标签:ase 图片 datafile spl 七天 根目录 orm tab data
今天主要学习了spark实验四的内容,实验四主要为RDD编程,本实验的重点为两个编程题
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object RemDup {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("RemDup")
val sc = new SparkContext(conf)
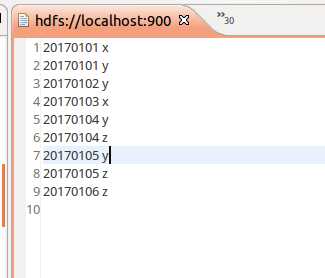
val dataFile1 = "file:///usr/local/spark/mycode/remdup/text1.txt,file:///usr/local/spark/mycode/remdup/text2.txt"
val data = sc.textFile(dataFile1,2)
val res = data.filter(_.trim().length>0).map(line=>(line.trim,"")).partitionBy(new
HashPartitioner(1)).groupByKey().sortByKey().keys
res.saveAsTextFile("result")
} }
import org.apache.spark.SparkContext
import org.apache.spark.SparkContext._
import org.apache.spark.SparkConf
import org.apache.spark.HashPartitioner
object AvgScore {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("AvgScore")
val sc = new SparkContext(conf)
val dataFile = "file:///usr/local/spark/mycode/avgscore/text.txt"
val data = sc.textFile(dataFile,3)
val res = data.filter(_.trim().length>0).map(line=>(line.split(" ")(0).trim(),line.split
(" ")(1).trim().toInt)).partitionBy(new HashPartitioner(1)).groupByKey().map(x => {
var n = 0
var sum = 0.0
for(i <- x._2){
sum = sum + i
n = n +1
}
val avg = sum/n
val format = f"$avg%1.2f".toDouble
(x._1,format)
})
res.saveAsTextFile("result1")
} }
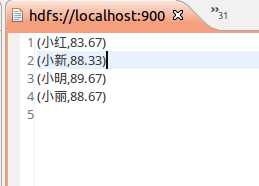
总结:做本实验遇到了一些问题,当看到教程中的代码后,刚开始是很蒙的,因为不知道从哪个路径读取的文件,也不知道该如何读取,后来看了网上的一个实验成功的博客,明白了读取两个文件应该把路径都写出来,还有一个问题就是不知道执行成功命令后输出文件在哪,按照教程中的提示输出结果在本地文件系统中,但是我发现并没有,找了好久都没有这个输出文件,最后在hdfs中找到结果,做这个实验的时候一定注意,输出结果在hdfs的根目录下,打开eclipse即可查看。
标签:ase 图片 datafile spl 七天 根目录 orm tab data
原文地址:https://www.cnblogs.com/ljm-zsy/p/12271051.html