标签:乱码问题 RoCE ini alt tin name ESS dict item
背景:使用scrapy crawl spidername -o filename.json命令执行爬虫,并将item写入文件,发现中文乱码,比如这样子: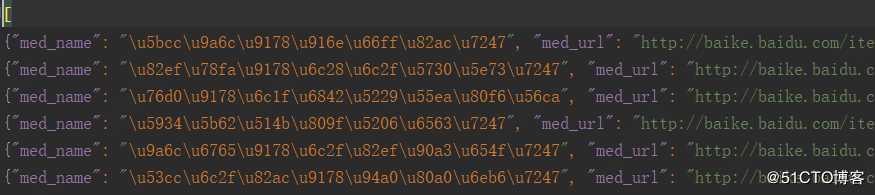
使用scrapy命令导出时指定编码格式
scrapy crawl baidu -o baidu_med.json -s FEED_EXPORT_ENCODING=utf-8借助Pipeline将item写入到文件
1.修改pipelines.py,添加:
import json
import codecs
class YiyaoPipeline(object):
def __init__(self):
self.file = codecs.open(‘item.json‘, ‘wb‘, encoding=‘utf-8‘)
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + ‘\n‘
self.file.write(line)
return item2.修改settings.py,激活pipeline:
ITEM_PIPELINES = {
‘yiyao.pipelines.YiyaoPipeline‘: 300,
}注意:settings.py默认有ITEM_PIPELINES配置,只是注销掉了。
3.使用scrapy命令导出时,直接执行:
scrapy crawl baidu 标签:乱码问题 RoCE ini alt tin name ESS dict item
原文地址:https://blog.51cto.com/fengjicheng/2466754