标签:att lang sum gif sda r文件 osd rac app
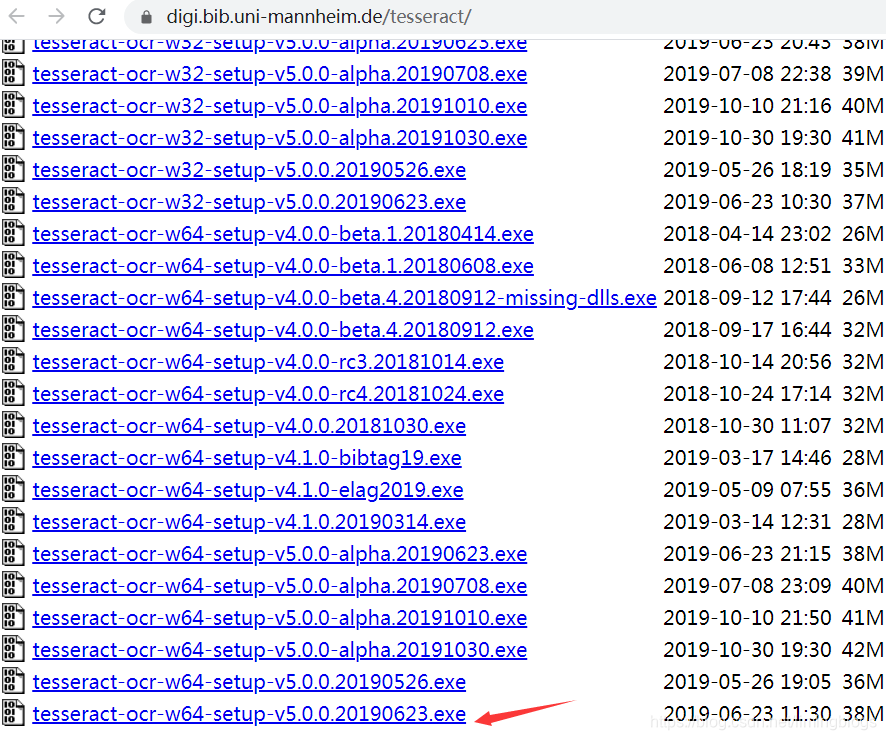
1,下载安装Tesseract-OCR 安装,链接地址https://digi.bib.uni-mannheim.de/tesseract/
![]() ?
?
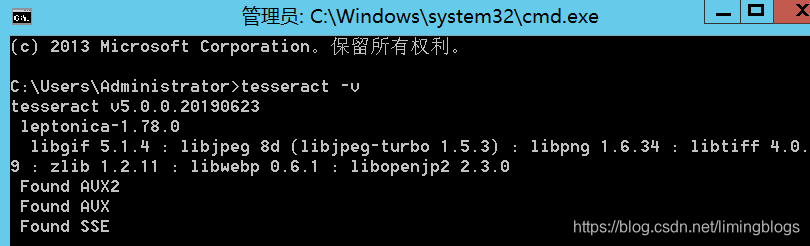
2,安装成功 tesseract -v
注意:安装后,要添加系统环境变量
![]() ?
?
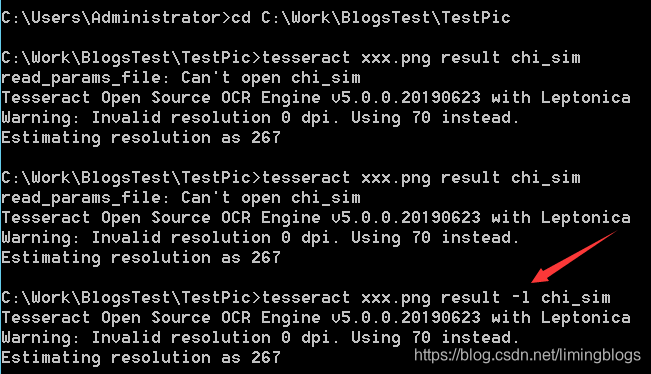
3,cmd指定目录到 cd C:\Work\BlogsTest\TestPic,要识别图片的文件夹 识别:tesseract test.png result -l chi_sim
![]() ?
?
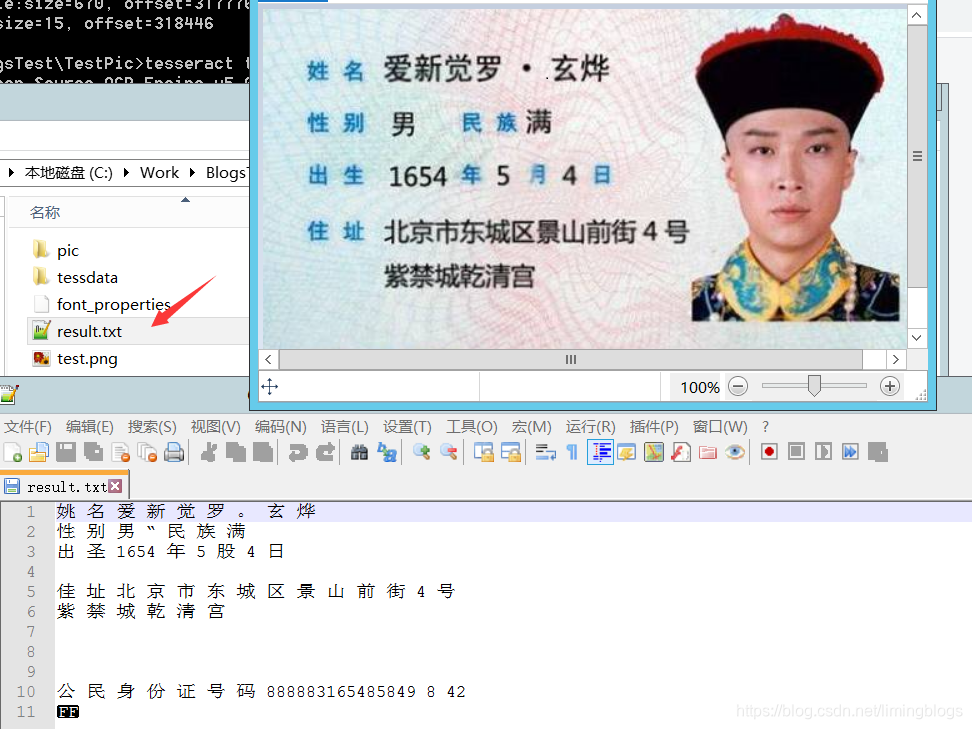
识别成功的效果,result.txt文件会自动生成
![]() ?
?
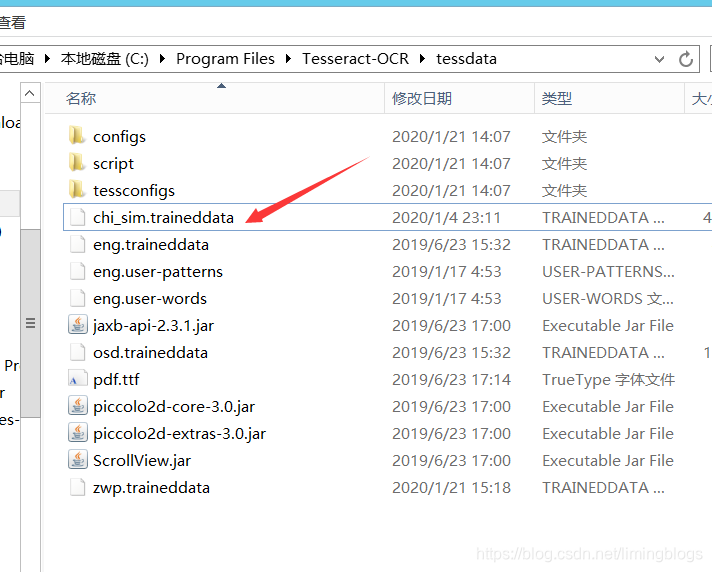
要注意:Tesseract-OCR的安装目录要包含识别中文的字符集chi_sim.traineddata,可以在GitHub下载https://github.com/tesseract-ocr/tessdata
![]() ?
?
4,可见第3步的识别效果不是很好,想到通过训练自定义字库,提高图片的识别效果
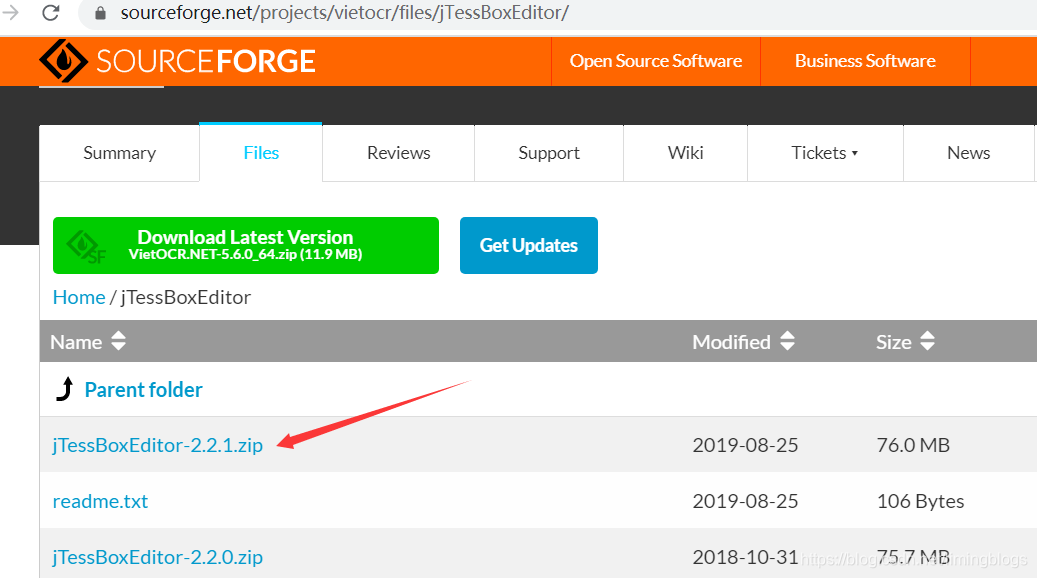
(0)下载安装jTessBoxEditor,https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
![]() ?
?
注意要安装JavaRuntime
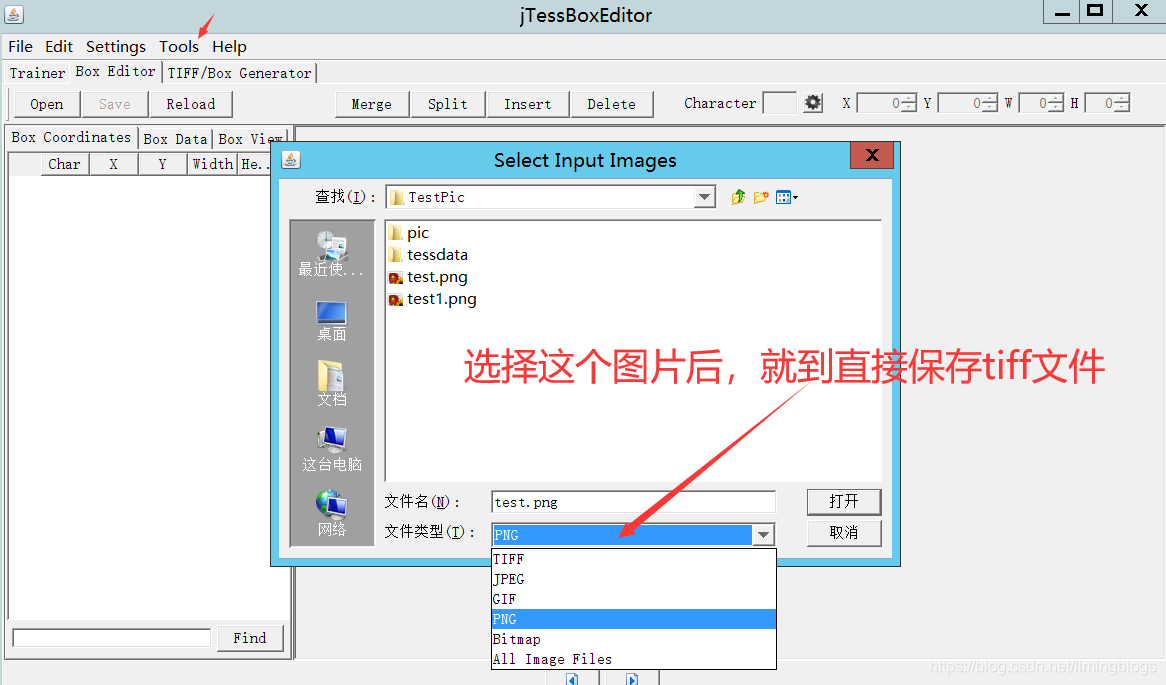
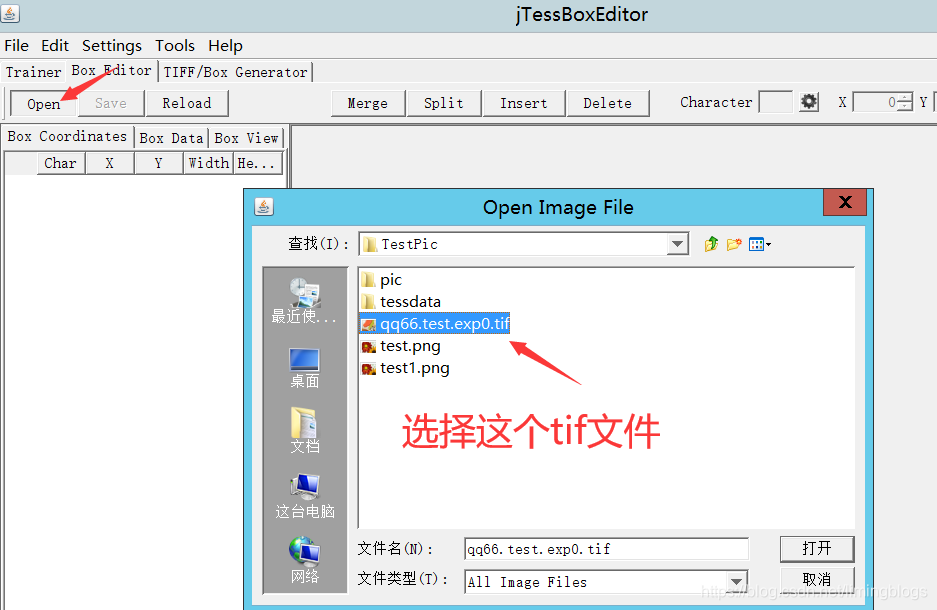
(1)打开jTessBoxEditor,选择Tools->Merge TIFF,进入训练样本所在文件夹,选中要参与训练的样本图片:
![]() ?
?
(2)点击 “打开” 后弹出保存对话框,选择保存在当前路径下,文件命名为 “qq66.test.exp0.tif” ,格式只有一种 “TIFF” 可选。
tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言,fontname是字体,num为自定义数字。
比如我们要训练自定义字库 qq66,字体名test,那么我们把图片文件命名为 qq66.test.exp0.tif
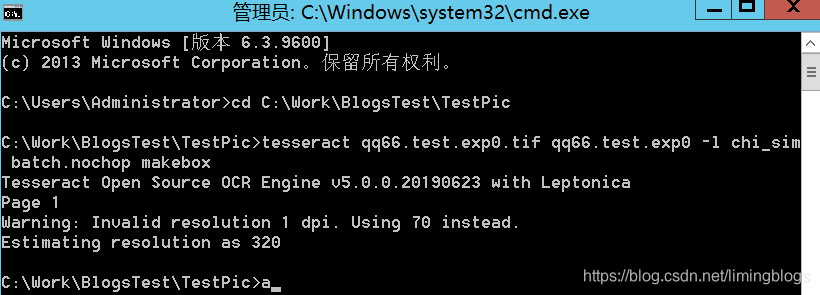
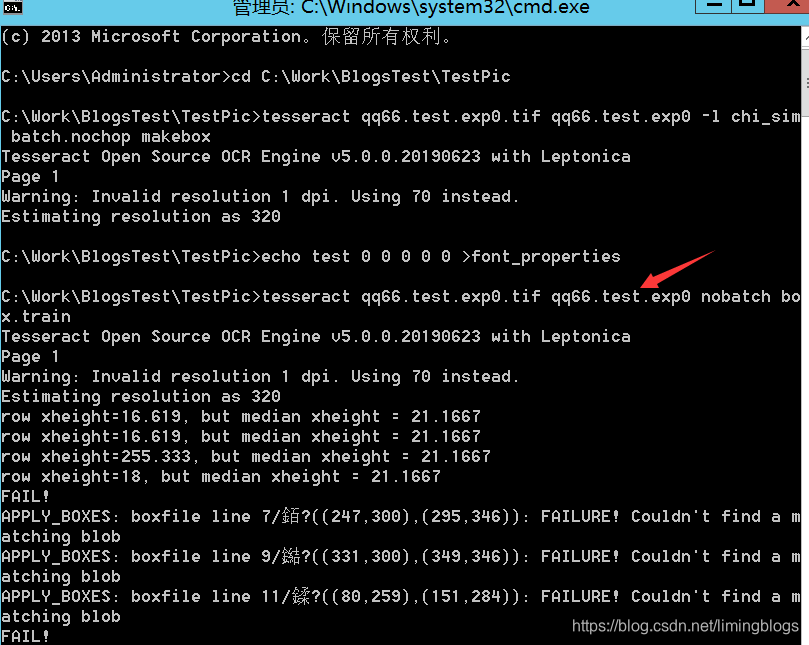
(3)使用tesseract生成.box文件
tesseract qq66.test.exp0.tif qq66.test.exp0 -l chi_sim --psm 6 batch.nochop makebox
![]() ?
?
注意:--psm的语法,数字对应不同的 页面分割模式。
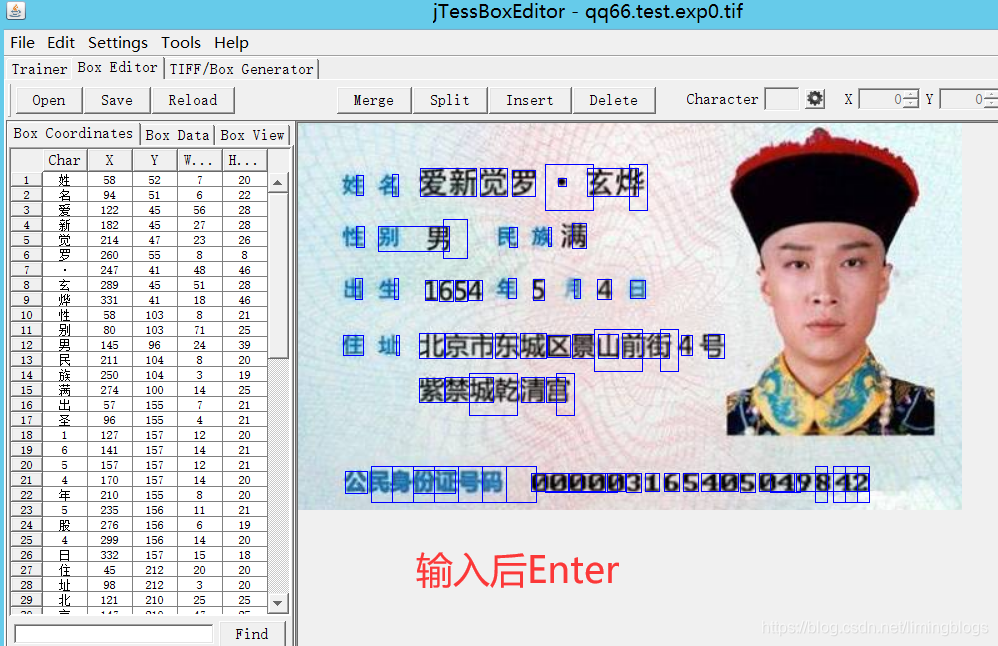
(4)使用jTessBoxEditor矫正.box文件的错误
![]() ?
?
打开后矫正后,点击 save
![]() ?
?
(5)生成font_properties文件:(该文件没有后缀名)
执行命令,执行完之后,会在当前目录生成font_properties文件
echo test 0 0 0 0 0 >font_properties
也可以手工新建一个名为font_properties的文本文件,输入内容 “test 0 0 0 0 0” 表示字体test的粗体、倾斜等共计5个属性。这里的“test”必须与“qq66.test.exp0.box”中的“test”名称一致。
(6)使用tesseract生成.tr训练文件
执行下面命令,执行完之后,会在当前目录生成qq66.test.exp0.tr文件。
tesseract qq66.test.exp0.tif qq66.test.exp0 nobatch box.train
![]() ?
?
(7)生成字符集文件:
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
unicharset_extractor qq66.test.exp0.box
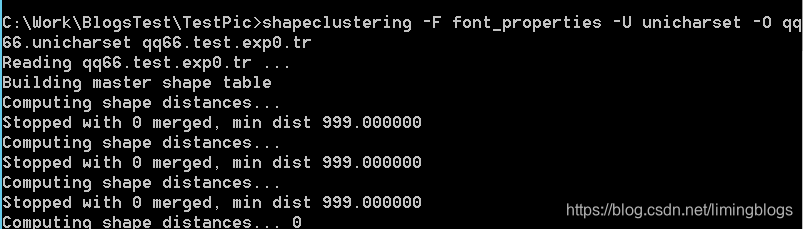
(8)生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和 zwp.unicharset 两个文件。
shapeclustering -F font_properties -U unicharset -O qq66.unicharset qq66.test.exp0.tr
![]() ?
?
(8)生成聚字符特征文件
执行下面命令,会生成 inttemp、pffmtable、shapetable和zwp.unicharset四个文件。
mftraining -F font_properties -U unicharset -O qq66.unicharset qq66.test.exp0.tr
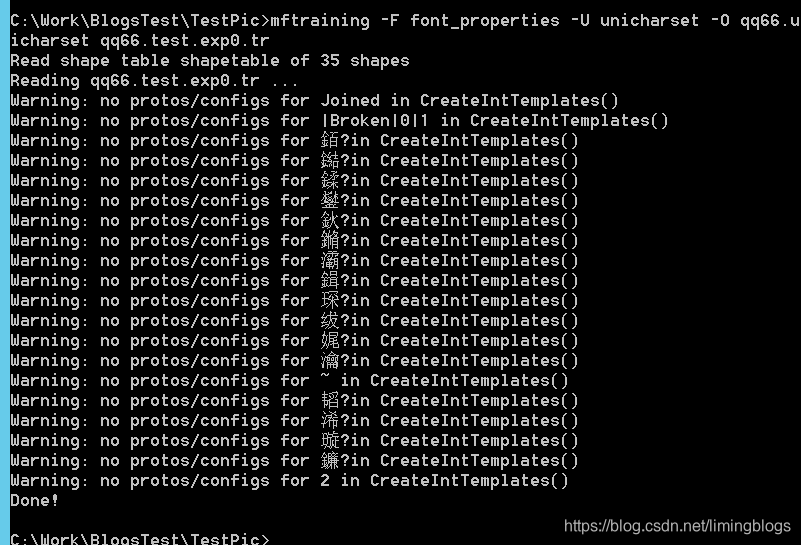
![]() ?
?
(9)生成字符正常化特征文件
执行下面命令,会生成 normproto 文件。
cntraining qq66.test.exp0.tr

![]() ?
?
(10)文件重命名
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为qq66.inttemp、qq66.pffmtable、qq66.shapetable和qq66.normproto
(11)合并训练文件
执行下面命令,会生成qq66.traineddata文件。
combine_tessdata qq66.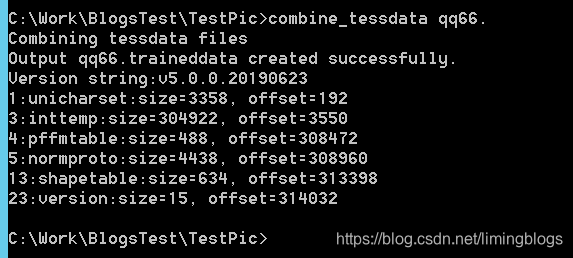
![]() ?
?
最后文件目录
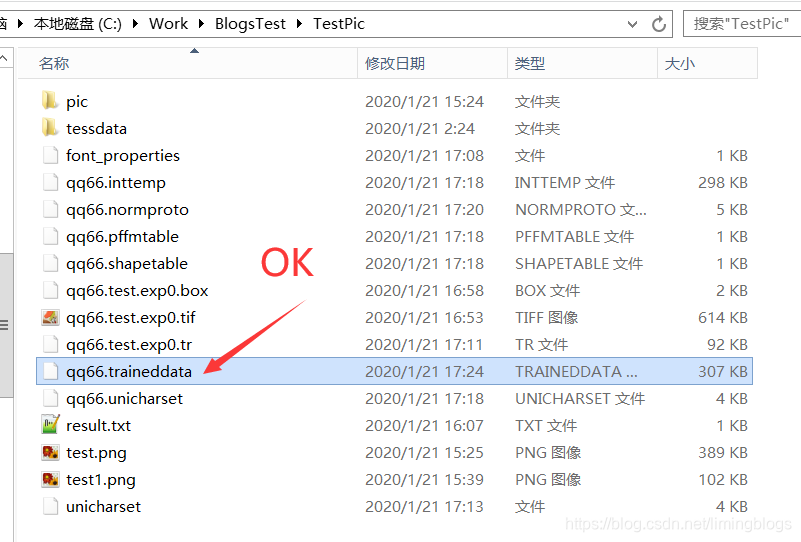
![]() ?
?
5,用新生成的qq66.traineddata字符集,重新识别身份证
6,可以同时选择多个不同的样本生成box文件

![]() ?
?
7,在原有训练数据的基础上,加入新的字符训练信息
经研究找到实用合并方法(红色部分为示例,实际应为你自己生成的文件名):
在新的训练数据生成.box 和.tr文件后,
生成字符集 unicharset_extractor add.font.exp0.box new.font.exp0.box
合并训练数据(.tr)
mftraining -F font_properties -U unicharset -O added.unicharset add.font.exp0.tr new.font.exp0.tr
聚合所有的tr文件:
cntraining add.font.exp0.tr new.font.exp0.tr
8,设置图片分割模式
Page segmentation modes:
0 = Orientation and script detection (OSD) only.
1 = Automatic page segmentation with OSD.
2 = Automatic page segmentation, but no OSD, or OCR
3 = Fully automatic page segmentation, but no OSD. (Default)
4 = Assume a single column of text of variable sizes.
5 = Assume a single uniform block of vertically aligned text.
6 = Assume a single uniform block of text.
7 = Treat the image as a single text line.
8 = Treat the image as a single word.
9 = Treat the image as a single word in a circle.
10 = Treat the image as a single character.
例如:
tesseract test.png result -l chi_sim -psm 7 nobatch

![]() ?
?
Tesseract-OCR-v5.0中文识别,训练自定义字库,提高图片的识别效果
标签:att lang sum gif sda r文件 osd rac app
原文地址:https://www.cnblogs.com/channel9/p/12227166.html