标签:describe aggregate 方式 tuple 左连接 信息 image merge first
# 数据导入 pd.read_csv(filename) # 导入csv格式文件中的数据 pd.read_table(filename) # 导入有分隔符的文本 (如TSV) 中的数据 pd.read_excel(filename) # 导入Excel格式文件中的数据 pd.read_sql(query, connection_object) # 导入SQL数据表/数据库中的数据 pd.read_json(json_string) # 导入JSON格式的字符,URL地址或者文件中的数据 pd.read_html(url) # 导入经过解析的URL地址中包含的数据框 (DataFrame) 数据 pd.read_clipboard() # 导入系统粘贴板里面的数据 pd.DataFrame(dict) # 导入Python字典 (dict) 里面的数据,其中key是数据框的表头,value是数据框的内容。 # 数据导出 df.to_csv(filename) # 将数据框 (DataFrame)中的数据导入csv格式的文件中 df.to_excel(filename) # 将数据框 (DataFrame)中的数据导入Excel格式的文件中 df.to_sql(table_name,connection_object) # 将数据框 (DataFrame)中的数据导入SQL数据表/数据库中 df.to_json(filename) # 将数据框 (DataFrame)中的数据导入JSON格式的文件中
Pandas是一个开放源码的Python库,它使用强大的数据结构提供高性能的数据操作和分析工具。
Python Pandas用于广泛的领域,包括金融,经济,统计,分析等学术和商业领域。
快速高效的DataFrame对象,具有默认和自定义的索引。
将数据从不同文件格式加载到内存中的数据对象的工具。
丢失数据的数据对齐和综合处理。
重组和摆动日期集。
基于标签的切片,索引和大数据集的子集。
可以删除或插入来自数据结构的列。
按数据分组进行聚合和转换。
高性能合并和数据加入。
时间序列功能。
Series是具有均匀数据的一维数组结构。
Series特点:均匀数据、尺寸大小不变、数据的值可变。
Series是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。轴标签统称为索引。
示例如下:

Series创建:
sel = pd.Series([1,2,3,4]) sel = pd.Series(data=[1,2,3,4],index=list[‘abcd‘]) # 指定索引
Series属性
# 获取内容 sel.values # 获取索引 sel.index # Series为空,返回True sel.empty # 返回数据维数 sel.ndim # 返回数据元素数 sel.size
数据帧是一个具有异构数据的二维数组。
DataFrame特点:异构数据、大小可变、数据可变。示例如下:
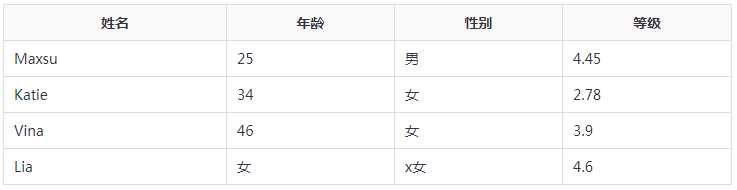
pandas.DataFrame( data, index, columns, dtype, copy) # data 数据采取各种形式,如:ndarray,series,map,tuple,list,dict,constant和另一个DataFrame; # 方法1:使用二维数组 df = pd.DataFrame(np.random.randint(0,10,(4,4)),index=[1,2,3,4],columns=[‘a‘,‘b‘,‘c‘,‘d‘]) # 方法2:使用字典创建 df = pd.DataFrame(dict)
pandas.DataFrame( data, index, columns, dtype, copy)
# data 数据采取各种形式,如:ndarray,series,map,tuple,list,dict,constant和另一个DataFrame;
# index 对于行标签,要用于结果帧的索引是可选缺省值np.arrange(n),如果没有传递索引值;
# columns 对于列标签,可选的默认语法是 - np.arange(n),这只有在没有索引传递的情况下才是这样;
# dtype 每列的数据类型;
# copy 如果默认值为False,则此命令(或任何它)用于复制数据。
DataFrame属性:
# T 转置行和列;
# axes 返回一个列,行轴标签和列轴标签作为唯一的成员;
# dtypes 返回此对象中的数据类型(dtypes);
# empty 如果NDFrame完全为空,则返回为True; 如果任何轴的长度为0;
# ndim 轴/数组维度大小;
# shape 返回表示DataFrame的维度的元组;
# size NDFrame中的元素数;
# values NDFrame的Numpy表示;
# head 返回开头前n行;
# tail 返回最后n行。
Pandas提供了各种方法来完成基于标签的索引。 切片时,也包括起始边界。整数是有效的标签,但它们是指标签而不是位置。
.loc()访问方式有:单个标量标签、标签列表、切片对象、一个布尔数组
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4),index = [‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘,‘g‘,‘h‘], columns = [‘A‘, ‘B‘, ‘C‘, ‘D‘])
print (df.loc[:,‘A‘]) # 返回A列所有数据(单列)
print (df.loc[:,[‘A‘,‘C‘]]) # 返回A、C列所有数据(多列)
print (df.loc[[‘a‘,‘b‘,‘f‘,‘h‘],[‘A‘,‘C‘]]) # 多行多列
print (df.loc[‘a‘:‘h‘]) # 返回a-h行所有数据(多行
- 基于整数多轴索引.iloc()
Pandas提供了各种方法,以获得纯整数索引。像python和numpy一样,第一个位置是基于0的索引。
.iloc()访问方式有: 整数、整数列表、系列值。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4), columns = [‘A‘, ‘B‘, ‘C‘, ‘D‘])
print (df.iloc[1:5, 2:4]) # 左包含右不包含
print (df.iloc[:4])
print (df.iloc[[1, 3, 5], [1, 3]])
- 基于标签和整数多轴索引.ix()
除了基于纯标签和整数之外,Pandas还提供了一种使用.ix()运算符进行选择和子集化对象的混合方法。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4), columns = [‘A‘, ‘B‘, ‘C‘, ‘D‘])
|--------------------------------------------|-------------------------|
| print (df.ix[:4]) | print (df.ix[:,‘A‘]) |
|--------------------------------------------|-------------------------|
| A B C D | 0 1.539915 |
| 0 -1.449975 -0.002573 1.349962 0.539765 | 1 1.359477 |
| 1 -1.249462 -0.800467 0.483950 0.187853 | 2 0.239694 |
| 2 1.361273 -1.893519 0.307613 -0.119003 | 3 0.563254 |
| 3 -0.103433 -1.058175 -0.587307 -0.114262 | 4 2.123950 |
| 4 -0.612298 0.873136 -0.607457 1.047772 | 5 0.341554 |
| | 6 -0.075717 |
| | 7 -0.606742 |
| | Name: A, dtype: float64 |
|--------------------------------------------|-------------------------|
- 属性访问
可以使用属性运算符.来选择列。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(8, 4), columns = [‘A‘, ‘B‘, ‘C‘, ‘D‘])
|-------------------------|
| print (df.A) |
|-------------------------|
| 0 0.104820 |
| 1 -1.206600 |
| 2 0.469083 |
| 3 -0.821226 |
| 4 -1.238865 |
| 5 1.083185 |
| 6 -0.827833 |
| 7 -0.199558 |
| Name: A, dtype: float64 |
|-------------------------|
df = pd.DataFrame({‘a‘:[11,22,33],‘b‘:[44,55,66]})
df.rename(columns={‘a‘:‘c‘})
df.columns = [‘c‘,‘b‘]
迭代(key,value)对,将每个列作为键,将值与值作为键和列值迭代为Series对象。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,3),columns=[‘col1‘,‘col2‘,‘col3‘])
for key,value in df.iteritems():
print (key,value)
>>>col1 0 0.802390
1 0.324060
2 0.256811
3 0.839186
Name: col1, dtype: float6
将行迭代为(索引,系列)对,iterrows()返回迭代器,产生每个索引值以及包含每行数据的序列。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,3),columns = [‘col1‘,‘col2‘,‘col3‘])
for row_index,row in df.iterrows():
print (row_index,row)
>>> 0 col1 1.529759
col2 0.762811
col3 -0.634691
Name: 0, dtype: float64
以namedtuples的形式迭代行,itertuples()方法将为DataFrame中的每一行返回一个产生一个命名元组的迭代器。
元组的第一个元素将是行的相应索引值,而剩余的值是行值。
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(4,3),columns = [‘col1‘,‘col2‘,‘col3‘])
for row in df.itertuples():
print (row)
>>> Pandas(Index=0, col1=1.5297586201375899, col2=0.76281127433814944, col3=- 0.6346908238310438)
使用sort_index()方法,通过传递axis参数和排序顺序,可以对DataFrame进行排序。 默认情况下,按照升序对行标签进行排序。
通过传递axis参数值为0或1,可以对列标签进行排序。 默认情况下,axis = 0,逐行排列。
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame(np.random.randn(10,2),index=[1,4,6,2,3,5,9,8,0,7],columns = [‘col2‘,‘col1‘])
sorted_df1 = unsorted_df.sort_index()
sorted_df2 = unsorted_df.sort_index(axis=1)
print (sorted_df1)
print (sorted_df2)
sort_values()是按值排序的方法。它接受一个by参数,它将使用要与其排序值的DataFrame的列名称。
sort_values()提供了从mergeesort,heapsort和quicksort中选择算法的一个配置。Mergesort是唯一稳定的算法。
import pandas as pd
import numpy as np
unsorted_df = pd.DataFrame({‘col1‘:[2,1,1,1],‘col2‘:[1,3,2,4]})
sorted_df1 = unsorted_df.sort_values(by=‘col1‘)
sorted_df2 = unsorted_df.sort_values(by=‘col1‘ ,kind=‘mergesort‘)
print (sorted_df1)
print (sorted_df2)
| 函数名 | 描述 |
| lower() | 将Series/Index中的字符串转换为小写。 |
| upper() | 将Series/Index中的字符串转换为大写。 |
| len() | 计算字符串长度。 |
| strip() | 从两侧的系列/索引中的每个字符串中删除空格(包括换行符)。 |
| split(‘ ‘) | 用给定的模式拆分每个字符串。 |
| cat(sep=‘ ‘) | 使用给定的分隔符连接系列/索引元素。 |
| get_dummies() | 返回具有单热编码值的数据帧(DataFrame)。 |
| contains(pattern) | 如果元素中包含子字符串,则返回每个元素的布尔值True,否则为False。 |
| replace(a,b) | 将值a替换为值b。 |
| repeat(value) | 重复每个元素指定的次数。 |
| count(pattern) | 返回模式中每个元素的出现总数。 |
| startswith(pattern) | 如果系列/索引中的元素以模式开始,则返回true。 |
| endswith(pattern) | 如果系列/索引中的元素以模式结束,则返回true。 |
| find(pattern) | 返回模式第一次出现的位置。 |
| findall(pattern) | 返回模式的所有出现的列表。 |
| swapcase() | 变换字母大小写。 |
| islower() | 检查系列/索引中每个字符串中的所有字符是否小写,返回布尔值。 |
| isupper() | 检查系列/索引中每个字符串中的所有字符是否大写,返回布尔值。 |
| isnumeric() | 检查系列/索引中每个字符串中的所有字符是否为数字,返回布尔值。 |
| 函数名 | 描述 | 函数名 | 描述 |
| count() | 非空观测数量 | sum() | 请求轴的值的总和。 默认情况下,轴为索引(axis=0) |
| mean() | 所有值的平均值 | median() | 所有值的中位数 |
| mode() | 值的模值 | std() | 值的标准偏差 |
| min() | 所有值中的最小值 | max() | 所有值中的最大值 |
| abs() | 绝对值 | prod() | 数组元素的乘积 |
| cumsum() | 累计总和 | cumprod() | 累计乘积 |
| pct_change() | 此函数将每个元素与其前一个元素进行比较,并计算变化百分比。pct_change()对列进行操作; 如果想应用到行上,那么可使用axis = 1参数。 | ||
| cov() | 协方差适用于系列数据。Series对象有一个方法cov用来计算序列对象之间的协方差。NA将被自动排除。当应用于DataFrame时,协方差方法计算所有列之间的协方差(cov)值。 | ||
| corr() | 相关性显示了任何两个数值(系列)之间的线性关系。有多种方法来计算pearson(默认),spearman和kendall之间的相关性。如果DataFrame中存在任何非数字列,则会自动排除。 | ||
| rank() |
数据排名为元素数组中的每个元素生成排名。在关系的情况下,分配平均等级。默认为升序 -- Rank支持不同的tie-breaking方法,用方法参数指定 -average - 并列组平均排序等级;min - 组中最低的排序等级;max - 组中最高的排序等级;first - 按照它们出现在数组中的顺序分配队列 |
||
| describe() | 函数是用来计算有关DataFrame列的统计信息的摘要。 -- include:获取统计参数;object - 汇总字符串列;number - 汇总数字列;all - 汇总所有列 | ||
df[‘Score‘]=[80,90,67] # 增加列元素个数要与元数据列个数一样 ----------------------------------------------------------------------------------------------
col_name=df.columns.tolist() # 将数据框列名全部取出至列表 col_name.insert(2,‘city‘) # 列索引为2的位置插入列"city",刚插入时整列值均为:NaN df=df.reindex(columns=col_name) # 重构索引 df[‘city‘]=[‘北京‘,‘山西‘,‘湖北‘,‘澳门‘] # "city"列重新赋值 ----------------------------------------------------------------------------------------------
df.insert(2,‘score‘,[80,90,100]) # 插入一列 ----------------------------------------------------------------------------------------------
row = [‘11‘,‘22‘,‘33‘] df.iloc[1] = row # 插入一行 ----------------------------------------------------------------------------------------------
new_df = pd.DataFrame(dict) df =df.append(new_df,ignore_index=True) # ignore_index=False,表示不按原来的索引,从0开始自动递增
df = df.drop([‘one‘],axis=1,inplace=True) # 删除数据,axis=1表示删除列,0表示删除行;inplace是否在当前df执行操作
isnull()和notnull()函数,返回布尔值,它们也是Series和DataFrame对象的方法。import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(5, 3), index=[‘a‘, ‘c‘, ‘e‘, ‘f‘,‘h‘],columns=[‘one‘, ‘two‘, ‘three‘])
df = df.reindex([‘a‘, ‘b‘, ‘c‘, ‘d‘, ‘e‘, ‘f‘, ‘g‘, ‘h‘])
print (df[‘one‘].isnull())
print (df[‘one‘].notnull())
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(3, 3), index=[‘a‘, ‘c‘, ‘e‘],columns=[‘one‘,‘two‘, ‘three‘])
df = df.reindex([‘a‘, ‘b‘, ‘c‘])
# 方法1:fillna()函数将非空数据“填充”NA值
print (df.fillna(0))
# pad/fill 填充方法向前;bfill/backfill 填充方法向后
print (df.fillna(method=‘pad‘))
print (df.fillna(method=‘backfill‘))
# 方法2:如果只想排除缺少的值,则使用dropna函数和axis参数。 默认情况下,axis = 0,即在行上应用,这意味着如果行内的任何值是NA,那么整个行被排除。
print (df.dropna())
# 方法3:replace()函数替换NA值
print(df.repalce())
df.duplicated() # 判断每一行是否重复
df.drop_duplicates() # 去除全部重复行
df.drop_duplicates([‘A‘]) # 去除指定列重复行
df.drop_duplicates([‘A‘],keep=‘last‘) # 保留重复行中最后一行
- join
df1、df2、df3
df1.join(df2,how=‘left‘) # 左连接
df1.join(df2,how=‘right‘) # 右连接
df1.join(df2,how=‘outer‘) # 外连接
df1.join([df2,df3]) # 合并多个DataFrame
df1、df2
示例:pd.merge(df1,df2,how=‘right‘)
pd.merge(left, right, how=‘inner‘, on=None, left_on=None, right_on=None,left_index=False, right_index=False, sort=True)
# left - 一个DataFrame对象。
# right - 另一个DataFrame对象。
# on - 列(名称)连接,必须在左和右DataFrame对象中存在(找到)。
# left_on - 左侧DataFrame中的列用作键,可以是列名或长度等于DataFrame长度的数组。
# right_on - 来自右的DataFrame的列作为键,可以是列名或长度等于DataFrame长度的数组。
# left_index - 如果为True,则使用左侧DataFrame中的索引(行标签)作为其连接键。 在具有MultiIndex(分层)的DataFrame的情况下,级别的数量必须与来自右DataFrame的连接键的数量相匹配。
# right_index - 与右DataFrame的left_index具有相同的用法。
# how - 它是left, right, outer以及inner之中的一个,默认为内inner。 下面将介绍每种方法的用法。
# sort - 按照字典顺序通过连接键对结果DataFrame进行排序。默认为True,设置为False时,在很多情况下大大提高性能。
- contact()
pd.concat(objs,axis=0,join=‘outer‘,join_axes=None,ignore_index=False)
# objs - 这是Series,DataFrame或Panel对象的序列或映射。axis - {0,1,...},默认为0,这是连接的轴。
# join - {‘inner‘, ‘outer‘},默认inner。如何处理其他轴上的索引。联合的外部和交叉的内部。
# ignore_index − 布尔值,默认为False。如果指定为True,则不要使用连接轴上的索引值。结果轴将被标记为:0,...,n-1。j
# oin_axes - 这是Index对象的列表。用于其他(n-1)轴的特定索引,而不是执行内部/外部集逻辑。
========================================================================================================
df1、df2
res = pd.concat([df1,df2],axins=1) # 按行合并
res = pd.concat([df1,df2],axis=0,ignore_index=True) # 按列合并
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randn(10, 4),
index = pd.date_range(‘1/1/2000‘, periods=10),
columns = [‘A‘, ‘B‘, ‘C‘, ‘D‘])
r = df.rolling(window=3,min_periods=1)
# 在整个数据框上应用聚合
print r.aggregate(np.sum)
# 在数据框的单个列上应用聚合
print (r[‘A‘].aggregate(np.sum))
# 在DataFrame的多列上应用聚合
print (r[[‘A‘,‘B‘]].aggregate(np.sum))
# 在DataFrame的单个列上应用多个函数
print (r[‘A‘].aggregate([np.sum,np.mean]))
# 在DataFrame的多列上应用多个函数
print (r[[‘A‘,‘B‘]].aggregate([np.sum,np.mean]))
# 将不同的函数应用于DataFrame的不同列
print (r.aggregate({‘A‘ : np.sum,‘B‘ : np.mean}))
分组(groupby)涉及操作包含:分割对象、应用一个函数(聚合:计算汇总统计、转换:执行一些特定于组的操作、过滤:某些情况下丢弃数据)、结合的结果。
df.groupby(‘key’)
df.groupby([‘key1’,’key2’])
df.groupby(key,axis=1)
# 查看分组
df.groupby(‘Team‘).groups
import pandas as pd
ipl_data = {‘Team‘: [‘Riders‘, ‘Riders‘, ‘Devils‘, ‘Devils‘, ‘Kings‘,
‘kings‘, ‘Kings‘, ‘Kings‘, ‘Riders‘, ‘Royals‘, ‘Royals‘, ‘Riders‘],
‘Rank‘: [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
‘Year‘: [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
‘Points‘:[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
grouped = df.groupby(‘Year‘)
for name,group in grouped:
print (name)
print (group)
import pandas as pd
import numpy as np
ipl_data = {‘Team‘: [‘Riders‘, ‘Riders‘, ‘Devils‘, ‘Devils‘, ‘Kings‘,
‘kings‘, ‘Kings‘, ‘Kings‘, ‘Riders‘, ‘Royals‘, ‘Royals‘, ‘Riders‘],
‘Rank‘: [1, 2, 2, 3, 3,4 ,1 ,1,2 , 4,1,2],
‘Year‘: [2014,2015,2014,2015,2014,2015,2016,2017,2016,2014,2015,2017],
‘Points‘:[876,789,863,673,741,812,756,788,694,701,804,690]}
df = pd.DataFrame(ipl_data)
grouped = df.groupby(‘Team‘)
# 选择一个分组
print(grouped.get_group(2014))
# 聚合
# 聚合函数为每个组返回单个聚合值。当创建了分组(group by)对象,就可以对分组数据执行多个聚合操作。
print (grouped.agg(np.size))
# 一次应用多个聚合函数
agg = grouped[‘Points‘].agg([np.sum, np.mean, np.std])
# 转换
# 分组或列上的转换返回索引大小与被分组的索引相同的对象。因此,转换应该返回与组块大小相同的结果。
# 过滤
# 过滤过滤根据定义的标准过滤数据并返回数据的子集。filter()函数用于过滤数据。
filter = df.groupby(‘Team‘).filter(lambda x: len(x) >= 3)
# 获取当前的日期和时间
datetime.now()
# 创建一个时间戳
time = pd.Timestamp(‘2018-11-01‘)
time = pd.Timestamp(1588686880,unit=‘s‘)
# 创建一个时间范围
time = pd.date_range("12:00", "23:59", freq="30min").time
# 改变时间的频率
time = pd.date_range("12:00", "23:59", freq="H").time
# 转换为时间戳
time = pd.to_datetime(pd.Series([‘Jul 31, 2009‘,‘2019-10-10‘, None]))
date.range()函数就可以创建日期序列。 默认情况下,范围的频率是天。
import pandas as pd
datelist = pd.date_range(‘2020/11/21‘, periods=5)
print(datelist)
# 更改日期频率
datelist = pd.date_range(‘2020/11/21‘, periods=5,freq=‘M‘)
print(datelist)
时间差(Timedelta)是时间上的差异,以不同的单位来表示。例如:日,小时,分钟,秒。它们可以是正值,也可以是负值。
import pandas as pd
# 通过传递字符串,可以创建一个timedelta对象。
timediff = pd.Timedelta(‘2 days 2 hours 15 minutes 30 seconds‘)
# 通过传递一个整数值与指定单位,这样的一个参数也可以用来创建Timedelta对象。
timediff = pd.Timedelta(6,unit=‘h‘)
# 通过数据偏移也可用于构建Timedelta对象。
timediff = pd.Timedelta(days=2)
datetime64 [ns]系列或在时间戳上减法操作来构造timedelta64 [ns]系列。import pandas as pd
s = pd.Series(pd.date_range(‘2018-1-1‘, periods=3, freq=‘D‘))
td = pd.Series([ pd.Timedelta(days=i) for i in range(3) ])
df = pd.DataFrame(dict(A = s, B = td))
# 相加操作
df[‘C‘] = df[‘A‘]+df[‘B‘]
df[‘D‘] = df[‘C‘]-df[‘B‘]
Series和DataFrame上的这个功能只是使用matplotlib库的plot()方法的简单包装实现。如果索引由日期组成,则调用gct().autofmt_xdate()来格式化x轴。
import pandas as pd
import numpy as np
df = pd.DataFrame()
- 条形图
df.plot.bar() # bar()方法生成竖直条形图,stacked = True,生成堆积条形图
df.plot.barh() # barh()方法生成水平条形图,stacked = True,生成堆积条形图
- 直方图
df.plot.hist() # 指定bins的数量值
- 箱型图
df.plot.box()
- 区域块图形
df.plot.area()
- 散点图
df.plot.scatter()
- 饼状图
df.plot.pie()
标签:describe aggregate 方式 tuple 左连接 信息 image merge first
原文地址:https://www.cnblogs.com/Iceredtea/p/12215975.html