标签:lin 设备 mic VID 结构体 pci bsp 输入 memory
遇到cuda程序,开始理解学习cuda概念及使用
Cuda 有硬件概念 SP (streaming processor),SM(streaming multiprocessor)
有方便编程的软件概念thread, blocks, grid
各个概念的解释:
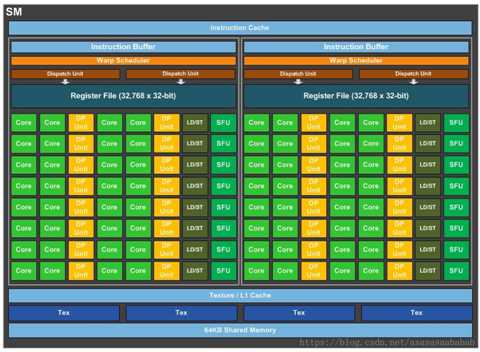
SP:流处理器,最基本的处理单元,也称为CUDA core,最后具体的指令和任务都是在SP上处理的。GPU进行并行处理,是很多个SP同时做处理。
SM:多个SP加上其他的资源组成的一个streaming multiprocessor。其他资源如 warp scheduler, register, shared memory等。SM可以看做GPU的心脏,register, shared memory是SM的稀缺资源,CUDA将这些资源分配给驻留在SM中的threads(线程)。
以上的硬件结构如下图所示,图中每一个绿色的小块代表一个SP。一个SM包含对个SP。
Thread:是操作系统能够进行运算调度的最小单位。一个CUDA的并行程序会被多个threads来执行。
Blocks:数个threads会被群组成一个block,同一个block中的threads可以同步,也就可以通过shared memory通信。
Grid:多个block会构成grid。
软硬结合的理解:
1,个kernel启动一个grid,一个grid包含几个blocks,一个block包含多个threads。其中block中除了包含threads,还有线程需要使用的共同资源。
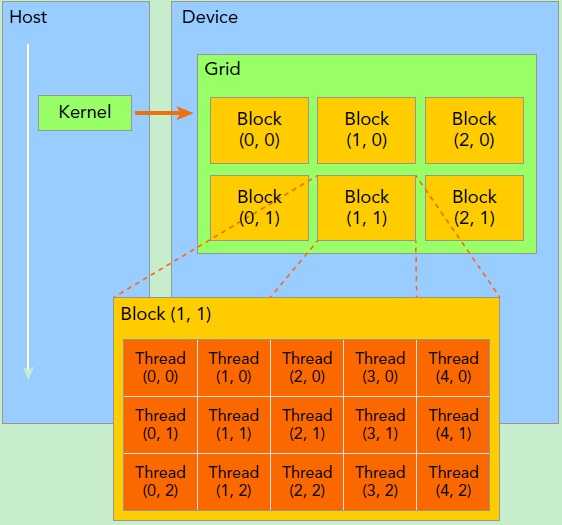
GPU并不是一个独立运行的计算平台,而需要与CPU协同工作,可以看成是CPU的协处理器,因此当我们在说GPU并行计算时,其实是指的基于CPU+GPU的异构计算架构。在异构计算架构中,GPU与CPU通过PCIe总线连接在一起来协同工作,CPU所在位置称为为主机端(host),而GPU所在位置称为设备端(device)。
kernel在device上执行时实际上是启动很多线程,(关于kernel的理解这篇文章解释的很容易懂:https://zhuanlan.zhihu.com/p/34587739)一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。线程两层组织结构如下图所示,这是一个gird和block均为2-dim的线程组织。grid和block都是定义为dim3类型的变量,dim3可以看成是包含三个无符号整数(x,y,z)成员的结构体变量,在定义时,缺省值初始化为1。因此grid和block可以灵活地定义为1-dim,2-dim以及3-dim结构,对于图中结构(主要水平方向为x轴),定义的grid和block如下所示,kernel在调用时也必须通过执行配置<<<grid, block>>>来指定kernel所使用的线程数及结构。
编程中矩阵对线程和block个数的设置:
给kernel传参数的方法:
dim3 grid(3, 2);
dim3 block(5, 3);
kernel_fun<<< grid, block >>>(prams...); 设置kernel_fun核函数的参数及输入变量
使用示例:
// Kernel定义 __global__ void MatAdd(float A[N][N], float B[N][N], float C[N][N]) { int i = blockIdx.x * blockDim.x + threadIdx.x; int j = blockIdx.y * blockDim.y + threadIdx.y; if (i < N && j < N) C[i][j] = A[i][j] + B[i][j]; } int main() { ... // Kernel 线程配置 dim3 threadsPerBlock(16, 16); dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y); // kernel调用 MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C); ... }
kernel的这种线程组织结构天然适合vector,matrix等运算。
参考网址:
https://zhuanlan.zhihu.com/p/34587739
https://blog.csdn.net/asasasaababab/article/details/80447254
https://blog.csdn.net/qq_41598072/article/details/82877655
标签:lin 设备 mic VID 结构体 pci bsp 输入 memory
原文地址:https://www.cnblogs.com/xiaoheizi-12345/p/12234078.html