Mr. Dursley arrived in the Grunnings parking lot, his mind back on drills.
?
Mr. Dursley always sat with his back to the window in his office on the ninth floor. If he hadn‘t, he might have found it harder to concentrate on drills that morning. He didn‘t see the owls swooping past in broad daylight, though people down in the street did; they pointed and gazed open-mouthed as owl after owl sped overhead. Most of them had never seen an owl even at nighttime. Mr. Dursley, however, had a perfectly normal, owl-free morning. He yelled at five different people. He made several important telephone calls and shouted a bit more. He was in a very good mood until lunchtime, when he thought he‘d stretch his legs and walk across the road to buy himself a bun from the bakery.
?
He‘d forgotten all about the people in cloaks until he passed a group of them next to the baker‘s. He eyed them angrily as he passed. He didn‘t know why, but they made him uneasy. This bunch were whispering excitedly, too, and he couldn‘t see a single collecting tin. It was on his way back past them, clutching a large doughnut in a bag, that he caught a few words of what they were saying.
//创建表
create table t_harry(
wordline string
)
row format delimited lines terminated by ‘\n‘;
?
//载入数据
load data inpath ‘/shsxt/java/Harry‘ into table t_harry;
?
//开始统计
select split(wordline,‘ ‘) from t_harry;
?
select explode(split(wordline,‘ ‘)) from t_harry;
?
select word,count(word) as cw from t_harry LATERAL VIEW explode(split(wordline,‘ ‘)) typeTable AS word group by word order by cw desc;
?
?
?
//使用子表查询数据
select word,count(word) from (select explode(split(wordline,‘ ‘)) as word from t_harry) w
group by word;
?
//使用SQL语句求出结果的过程有可能不同
create table t_cell(
create table t_cell(
record_time string,
imei string,
cell string,
ph_num int,
call_num int,
drop_num int,
duration int,
drop_rate DOUBLE,
net_type string,
erl string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘,‘
STORED AS TEXTFILE;
//载入数据
load data inpath ‘/shsxt/cell/cell.txt‘ into table t_cell;
?
//整理属性
record_time 2011-07-13 00:00:00+08
imei 352024
cell 29448-37062
ph_num 1
call_num 2
drop_num 3
duration 4
drop_rate 5
net_type G
erl 6
//获取掉话的比例
select imei,sum(drop_num),sum(duration),sum(drop_num)/sum(duration) as sdd from t_cell where duration <> 0 group by imei order by sdd desc limit 20;
?
//计算96W数据的掉话率
load data inpath ‘/shsxt/cell/cdr_summ_imei_cell_info.csv‘ into table t_cell;
添加109个jar包
1.1 创建一个普通的java类,继承org.apache.hadoop.hive.ql.exec.UDF
1.2 实现public String evaluate(Object value...)方法,这个方法属于重载方法,可以传入任意类型的参数
1.3 将写好的代码封装成Jar包,上传到Linux
1.4 在hive客户端输入命令,清空以前的jar缓存,,然后将jar其添加到hive函数库
delete jar /root/sxtud.jar;
add jar /root/sxtud.jar;
1.5 给临时函数定义一个名字
CREATE TEMPORARY FUNCTION ly_hello AS ‘com.shsxt.util.SxtUDFHello‘;
1.6 使用函数
select empno,ename from t_emp;
select ly_hello(empno),ly_hello(ename),ly_hello(ename,empno) from t_emp;
1.7 销毁函数
DROP TEMPORARY FUNCTION ly_hello;
1.8 源码
package com.shsxt.util;
?
import org.apache.hadoop.hive.ql.exec.UDF;
?
/**
* 自定义UDF函数
* @author Administrator
*
*/
public class SxtUDFHello extends UDF {
?
public String evaluate(String value) {
?
return "HelloString:" + value;
}
?
public String evaluate(String value1, int value2) {
?
return "HelloStringInt:" + value1 + "-" + value2;
}
?
public String evaluate(int value1, String value2) {
?
return "HelloIntString:" + value1 + "-" + value2;
}
?
public String evaluate(int value) {
?
return "HelloInt:" + value;
}
}
2.1 创建一个普通的java类继承org.apache.hadoop.hive.ql.exec.UDAF
2.2 在类中创建静态内部类ConcatEvaluator实现org.apache.hadoop.hive.ql.exec.UDAFEvaluator
2.3 将写好的代码封装成Jar包,上传到Linux
2.4 在hive客户端输入命令,清空以前的jar缓存,,然后将jar其添加到hive函数库
delete jar /root/sxtud.jar;
add jar /root/sxtud.jar;
2.5 给临时函数定义一个名字
CREATE TEMPORARY FUNCTION ly_hi AS ‘com.shsxt.util.SxtUDAFHi‘;
2.6 使用函数
select ly_hi(ename) from t_emp;
开始执行MapReduce
2.7 销毁函数
DROP TEMPORARY FUNCTION ly_hi;
2.8 源码
package com.shsxt.util;
?
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
?
/**
* 自定义UDAF函数
* @author Administrator
*
*/
public class SxtUDAFHi extends UDAF {
?
public static class SxtUDAFHiEvaluator implements UDAFEvaluator {
//定义一个可变字符串
private int sum;
?
1.可通过SQL轻松访问数据的工具,从而实现数据仓库任务,如提取/转换/加载(ETL),报告和数据分析。
2.它可以使已经存储的数据结构化
3.可以直接访问存储在Apache HDFS™或其他数据存储系统(如Apache HBase™)中的文件
4.Hive除了支持MapReduce计算引擎,还支持Spark和Tez这两中分布式计算引擎(这里会引申出一个问题,哪些查询跑mr哪些不跑?)
5.它提供类似sql的查询语句HiveQL对数据进行分析处理。
6.数据的存储格式有多种,比如数据源是二进制格式, 普通文本格式等
1.1时效性、延时性比较高,可扩展性高;
1.2.Hive数据规模大,优势在于处理大数据集,对于小数据集没有优势
1.3.事务没什么用(比较鸡肋,没什么实际的意义,对于离线的来说) 一个小问题:
那个版本开始提供了事务?
1.4.insert/update没什么实际用途,大数据场景下大多数是select
1.5.RDBMS也支持分布式,节点有限 成本高,处理的数据量小
1.6.Hadoop集群规模更大 部署在廉价机器上,处理的数据量大
1.7.数据库可以用在Online的应用中,Hive主要进行离线的大数据分析;
1.8.数据库的查询语句为SQL,Hive的查询语句为HQL;
1.9.数据库数据存储在LocalFS,Hive的数据存储在HDFS;
1.10.数据格式:Hive中有多种存储格式:由于在加载数据的过程中,不需要从用户数据格式到 Hive 定义的数据格
式的转换,因此,Hive 在加载的过程中不会对数据本身进行任何修改,而只是将数据内容复制或者移动到相应的
HDFS 目录中。而在数据库中,不同的数据库有不同的存储引擎,定义了自己的数据格式。所有数据都会按照一定
的组织存储,因此,数据库加载数据的过程会比较耗时。
1.11.Hive执行MapReduce,MySQL执行Executor;
2.1.1Antlr定义SQL的语法规则,完成SQL词法,语法解析,将SQL转化为抽象语法树AST Tree
2.1.2遍历AST Tree,抽象出查询的基本组成单元QueryBlock
2.1.3遍历QueryBlock,翻译为执行操作树OperatorTree
2.1.4逻辑层优化器进行OperatorTree变换,合并不必ReduceSinkOperator,减少shuffle数据量
2.1.5遍历OperatorTree,翻译为MapReduce任务
2.1.6物理层优化器进行MapReduce任务的变换,生成最终的执行计划
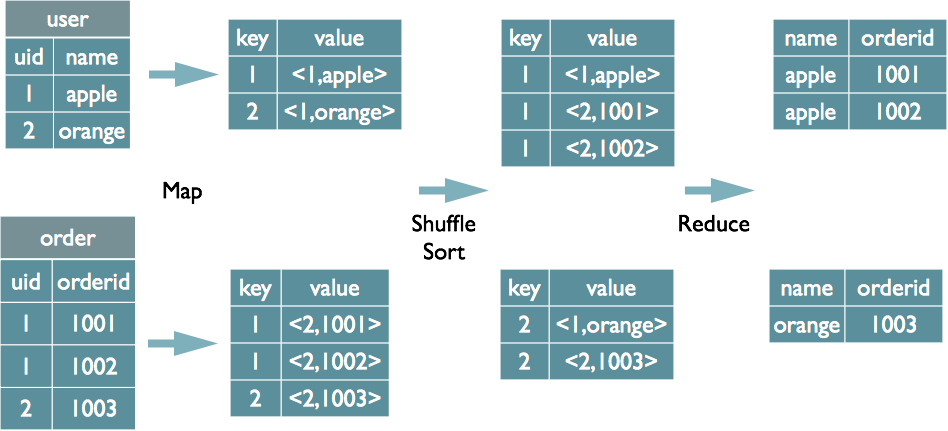
2.2.1select u.name, o.orderid from order o join user u on o.uid = u.uid;
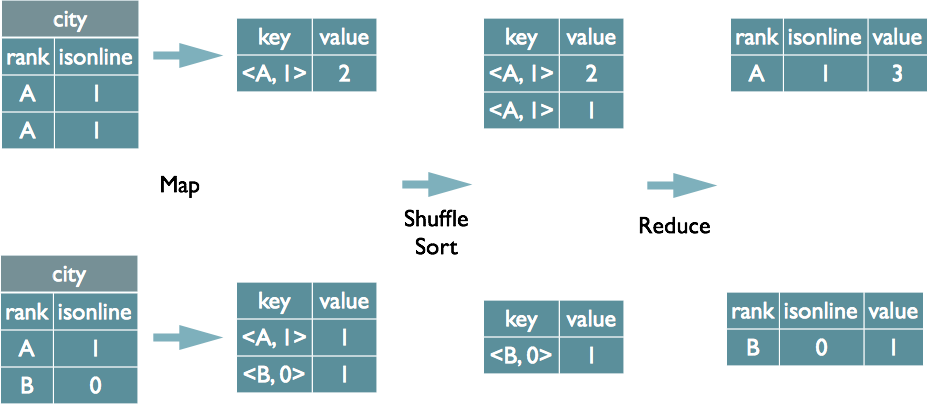
2.2.2select rank, isonline, count(*) from city group by rank, isonline;
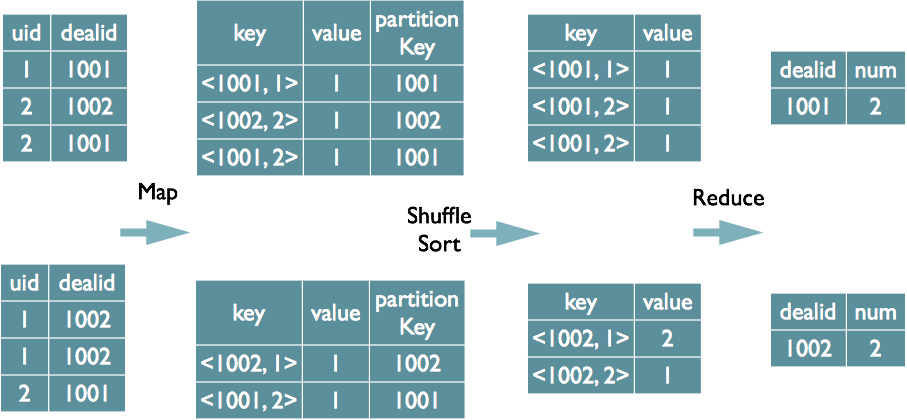
2.2.3select dealid, count(distinct uid) num from order group by dealid;
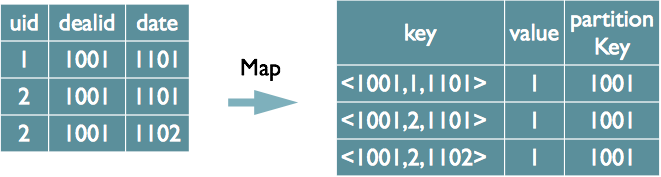
2.2.4select dealid, count(distinct uid), count(distinct date) from order group by dealid;
方案一:
方案二:
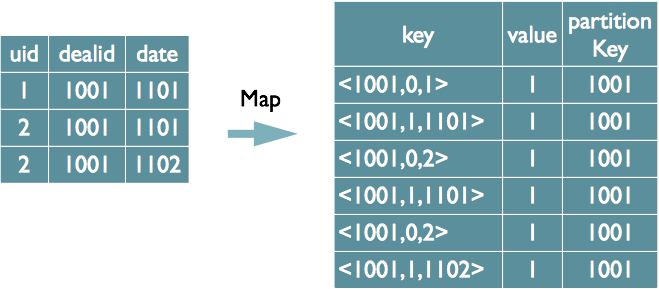
当表进行关联的时候,首先读取小表(程序员自定义)数据
让小表所处的主机开启本地的map操作,将表中的数据读出,并将其读取到hashtable中
让大表所有的主机开启本地的map操作。然后通过DC,获取hashtable.读取到本地
然后进行数据的合并,然后将合并后的数据进行写出
select * from a join b join c; a<b<c
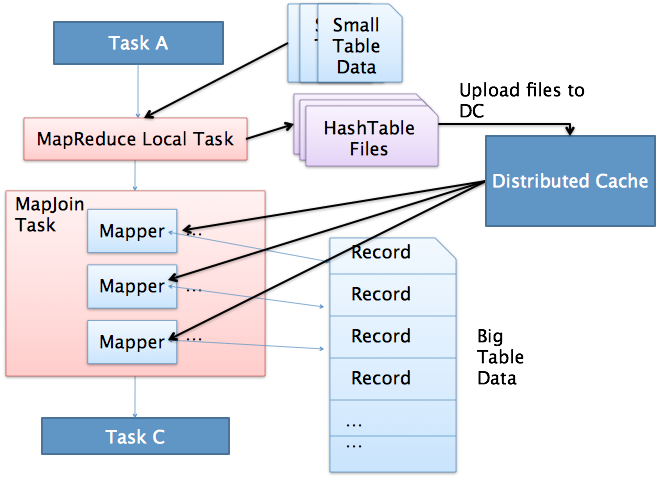
上图是Hive MapJoin的原理图,从图中可以看出MapJoin分为两个阶段:
(1)通过MapReduce Local Task,将小表读入内存,生成HashTableFiles上传至Distributed Cache中,这里会
对HashTableFiles进行压缩。
(2)MapReduce Job在Map阶段,每个Mapper从Distributed Cache读取HashTableFiles到内存中,顺序扫描大
表,在Map阶段直接进行Join,将数据传递给下一个MapReduce任务。
一行中有很多个列,每列都有不同的数据类型,解析数据的时候必须要按照不同类型进行解析
按照列进行压缩,因为列的属性都是相同的,所有压缩数据和解析数据的格式都是一致的
1,admin,123456
2,zhangsan,123456
3,lisi,123456
//行式压缩
1,admin,123456;2,zhangsan,123456
//列式压缩
1,2 admin,zhangsan 123456,123456
?
1,2,admin,zhangsan ,123456,123456
3,lisi,123456
?
select id,name from table;
select * from table where id = 2;
select * from t_emp where id = 8;
不会执行mapreduce
如果select的时候不出现分区或者组函数,直接使用hdfs的filter进行数据过滤
在hive-site.xml里面有个配置参数叫 hive.fetch.task.conversion= more不/minimal使用
insert不管多少数据都会走mapreduce
尽量查询频率高的词可以建立分区表减少数据扫描的范围
count(distinct)容易产生倾斜问题
Hive的分区方式:由于Hive实际是存储在HDFS上的抽象,Hive的一个分区名对应HDFS上的一个目录名,子分区
名就是子目录名,并不是一个实际字段。
产生背景:如果一个表中数据很多,我们查询时就很慢,耗费大量时间,如果要查询其中部分数据该怎么办呢,这
是我们引入分区的概念。
每张表中可以加入一个分区或者多个,方便查询,提高效率;并且HDFS上会有对应的分区目录
Hive分区是在创建表的时候用Partitioned by 关键字定义的,但要注意,Partitioned by子句中定义的列是表中正式
的列,但是Hive下的数据文件中并不包含这些列,因为它们是目录名,真正的数据在分区目录下。
创建表的语法都一样
静态分区:加载数据的时候要指定分区的值(key=value),比较麻烦的是每次插入数据都要指定分区的值,创建
多个分区多分区一样,以逗号分隔。
动态分区: 如果用上述的静态分区,插入的时候必须首先要知道有什么分区类型,而且每个分区写一个load data,太烦人。
使用动态分区可解决以上问题,其可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是
不指定分区目录,由系统自己选择。
我大数据场景下不害怕数据量大,害怕的是数据倾斜,怎样避免数据倾斜,找到可能产生数据倾斜的函数尤为关
键,数据量较大的情况下.
慎用count(distinct),count(distinct)容易产生倾斜问题。
mapred.min.split.size: 指的是数据的最小分割单元大小;min的默认值是1B
mapred.max.split.size: 指的是数据的最大分割单元大小;max的默认值是256MB
通过调整max可以起到调整map数的作用,减小max可以增加map数,增大max可以减少map数。
需要提醒的是,直接调整mapred.map.tasks这个参数是没有效果的。
a) 假设input目录下有1个文件a,大小为780M,那么hadoop会将该文件a分隔成7个块(6个128m的块和1个12m
块),从而产生7个map数 b) 假设input目录下有3个文件a,b,c,大小分别为10m,20m,130m,那么hadoop会分隔成4个块
(10m,20m,128m,2m),从而产生4个map数.即,如果文件大于块大小(128m),那么会拆分,如果小于块大小,则
把该文件当成一个块。其实这就涉及到小文件的问题:如果一个任务有很多小文件(远远小于块大小128m),则每
个小文件也会被当做一个块,用一个map任务来完成,而一个map任务启动和初始化的时间远远大于逻辑处理的
时间,就会造成很大的资源浪费。而且,同时可执行的map数是受限的。那么问题又来了。。是不是保证每个
map处理接近128m的文件块,就高枕无忧了? 答案也是不一定。比如有一个127m的文件,正常会用一个map去完成,但这个文件只有一个或者两个小字段,却
有几千万的记录,如果map处理的逻辑比较复杂,用一个map任务去做,肯定也比较耗时。
我们该如何去解决呢???
我们需要采取两种方式来解决:即减少map数和增加map数;
假设一个SQL任务:
Select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’;
该任务的inputdir /group/p_sdo_data/p_sdo_data_etl/pt/popt_tbaccountcopy_mes/pt=2012-07-04
共有194个文件,其中很多是远远小于128m的小文件,总大小9G,正常执行会用194个map任务。
Map总共消耗的计算资源: SLOTS_MILLIS_MAPS= 623,020
?
?
我通过以下方法来在map执行前合并小文件,减少map数:
set mapred.max.split.size=100000000;
set mapred.min.split.size.per.node=100000000;
set mapred.min.split.size.per.rack=100000000;
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
再执行上面的语句,用了74个map任务,map消耗的计算资源:SLOTS_MILLIS_MAPS= 333,500
对于这个简单SQL任务,执行时间上可能差不多,但节省了一半的计算资源。
大概解释一下,100000000表示100M, set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;这个参数表示执行前进行小文件合并,前面三个参数确定合并文件块的大小,大于文件块大小128m的,按照128m来分隔,小于128m,大于100m的,按照100m来分隔,把那些小于100m的(包括小文件和分隔大文件剩下的),进行合并,最终生成了74个块。
如何适当的增加map数?
当input的文件都很大,任务逻辑复杂,map执行非常慢的时候,可以考虑增加Map数,
来使得每个map处理的数据量减少,从而提高任务的执行效率。
假设有这样一个任务:
Select data_desc,
count(1),
count(distinct id),
sum(case when …),
sum(case when ...),
sum(…)
from a group by data_desc
如果表a只有一个文件,大小为120M,但包含几千万的记录,如果用1个map去完成这个任务,
肯定是比较耗时的,这种情况下,我们要考虑将这一个文件合理的拆分成多个,
这样就可以用多个map任务去完成。
set mapred.reduce.tasks=10;
create table a_1 as
select * from a
distribute by rand(123);
?
这样会将a表的记录,随机的分散到包含10个文件的a_1表中,再用a_1代替上面sql中的a表,
则会用10个map任务去完成。
每个map任务处理大于12M(几百万记录)的数据,效率肯定会好很多。
?
看上去,貌似这两种有些矛盾,一个是要合并小文件,一个是要把大文件拆成小文件,
这点正是重点需要关注的地方,
使单个map任务处理合适的数据量;
map的数量和切片相关
map不要设置的太多
有可能导致oom的问题
map不要设置的太少
有可能导致map节点少处理数据慢
查看具体的每个数据的块数据数量和内存的消耗
Reduce的个数对整个作业的运行性能有很大影响。如果Reduce设置的过大,那么将会产生很多小文件,
对NameNode会产生一定的影响,
而且整个作业的运行时间未必会减少;如果Reduce设置的过小,那么单个Reduce处理的数据将会加大,
很可能会引起OOM异常。
如果设置了mapred.reduce.tasks/mapreduce.job.reduces参数,那么Hive会直接使用它的值作为Reduce的个数;
如果mapred.reduce.tasks/mapreduce.job.reduces的值没有设置(也就是-1),那么Hive会
根据输入文件的大小估算出Reduce的个数。
根据输入文件估算Reduce的个数可能未必很准确,因为Reduce的输入是Map的输出,而Map的输出可能会比输入要小,
所以最准确的数根据Map的输出估算Reduce的个数。
reduce数量过多会产生很多的小文件,会对namenode产生压力
reduce数量过少会导致单个节点压力大,会产生oomHive会猜测确定一个reduce个数,基于以下两个设定hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据
量,默认为1000^3=1G)hive.exec.reducers.max(每个任务最大的
reduce数,默认为999)
hive也会根据桶的数量分配reduce数
只有一个reduce的情况
分组函数没有进行分区select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’ group by pt;
select count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04’;
order by是对整个数据进行排序sorted by 只对每一个reduce产生的数据进行排序
调整reduce个数方法一:
调整hive.exec.reducers.bytes.per.reducer参数的值;
set hive.exec.reducers.bytes.per.reducer=500000000; (500M)
select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04‘ group by pt; 这次有20个reduce
调整reduce个数方法二:
set mapred.reduce.tasks = 15;
select pt,count(1) from popt_tbaccountcopy_mes where pt = ‘2012-07-04‘ group by pt;这次有15个reduce
对于大多数情况,Hive可以通过本地模式在单台机器上处理所有任务。对于小
数据,执行时间可以明显被缩短。
通过set hive.exec.mode.local.auto=true(默认为false)设置本地模式。
hive> set hive.exec.mode.local.auto;
hive.exec.mode.local.auto=false
Hive会将一个查询转化成一个或者多个阶段。这样的阶段可以是MapReduce阶段、抽样阶段、合并阶段、limit阶
段。
默认情况下,Hive一次只会执行一个阶段,由于job包含多个阶段,而这些阶段并非完全互相依赖,即:这些阶段
可以并行执行,可以缩短整个job的执行时间。设置参数:set hive.exec.parallel=true,或者通过配置文件来完成。
hive> set hive.exec.parallel;
hive.exec.parallel=false
Hive提供一个严格模式,可以防止用户执行那些可能产生意想不到的影响查询,通过设置
Hive.mapred.modestrict来完成set Hive.mapred.modestrict;
Hive.mapred.modestrict is undefined
Hadoop通常是使用派生JVM来执行map和reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是
执行的job包含偶成百上千的task任务的情况。JVM重用可以使得JVM示例在同一个job中时候使用N此。通过参数
mapred.job.reuse.jvm.num.tasks来设置。
Hadoop推测执行可以触发执行一些重复的任务,尽管因对重复的数据进行计算而导致消耗更多的计算资源,不过
这个功能的目标是通过加快获取单个task的结果以侦测执行慢的TaskTracker加入到没名单的方式来提高整体的任
务执行效率。
Hadoop的推测执行功能由2个配置控制着,通过mapred-site.xml中配置
mapred.map.tasks.speculative.execution=true
mapred.reduce.tasks.speculative.execution=true
标签:obj 数据库数据 cut 移动 抽样 profile ORC 浮点型 位置
原文地址:https://www.cnblogs.com/ruanjianwei/p/12119324.html