标签:阻塞与非阻塞 分布式系统 系统 src 行操作 提高 线程 授权 node



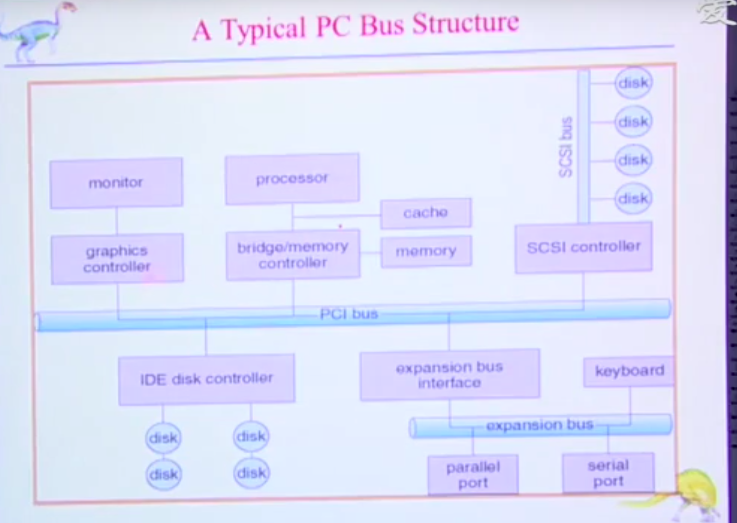
驱动程序对控制器操作,控制器管理具体设备
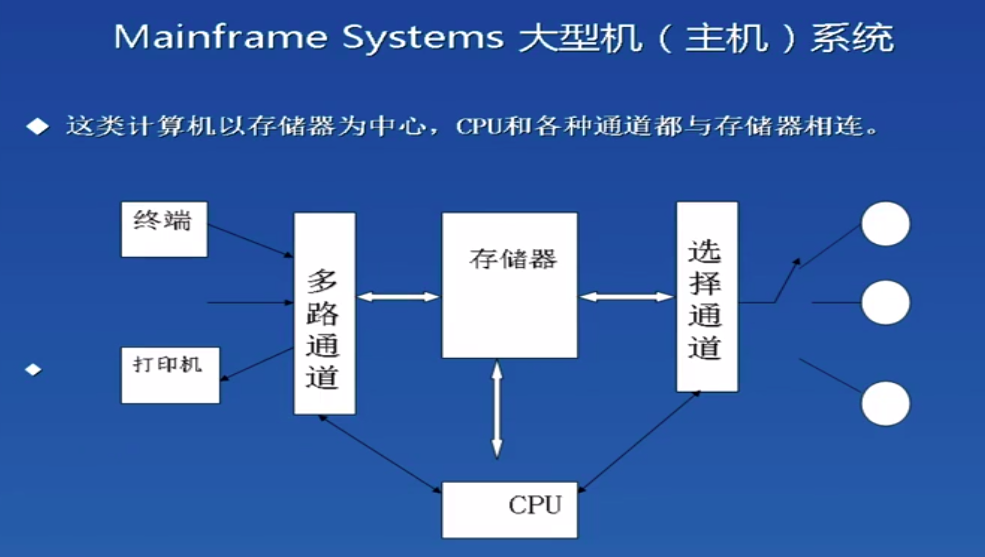
这种使用的是通道,由通道对控制器进行管理
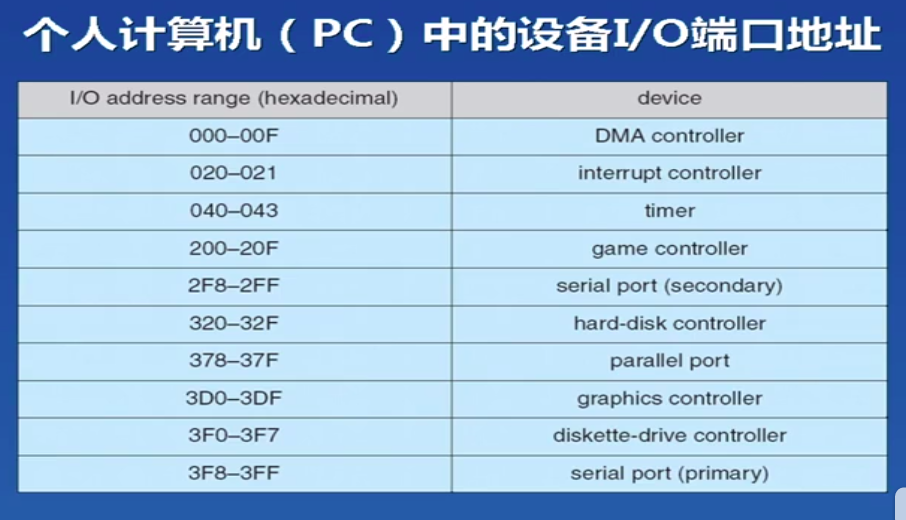

驱动程序的层次:
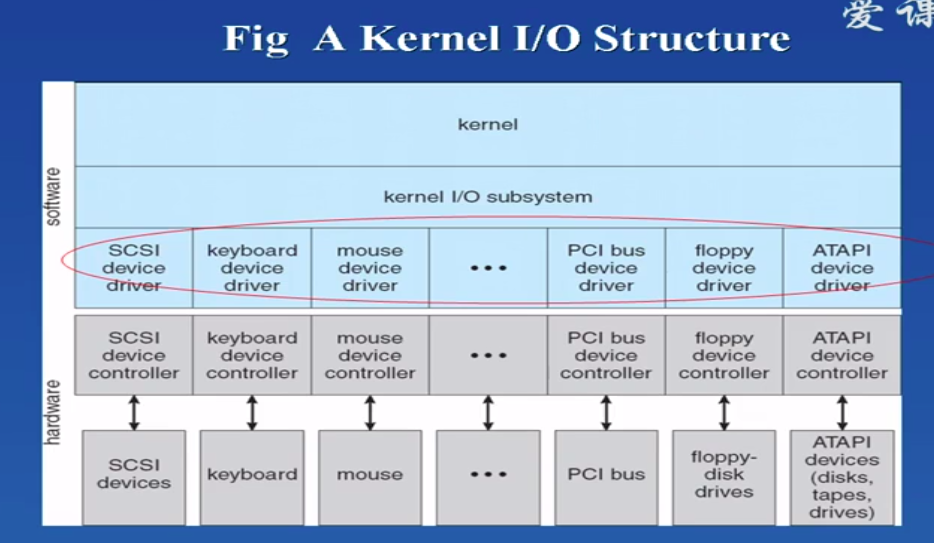
操作系统提供驱动程序的规范,具体驱动大多数由硬件开发商开发

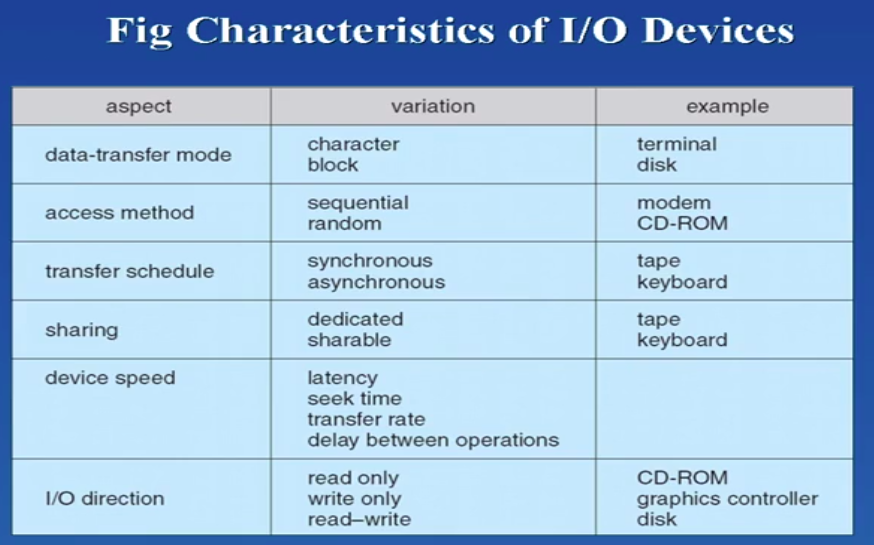
块设备就是以块为单位进行读写的设备,而相应的,字符设备就是以字符为基本单位的设备

所以说,块设备的处理和字符设备的处理是不一样的。Linux将设备分为三类,块设备、字符设备和网络设备


阻塞式IO访问时进程挂起,变为waiting状态
实际上这里讲的不够全面,这个答主说的比较好:
来源:https://www.zhihu.com/question/19732473
作者:严肃
链接:https://www.zhihu.com/question/19732473/answer/20851256
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。“阻塞”与"非阻塞"与"同步"与“异步"不能简单的从字面理解,提供一个从分布式系统角度的回答。
1.同步与异步
同步和异步关注的是消息通信机制 (synchronous communication/ asynchronous communication)
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回。但是一旦调用返回,就得到返回值了。
换句话说,就是由调用者主动等待这个调用的结果。而异步则是相反,调用*在发出之后,这个调用就直接返回了,所以没有返回结果。换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果。而是在调用发出后,被调用者*通过状态、通知来通知调用者,或通过回调函数处理这个调用。
典型的异步编程模型比如Node.js
举个通俗的例子:
你打电话问书店老板有没有《分布式系统》这本书,如果是同步通信机制,书店老板会说,你稍等,”我查一下",然后开始查啊查,等查好了(可能是5秒,也可能是一天)告诉你结果(返回结果)。
而异步通信机制,书店老板直接告诉你我查一下啊,查好了打电话给你,然后直接挂电话了(不返回结果)。然后查好了,他会主动打电话给你。在这里老板通过“回电”这种方式来回调。\2. 阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.阻塞调用是指调用结果返回之前,当前线程会被挂起。调用线程只有在得到结果之后才会返回。
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程。还是上面的例子,
你打电话问书店老板有没有《分布式系统》这本书,你如果是阻塞式调用,你会一直把自己“挂起”,直到得到这本书有没有的结果,如果是非阻塞式调用,你不管老板有没有告诉你,你自己先一边去玩了, 当然你也要偶尔过几分钟check一下老板有没有返回结果。
在这里阻塞与非阻塞与是否同步异步无关。跟老板通过什么方式回答你结果无关。



这里说的buffer在内存中
来源:https://blog.csdn.net/qq_43279637/article/details/85098847
磁盘I/O到
缓冲区中,然后缓冲区数据满了或者足够了之后通过总线放在cpu的高速缓冲区中,然后交给cpu处理,cpu处理完了
之后,回写到高速缓冲中。然后通过总线把数据放在缓冲区中。然后再回写到硬盘中。整个过程有两个甚至更多的缓
冲,为了就是解决性能上的差距。我们这里主要介绍下在磁盘I/O的缓冲技术中的缓冲池。
我们先来简单介绍除了缓冲池之外的其他缓冲技术。
1、单缓冲区:单个缓冲区是指要写到磁盘中的数据先放在缓冲区中,然后再把缓冲区的数据写到磁盘中。或者把磁盘
中的数据写在缓冲区中,然后由处理机取走。这种缓冲区由于要保证数据的正确性,而且缓冲区属于临界资源,需要进
行同步处理。只能有一个进程对数据进行写入或者读取。
2、双缓冲区:双缓冲区是指有两个缓冲区,当数据要写入磁盘的时候,首先写入第一缓冲区(a),第一缓冲区写满之后再
向第二个缓冲区(b)写入。当写入磁盘的时候,先把第一缓冲区(a)的数据写入到磁盘中。然后把第二个缓冲区(b)当作第一
个缓冲区(a)。再进行写入的时候写第二个缓冲区(a)。读操作类似。这样设计之后就能防止因缓冲区区域小导致数据写入
或者读取的不完整情况。提高并行性和设备的利用度。
3、循环缓冲区:
循环缓冲区是对单缓冲区的改良,这种缓冲区适合于读写速率差不多的情况,可以通过循环缓冲区来进行控制,这种机制
也可以提高设备的利用率。但是读写速率差距较大的时候,又不适合这种方式,这时候又可以引入多个缓冲区来适应速率差别大的问题。
*缓冲池技术:*
缓冲池,说到底也是缓冲区,只不过这种缓冲区较其他缓冲区来说能更好的实现cpu并行和设备的利用率。
1、 emq空缓冲队列:用于取出空缓冲区来进行读写等操作。
2、 inq输入队列:用来记录输入设备输入的数据,以便用户程序读取。
3、outq输出队列:用来记录用户程序输出到设备(显示屏或是文件等)的数据,以便用户程序读取。
先来分析下这个图的含义:
我们的缓冲区主要是有inq,outq,enq三个缓冲队列。其他四种hin,sout,sin,hout工作缓冲区是在这三种缓冲队列上申请和取出缓冲区,用于数据的读取和存储。操作完成之后再把缓冲区放回到原来的队列。所以这四种缓冲区是抽象出来的缓冲区,实际上还是在这三种缓冲队列上进行操作。
1、收容输入:把设备输入的数据放在缓冲区中。
①首先从空缓队列取出一个缓冲区当作hin工作缓冲区,hin=Get_buf(emq)。把数据装入到hin中
②把得到的hin缓冲区放在inq缓冲队列。inq=Put_buf(inq,hin)。供给用户程序利用
2、提取输入:把缓冲区的数据交给用户程序处理。
①把inq缓冲队列中的数据提取到sin工作缓冲区中,sin=Get_buf(inq)。供给用户提取数据。
②提取完数据之后,把sin的工作缓冲区放回到emq空缓冲队列中。emq=Put_buf(emq,sin)。
3:收容输出:把用户程序处理完的数据放在缓冲区中。
①先用工作缓冲区hout向空缓冲队列emq申请缓冲区,得到用户处理的数据,hout=Get_buf(emq)。
②hout的数据读取完毕之后,放在outq缓冲区中。Put_buf(outq,hout)供给外设读取。
4:提取输出:
①先把要输出到设备的缓冲区中的数据放在sout工作缓冲区中。sout=Get_buf(outq)。
②提取完sout的数据之后,把sout缓冲区放到空缓冲队列而emq中。emq=Put_buf(emq,sout)
有了缓冲池支撑缓冲,能够大大提高设备和cpu的利用率。这时候可以允许多个线程来处理数据。A线程送完了数据之后,直接执行其他部分。B线程过来的时候带走应用程序处理的A线程的数据。放在对应的位置。多个设备也可同时对缓冲区的不同位置进行读写,互不干扰。效率大大提高。

也就是说,缓冲和高速缓存的一个显著区别就是,数据在缓存、硬盘和内存中共计只有一份,但是高速缓存是保存了一个额外的拷贝

假脱机技术可以理解为“虚拟打印机”,应用程序的打印任务不直接送给物理打印机,而是先送到这里进行传输然后排队,最后串行地输出到实际的打印机的驱动程序中。这使得独享的打印机具有了一定的并行执行能力


标签:阻塞与非阻塞 分布式系统 系统 src 行操作 提高 线程 授权 node
原文地址:https://www.cnblogs.com/jiading/p/12289126.html
