标签:bsp 模拟 ima img inter 清空 信息 spec nbsp
优先级和抢占机制,解决的是Pod调度失败时该怎么办的问题
正常情况下,当一个Pod调度失败后,它就会被暂时“搁置”起来,直到Pod被更新,或者集群状态发生变化,调度器才会对这个Pod进行重新调度
特殊要求的场景:
当一个高优先级的Pod调度失败后,该Pod并不会被“搁置”,而是会“挤走”某个Node上的一些低优先级的Pod.这样就保证这个高优先级Pod的调度成功
需要在Kubernetes里提交一个PriorityClass资源的定义
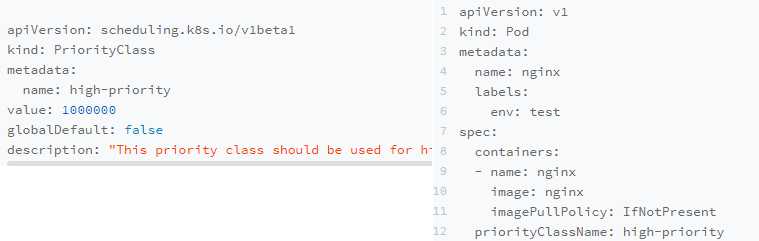
Kubernetes规定优先级是一个32bit的整数,最大值不超过1000000000(10 亿,1 billion),并且值越大代表优先级越高.而超出10亿的值,其实是被Kubernetes保留下来分配给系统 Pod 使用的.这样做的目的,就是保证系统Pod不会被用户抢占掉
YAML文件里的globalDefault被设置为true的话,那就意味着这个PriorityClass的值会成为系统的默认值.而如果这个值是false就表示我们只希望声明使用该PriorityClass的Pod拥有值为1000000的优先级,对于没有声明PriorityClass的Pod来说它们的优先级就是0
在创建了PriorityClass对象之后,Pod 就可以声明使用它.Kubernetes的PriorityAdmissionController就会自动将这个Pod的spec.priority字段设置为PriorityClass的值
优先级的体现:
当Pod拥了优先级之后,高优先级的Pod就可能会比低优先级的Pod提前出队,从而尽早完成调度过程.这个过程,就是“优先级”这个概念在 Kubernetes里的主要体现
抢占的体现:
当一个高优先级的Pod调度失败的时候,调度器的抢占能力就会被触发.这时,调度器就会试图从当前集群里寻找一个节点,使得当这个节点上的一个或者多个低优先级 Pod 被删除后,待调度的高优先级Pod 就可以被调度到这个节点上.这个过程,就是“抢占”这个概念在Kubernetes里的主要体现
当上述抢占过程发生时,抢占者并不会立刻被调度到被抢占的Node上.调度器只会将抢占者的spec.nominatedNodeName字段,设置为被抢占的Node的名字.然后,抢占者会重新进入下一个调度周期,然后在新的调度周期里来决定是不是要运行在被抢占的节点上.即使在下一个调度周期,调度器也不会保证抢占者一定会运行在被抢占的节点上.原因如下:
1.调度器只会通过标准的DELETE API来删除被抢占的Pod,所以这些Pod必然是有一定的“优雅退出”时间(默认是 30s)的,而在这段时间里,其他的节点也是有可能变成可调度的或者直接有新的节点被添加到这个集群中来.所以,鉴于优雅退出期间,集群的可调度性可能会发生的变化
2.在抢占者等待被调度的过程中,如果有其他更高优先级的Pod也要抢占同一个节点,那么调度器就会清空原抢占者的spec.nominatedNodeName字段,从而允许更高优先级的抢占者执行抢占,并且这也就使得原抢占者也有机会去重新抢占其他节点
抢占发生的原因,一定是一个高优先级的Pod调度失败
抢占算法的一个最重要的设计,就是在调度队列的实现里,使用了两个不同的队列
第一个队列activeQ:
凡是在activeQ里的Pod,都是下一个调度周期需要调度的对象.所以,当你在 Kubernetes 集群里新创建一个Pod的时候,调度器会将这个Pod入队到activeQ里面.而我在前面提到过的,调度器不断从队列里出队(Pop)一个Pod 进行调度,实际上都是从activeQ里出队的
第二个队列unschedulableQ:
专门用来存放调度失败的Pod,而这里的一个关键点就在于,当一个unschedulableQ里的Pod被更新之后,调度器会自动把这个Pod移动到activeQ里
抢占者调度失败后执行两个操作:
1.抢占者就会被放进unschedulableQ里面
2.调度失败事件会触发调度器为抢占者寻找牺牲者的流程
1.调度器会检查这次失败事件的原因,来确认抢占是不是可以帮助抢占者找到一个新节点.这是因为有很多Predicates的失败是不能通过抢占来解决的.比如,PodFitsHost 算法(负责的是,检查Pod的nodeSelector与Node的名字是否匹配)这种情况下,除非Node 的名字发生变化,否则你即使删除再多的Pod,抢占者也不可能调度成功
2.如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个副本来模拟抢占过程.
调度器会检查缓存副本里的每一个节点,然后从该节点上最低优先级的Pod开始,逐一“删除”这些Pod.而每删除一个低优先级Pod,调度器都会检查一下抢占者是否能够运行在该 Node 上.一旦可以运行,调度器就记录下这个Node的名字和被删除Pod的列表,这就是一次抢占过程的结果了.
当遍历完所有的节点之后,调度器会在上述模拟产生的所有抢占结果里做一个选择,找出最佳结果.而这一步的判断原则,就是尽量减少抢占对整个系统的影响.比如,需要抢占的 Pod 越少越好,需要抢占的Pod的优先级越低越好
在得到了最佳的抢占结果之后,这个结果里的Node,就是即将被抢占的Node.被删除的Pod列表,就是牺牲者
3.调度器开始执行真正的抢占操作
第一步: 调度器会检查牺牲者列表,清理这些Pod所携带的nominatedNodeName字段
第二步: 调度器会把抢占者的nominatedNodeName,设置为被抢占的Node的名字
抢占者Pod的更新操作,就会触发调度器自动把这个Pod从unschedulableQ移动到activeQ里,让抢占者在下一个调度周期重新进入调度流程
接下来,调度器就会通过正常的调度流程来调度抢占者,但是在任何一次正常调度流程中任何一个Pod都有可能被其它新的抢占者抢占,这其中包括了刚unschedulableQ中转成activeQ里的pod 这就是为什么调度器并不保证抢占者一定会运行在当初选定的被抢占的Node上
第三步: 调度器会开启一个Goroutine同步地删除牺牲者
4.对于任何一个待调度的Pod在调度的时候需要处理的特殊额外情况
为某一对Pod和Node执行Predicates算法的时候,如果待检查的Node是一个即将被抢占的节点,即:调度队列里有nominatedNodeName字段值是该Node名字的Pod存在(可以称之为:“潜在的抢占者”)那么调度器就会对这个Node将同样的Predicates算法运行两遍
如果没有潜在抢占者调度一个Pod就只需执行一遍Predicates算法
第一遍: 调度器会假设上述“潜在的抢占者”已经运行在这个节点上,然后执行Predicates算法
由于InterPodAntiAffinity规则的存在.由于InterPodAntiAffinity规则关心待考察节点上所有Pod之间的互斥关系,所以在执行调度算法时必须考虑,如果抢占者已经存在于待考察Node上时,待调度Pod还能不能调度成功
在这里只要考虑那些优先级等于或者大于待调度Pod的抢占者.对于其他较低优先级Pod来说,待调度Pod总是可以通过抢占运行在待考察Node上
第二遍: 调度器会正常执行Predicates算法,即不考虑任何“潜在的抢占者"
因为“潜在的抢占者”最后不一定会运行在待考察的Node上,Kubernetes调度器并不保证抢占者一定会运行在当初选定的被抢占的Node上
只有这两遍Predicates算法都能通过时,这个Pod 和Node才会被认为是可以绑定(bind)的
5.当整个集群发生可能会影响调度结果的变化(添加或者更新Node添加和更新 PV、Service 等)时,调度器会执行MoveAllToActiveQueue的操作,把所调度失败的Pod从unscheduelableQ移动到activeQ里面
6.当一个已经调度成功的Pod被更新时,调度器则会将unschedulableQ里所有跟这个Pod有 Affinity/Anti-affinity关系的Pod,移动到 activeQ 里面
标签:bsp 模拟 ima img inter 清空 信息 spec nbsp
原文地址:https://www.cnblogs.com/yxh168/p/12253513.html