标签:运行 如何 style 十分 操作 共享 集合 特性 并且
在spark程序中,当一个传递给Spark操作(例如map和reduce)的函数在远程节点上面运行时,Spark操作实际上操作的是这个函数所用变量的一个独立副本。这些变量会被复制到每台机器上,并且这些变量在远程机器上的所有更新都不会传递回驱动程序。通常跨任务的读写变量是低效的,但是,Spark还是为两种常见的使用模式提供了两种有限的共享变量:广播变量(broadcast variable)和累加器(accumulator)
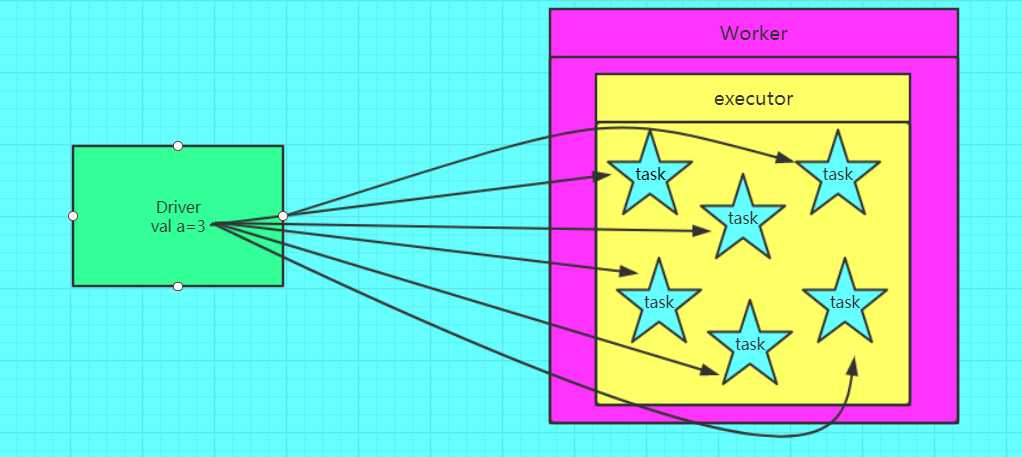
如果我们要在分布式计算里面分发大对象,例如:字典,集合,黑白名单等,这个都会由Driver端进行分发,一般来讲,如果这个变量不是广播变量,那么每个task就会分发一份,这在task数目十分多的情况下Driver的带宽会成为系统的瓶颈,而且会大量消耗task服务器上的资源,如果将这个变量声明为广播变量,那么知识每个executor拥有一份,这个executor启动的task会共享这个变量,节省了通信的成本和服务器的资源。
错误的,不使用广播变量
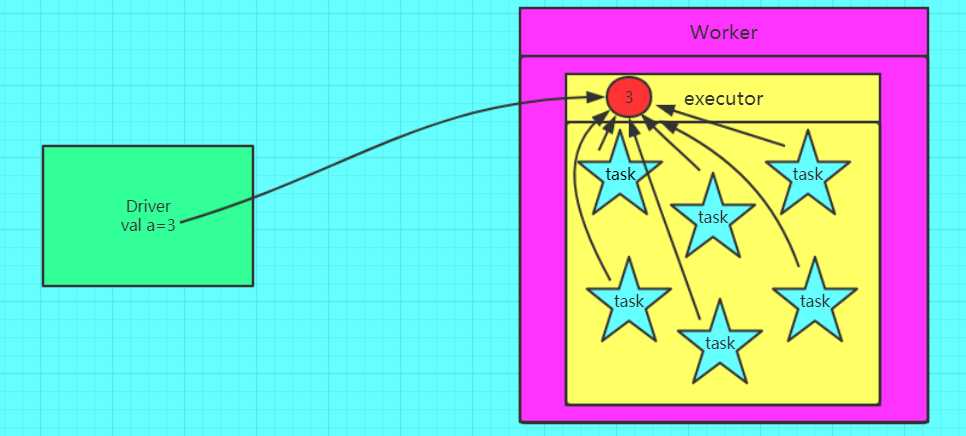
正确的,使用广播变量的情况
val a = 3
val broadcast = sc.broadcast(a)val c = broadcast.value变量一旦被定义为一个广播变量,那么这个变量只能读,不能修改
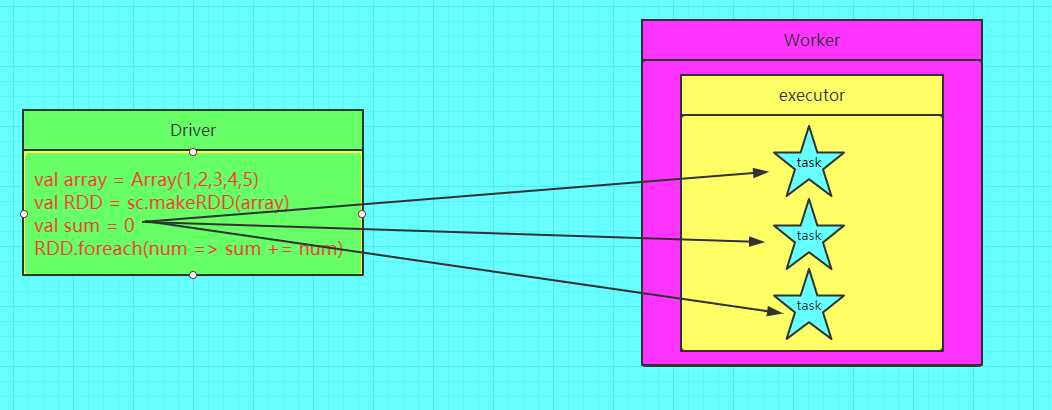
在spark应用程序中,我们经常会有这样的需求,如异常监控,调试,记录符合某特性的数据的数目,这种需求都需要用到计数器,如果一个变量不被声明为一个累加器,那么它将在被改变时不会再driver端进行全局汇总,即在分布式运行时每个task运行的只是原始变量的一个副本,并不能改变原始变量的值,但是当这个变量被声明为累加器后,该变量就会有分布式计数的功能。
错误的图解
正确的图解
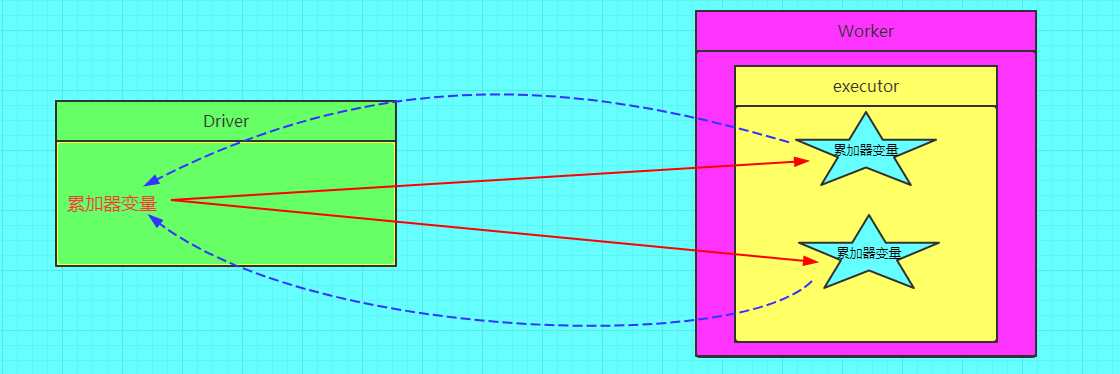
val a = sc.accumulator(0)val b = a.valueSpark学习之路 (四)Spark的广播变量和累加器[转]
标签:运行 如何 style 十分 操作 共享 集合 特性 并且
原文地址:https://www.cnblogs.com/cjunn/p/12232169.html