标签:vector int set ted 测试 cto 数列 知识 view
下载所需数据并解压
链接:https://pan.baidu.com/s/1Jg5NPxc9L-M8Tdgh70Tvig
提取码:dpqq
# 导入程序所需要的程序包
#PyTorch用的包
import torch
import torch.nn as nn
import torch.optim
from torch.autograd import Variable
# 自然语言处理相关的包
import re #正则表达式的包
import jieba #结巴分词包
from collections import Counter #搜集器,可以让统计词频更简单
#绘图、计算用的程序包
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline提供了爬取好的评论文本在 data/good.txt 以及 data/bad.txt 中。
# 将文本中的标点符号过滤掉
def filter_punc(sentence):
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\'“”《》?“]+|[+——!,。?、~@#¥%……&*():]+", "", sentence)
return(sentence)在下面的函数代码中,首先会循环文本文件中的每行评论,过滤标点符号,分词。
将分词好的评论分别放置在 pos_sentences 与 neg_sentences 中。
# 扫描所有的文本,分词、建立词典,分出正向还是负向的评论,is_filter可以过滤是否筛选掉标点符号
def Prepare_data(good_file, bad_file, is_filter = True):
all_words = [] #存储所有的单词
pos_sentences = [] #存储正向的评论
neg_sentences = [] #存储负向的评论
with open(good_file, 'r') as fr:
for idx, line in enumerate(fr):
if is_filter:
#过滤标点符号
line = filter_punc(line)
#分词
words = jieba.lcut(line)
if len(words) > 0:
all_words += words
pos_sentences.append(words)
print('{0} 包含 {1} 行, {2} 个词.'.format(good_file, idx+1, len(all_words)))
count = len(all_words)
with open(bad_file, 'r') as fr:
for idx, line in enumerate(fr):
if is_filter:
line = filter_punc(line)
words = jieba.lcut(line)
if len(words) > 0:
all_words += words
neg_sentences.append(words)
print('{0} 包含 {1} 行, {2} 个词.'.format(bad_file, idx+1, len(all_words)-count))
#建立词典,diction的每一项为{w:[id, 单词出现次数]}
diction = {}
cnt = Counter(all_words)
for word, freq in cnt.items():
diction[word] = [len(diction), freq]
print('字典大小:{}'.format(len(diction)))
return(pos_sentences, neg_sentences, diction)这两个函数一个是用“词”来查“索引号”,一个是用“索引号”来查“词”。
#根据单词返还单词的编码
def word2index(word, diction):
if word in diction:
value = diction[word][0]
else:
value = -1
return(value)
#根据编码获得单词
def index2word(index, diction):
for w,v in diction.items():
if v[0] == index:
return(w)
return(None)下面将读取包含商品评论信息的两个文本文件。
good_file = 'data/good.txt'
bad_file = 'data/bad.txt'
pos_sentences, neg_sentences, diction = Prepare_data(good_file, bad_file, True)
st = sorted([(v[1], w) for w, v in diction.items()])
print(st)词带模型就是将一句话中的所有单词都放进一个袋子里(单词表),而忽略掉语法、语义,甚至单词之间的顺序这些所有的信息。最终只关心每一个单词的数量,然后根据这个数量来建立对句子进行表征的向量。
输入一个句子和相应的词典,得到这个句子的向量化表示。
# 输入一个句子和相应的词典,得到这个句子的向量化表示。
def sentence2vec(sentence, dictionary):
vector = np.zeros(len(dictionary))
for l in sentence:
vector[l] += 1
return(1.0 * vector / len(sentence))以句子为单位,将所有的积极情感的评论文本,全部转化为句子向量,并保存到数据集 dataset 中。
# 遍历所有句子,将每一个词映射成编码
dataset = [] #数据集
labels = [] #标签
sentences = [] #原始句子,调试用
# 处理正向评论
for sentence in pos_sentences:
new_sentence = []
for l in sentence:
if l in diction:
new_sentence.append(word2index(l, diction))
dataset.append(sentence2vec(new_sentence, diction))
labels.append(0) #正标签为0
sentences.append(sentence)对于消极情绪的评论如法炮制
# 处理负向评论
for sentence in neg_sentences:
new_sentence = []
for l in sentence:
if l in diction:
new_sentence.append(word2index(l, diction))
dataset.append(sentence2vec(new_sentence, diction))
labels.append(1) #负标签为1
sentences.append(sentence)下面进行数据集的切分。
#打乱所有的数据顺序,形成数据集
# indices为所有数据下标的一个全排列
indices = np.random.permutation(len(dataset))
#重新根据打乱的下标生成数据集dataset,标签集labels,以及对应的原始句子sentences
dataset = [dataset[i] for i in indices]
labels = [labels[i] for i in indices]
sentences = [sentences[i] for i in indices]
#对整个数据集进行划分,分为:训练集、校准集和测试集,其中校准和测试集合的长度都是整个数据集的10分之一
test_size = len(dataset) // 10
train_data = dataset[2 * test_size :]
train_label = labels[2 * test_size :]
valid_data = dataset[: test_size]
valid_label = labels[: test_size]
test_data = dataset[test_size : 2 * test_size]
test_label = labels[test_size : 2 * test_size]建立多层前馈网络
# 一个简单的前馈神经网络,三层,第一层线性层,加一个非线性ReLU,第二层线性层,中间有10个隐含层神经元
# 输入维度为词典的大小:每一段评论的词袋模型
model = nn.Sequential(
nn.Linear(len(diction), 10),
nn.ReLU(),
nn.Linear(10, 2),
nn.LogSoftmax(dim=1),
)编写的是计算预测错误率的函数。
def rightness(predictions, labels):
"""计算预测错误率的函数,其中predictions是模型给出的一组预测结果,
batch_size行num_classes列的矩阵,labels是数据之中的正确答案"""
# 对于任意一行(一个样本)的输出值的第1个维度,求最大,得到每一行的最大元素的下标
pred = torch.max(predictions.data, 1)[1]
#将下标与labels中包含的类别进行比较,并累计得到比较正确的数量
rights = pred.eq(labels.data.view_as(pred)).sum()
#返回正确的数量和这一次一共比较了多少元素
return rights, len(labels) 建立好神经网络之后,就可以进行训练了。
# 损失函数为交叉熵
cost = torch.nn.NLLLoss()
# 优化算法为Adam,可以自动调节学习率
optimizer = torch.optim.Adam(model.parameters(), lr = 0.01)# 记录列表,记录训练时的各种数据,以用于绘图
records = []
# loss 列表,用于记录训练中的 loss
losses = []
def trainModel(data, label):
# 需要将输入的数据进行适当的变形,主要是要多出一个batch_size的维度,也即第一个为1的维度
# 这样做是为了适应 PyTorch 函数的特殊用法,具体可以参考 PyTorch 官方文档
x = Variable(torch.FloatTensor(data).view(1,-1))
# x的尺寸:batch_size=1, len_dictionary
# 标签也要加一层外衣以变成1*1的张量
y = Variable(torch.LongTensor(np.array([label])))
# y的尺寸:batch_size=1, 1
# 清空梯度
optimizer.zero_grad()
# 模型预测
predict = model(x)
# 计算损失函数
loss = cost(predict, y)
# 将损失函数数值加入到列表中
losses.append(loss.data.numpy())
# 开始进行梯度反传
loss.backward()
# 开始对参数进行一步优化
optimizer.step()验证模型的函数
def evaluateModel(data, label):
x = Variable(torch.FloatTensor(data).view(1, -1))
y = Variable(torch.LongTensor(np.array([label])))
# 模型预测
predict = model(x)
# 调用rightness函数计算准确度
right = rightness(predict, y)
# 计算loss
loss = cost(predict, y)
return predict, right, loss训练循环部分
#循环10个Epoch
for epoch in range(10):
for i, data in enumerate(zip(train_data, train_label)):
x, y = data
# 调用上面编写的训练函数
# x 即句子向量,y 即标签(0 or 1)
trainModel(x, y)
# 每隔3000步,跑一下校验数据集的数据,输出临时结果
if i % 3000 == 0:
val_losses = []
rights = []
# 在所有校验数据集上实验
for j, val in enumerate(zip(valid_data, valid_label)):
x, y = val
# 调用模型测试函数
predict, right, loss = evaluateModel(x, y)
rights.append(right)
val_losses.append(loss.data.numpy())
# 将校验集合上面的平均准确度计算出来
right_ratio = 1.0 * np.sum([i[0] for i in rights]) / np.sum([i[1] for i in rights])
print('第{}轮,训练损失:{:.2f}, 校验损失:{:.2f}, 校验准确率: {:.2f}'.format(epoch, np.mean(losses),np.mean(val_losses), right_ratio))
records.append([np.mean(losses), np.mean(val_losses), right_ratio])损失函数和准确度的曲线画出来
# 绘制误差曲线
a = [i[0] for i in records]
b = [i[1] for i in records]
c = [i[2] for i in records]
plt.plot(a, label = 'Train Loss')
plt.plot(b, label = 'Valid Loss')
plt.plot(c, label = 'Valid Accuracy')
plt.xlabel('Steps')
plt.ylabel('Loss & Accuracy')
plt.legend()在整个测试集上运行,记录预测结果,并计算总的正确率。
vals = [] #记录准确率所用列表
#对测试数据集进行循环
for data, target in zip(test_data, test_label):
data, target = Variable(torch.FloatTensor(data).view(1,-1)), Variable(torch.LongTensor(np.array([target])))
output = model(data) #将特征数据喂入网络,得到分类的输出
val = rightness(output, target) #获得正确样本数以及总样本数
vals.append(val) #记录结果
#计算准确率
rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
right_rate = 1.0 * rights[0].data.numpy() / rights[1]
print(right_rate)了解 RNN 模型如何实现,以及考察它们在测试数据集上的分类准确度。
正如词袋模型那样,首先加载并预处理数据。
与词袋模型不同,在这次 RNN 的实验中,不去除评论语料中的标点符号。
# 需要重新数据预处理,主要是要加上标点符号,它对于RNN起到重要作用
# 数据来源文件
good_file = 'data/good.txt'
bad_file = 'data/bad.txt'
pos_sentences, neg_sentences, diction = Prepare_data(good_file, bad_file, False)dataset = []
labels = []
sentences = []
# 正例集合
for sentence in pos_sentences:
new_sentence = []
for l in sentence:
if l in diction:
# 注意将每个词编码
new_sentence.append(word2index(l, diction))
#每一个句子都是一个不等长的整数序列
dataset.append(new_sentence)
labels.append(0)
sentences.append(sentence)
# 反例集合
for sentence in neg_sentences:
new_sentence = []
for l in sentence:
if l in diction:
new_sentence.append(word2index(l, diction))
dataset.append(new_sentence)
labels.append(1)
sentences.append(sentence)
# 重新对数据洗牌,构造数据集合
indices = np.random.permutation(len(dataset))
dataset = [dataset[i] for i in indices]
labels = [labels[i] for i in indices]
sentences = [sentences[i] for i in indices]
test_size = len(dataset) // 10
# 训练集
train_data = dataset[2 * test_size :]
train_label = labels[2 * test_size :]
# 校验集
valid_data = dataset[: test_size]
valid_label = labels[: test_size]
# 测试集
test_data = dataset[test_size : 2 * test_size]
test_label = labels[test_size : 2 * test_size]采用手动编写模型的方式,以熟悉 RNN 的结构与工作流程。本次要搭建的 RNN 模型结构如下:
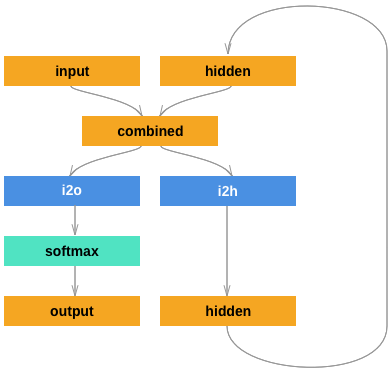
# 一个手动实现的RNN模型
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
# 一个embedding层
self.embed = nn.Embedding(input_size, hidden_size)
# 隐含层内部的相互链接
self.i2h = nn.Linear(2 * hidden_size, hidden_size)
# 隐含层到输出层的链接
self.i2o = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
# 先进行embedding层的计算,它可以把一个数或者数列,映射成一个向量或一组向量
# input尺寸:seq_length, 1
x = self.embed(input)
# x尺寸:hidden_size
# 将输入和隐含层的输出(hidden)耦合在一起构成了后续的输入
combined = torch.cat((x.view(1, -1), hidden), 1)
# combined尺寸:2*hidden_size
#
# 从输入到隐含层的计算
hidden = self.i2h(combined)
# combined尺寸:hidden_size
# 从隐含层到输出层的运算
output = self.i2o(hidden)
# output尺寸:output_size
# softmax函数
output = self.softmax(output)
return output, hidden
def initHidden(self):
# 对隐含单元的初始化
# 注意尺寸是:batch_size, hidden_size
return Variable(torch.zeros(1, self.hidden_size))训练这个 RNN 网络。
# 开始训练这个RNN,10个隐含层单元
rnn = RNN(len(diction), 10, 2)
# 交叉熵评价函数
cost = torch.nn.NLLLoss()
# Adam优化器
optimizer = torch.optim.Adam(rnn.parameters(), lr = 0.001)
records = []
# 学习周期10次
losses = []
for epoch in range(10):
for i, data in enumerate(zip(train_data, train_label)):
x, y = data
x = Variable(torch.LongTensor(x))
#x尺寸:seq_length(序列的长度)
y = Variable(torch.LongTensor([y]))
#x尺寸:batch_size = 1,1
optimizer.zero_grad()
#初始化隐含层单元全为0
hidden = rnn.initHidden()
# hidden尺寸:batch_size = 1, hidden_size
#手动实现RNN的时间步循环,x的长度就是总的循环时间步,因为要把x中的输入句子全部读取完毕
for s in range(x.size()[0]):
output, hidden = rnn(x[s], hidden)
#校验函数
loss = cost(output, y)
losses.append(loss.data.numpy())
loss.backward()
# 开始优化
optimizer.step()
if i % 3000 == 0:
# 每间隔3000步来一次校验集上面的计算
val_losses = []
rights = []
for j, val in enumerate(zip(valid_data, valid_label)):
x, y = val
x = Variable(torch.LongTensor(x))
y = Variable(torch.LongTensor(np.array([y])))
hidden = rnn.initHidden()
for s in range(x.size()[0]):
output, hidden = rnn(x[s], hidden)
right = rightness(output, y)
rights.append(right)
loss = cost(output, y)
val_losses.append(loss.data.numpy())
# 计算准确度
right_ratio = 1.0 * np.sum([i[0] for i in rights]) / np.sum([i[1] for i in rights])
print('第{}轮,训练损失:{:.2f}, 测试损失:{:.2f}, 测试准确率: {:.2f}'.format(epoch, np.mean(losses),np.mean(val_losses), right_ratio))
records.append([np.mean(losses), np.mean(val_losses), right_ratio])绘制 RNN 模型的误差曲线
# 绘制误差曲线
a = [i[0] for i in records]
b = [i[1] for i in records]
c = [i[2] for i in records]
plt.plot(a, label = 'Train Loss')
plt.plot(b, label = 'Valid Loss')
plt.plot(c, label = 'Valid Accuracy')
plt.xlabel('Steps')
plt.ylabel('Loss & Accuracy')
plt.legend()在测试集上运行,并计算准确率。
vals = [] #记录准确率所用列表
rights = list(rights)
#对测试数据集进行循环
for j, test in enumerate(zip(test_data, test_label)):
x, y = test
x = Variable(torch.LongTensor(x))
y = Variable(torch.LongTensor(np.array([y])))
hidden = rnn.initHidden()
for s in range(x.size()[0]):
output, hidden = rnn(x[s], hidden)
right = rightness(output, y)
rights.append(right)
val = rightness(output, y) #获得正确样本数以及总样本数
vals.append(val) #记录结果
#计算准确率
rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
right_rate = 1.0 * rights[0].data.numpy() / rights[1]
right_rate将模型保存下来。
# 保存、加载模型(为讲解用)
torch.save(rnn, 'rnn.mdl')
rnn = torch.load('rnn.mdl')普通 RNN 的效果并不好,可以尝试利用改进型的 RNN,即 LSTM。
LSTM 与 RNN 最大的区别就是在于每个神经元中多增加了3个控制门:遗忘门、输入门和输出门。
另外,在每个隐含层神经元中,LSTM 多了一个 cell 的状态,起到了记忆的作用。
这就使得 LSTM 可以记忆更长时间的 Pattern。
class LSTMNetwork(nn.Module):
def __init__(self, input_size, hidden_size, n_layers=1):
super(LSTMNetwork, self).__init__()
self.n_layers = n_layers
self.hidden_size = hidden_size
# LSTM的构造如下:一个embedding层,将输入的任意一个单词映射为一个向量
# 一个LSTM隐含层,共有hidden_size个LSTM神经元
# 一个全链接层,外接一个softmax输出
self.embedding = nn.Embedding(input_size, hidden_size)
self.lstm = nn.LSTM(hidden_size, hidden_size, n_layers)
self.fc = nn.Linear(hidden_size, 2)
self.logsoftmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden=None):
#input尺寸: seq_length
#词向量嵌入
embedded = self.embedding(input)
#embedded尺寸: seq_length, hidden_size
#PyTorch设计的LSTM层有一个特别别扭的地方是,输入张量的第一个维度需要是时间步,
#第二个维度才是batch_size,所以需要对embedded变形
embedded = embedded.view(input.data.size()[0], 1, self.hidden_size)
#embedded尺寸: seq_length, batch_size = 1, hidden_size
#调用PyTorch自带的LSTM层函数,注意有两个输入,一个是输入层的输入,另一个是隐含层自身的输入
# 输出output是所有步的隐含神经元的输出结果,hidden是隐含层在最后一个时间步的状态。
# 注意hidden是一个tuple,包含了最后时间步的隐含层神经元的输出,以及每一个隐含层神经元的cell的状态
output, hidden = self.lstm(embedded, hidden)
#output尺寸: seq_length, batch_size = 1, hidden_size
#hidden尺寸: 二元组(n_layer = 1 * batch_size = 1 * hidden_size, n_layer = 1 * batch_size = 1 * hidden_size)
#我们要把最后一个时间步的隐含神经元输出结果拿出来,送给全连接层
output = output[-1,...]
#output尺寸: batch_size = 1, hidden_size
#全链接层
out = self.fc(output)
#out尺寸: batch_size = 1, output_size
# softmax
out = self.logsoftmax(out)
return out
def initHidden(self):
# 对隐单元的初始化
# 对隐单元输出的初始化,全0.
# 注意hidden和cell的维度都是layers,batch_size,hidden_size
hidden = Variable(torch.zeros(self.n_layers, 1, self.hidden_size))
# 对隐单元内部的状态cell的初始化,全0
cell = Variable(torch.zeros(self.n_layers, 1, self.hidden_size))
return (hidden, cell)训练 LSTM 模型。
# 开始训练LSTM网络
# 构造一个LSTM网络的实例
lstm = LSTMNetwork(len(diction), 10, 2)
#定义损失函数
cost = torch.nn.NLLLoss()
#定义优化器
optimizer = torch.optim.Adam(lstm.parameters(), lr = 0.001)
records = []
# 开始训练,一共15个epoch
losses = []
for epoch in range(15):
for i, data in enumerate(zip(train_data, train_label)):
x, y = data
x = Variable(torch.LongTensor(x))
#x尺寸:seq_length,序列的长度
y = Variable(torch.LongTensor([y]))
#y尺寸:batch_size = 1, 1
optimizer.zero_grad()
#初始化LSTM隐含层单元的状态
hidden = lstm.initHidden()
#hidden: 二元组(n_layer = 1 * batch_size = 1 * hidden_size, n_layer = 1 * batch_size = 1 * hidden_size)
#让LSTM开始做运算,注意,不需要手工编写对时间步的循环,而是直接交给PyTorch的LSTM层。
#它自动会根据数据的维度计算若干时间步
output = lstm(x, hidden)
#output尺寸: batch_size = 1, output_size
#损失函数
loss = cost(output, y)
losses.append(loss.data.numpy())
#反向传播
loss.backward()
optimizer.step()
#每隔3000步,跑一次校验集,并打印结果
if i % 3000 == 0:
val_losses = []
rights = []
for j, val in enumerate(zip(valid_data, valid_label)):
x, y = val
x = Variable(torch.LongTensor(x))
y = Variable(torch.LongTensor(np.array([y])))
hidden = lstm.initHidden()
output = lstm(x, hidden)
#计算校验数据集上的分类准确度
right = rightness(output, y)
rights.append(right)
loss = cost(output, y)
val_losses.append(loss.data.numpy())
right_ratio = 1.0 * np.sum([i[0] for i in rights]) / np.sum([i[1] for i in rights])
print('第{}轮,训练损失:{:.2f}, 测试损失:{:.2f}, 测试准确率: {:.2f}'.format(epoch, np.mean(losses),np.mean(val_losses), right_ratio))
records.append([np.mean(losses), np.mean(val_losses), right_ratio]) 在测试集上计算总的正确率。
vals = [] #记录准确率所用列表
rights = list(rights)
#对测试数据集进行循环
for j, test in enumerate(zip(test_data, test_label)):
x, y = test
x = Variable(torch.LongTensor(x))
y = Variable(torch.LongTensor(np.array([y])))
hidden = lstm.initHidden()
output = lstm(x, hidden)
right = rightness(output, y)
rights.append(right)
val = rightness(output, y) #获得正确样本数以及总样本数
vals.append(val) #记录结果
#计算准确率
rights = (sum([tup[0] for tup in vals]), sum([tup[1] for tup in vals]))
right_rate = 1.0 * rights[0].data.numpy() / rights[1]
right_rate保存模型。
#保存、加载模型(为讲解用)
torch.save(lstm, 'lstm.mdl')
lstm = torch.load('lstm.mdl')尝试了两种 RNN 网络,一种是普通的 RNN,另一种是 LSTM。展示了它们在处理同样的文本分类问题上的用法。
标签:vector int set ted 测试 cto 数列 知识 view
原文地址:https://www.cnblogs.com/wwj99/p/12193627.html