标签:compare 多个 通用 读取 数据类型 完成 protected 时间 pen
一个分布式系统基础架构,由Apache基金会所开发。用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力进行高速运算和存储。
Hadoop的框架最核心的设计就是:HDFS和MapReduce
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。 HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。 HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
YARN 是开源 Hadoop 分布式处理框架中的资源管理和作业调度技术。
作为 Apache Hadoop 的核心组件之一,YARN 负责将系统资源分配给在 Hadoop 集群中运行的各种应用程序,
并调度要在不同集群节点上执行的任务。
commodity hardware)上的 Hadoop 的分布式文件系统。首先 HDFS 具有高容错性,
并且它可以被部署到廉价的硬件上。
此外,HDFS 提供对应用程序数据的高吞吐量访问,适用于具有大型数据集的应用程序。
一个 HDFS 实例有可能包含数百台或数千台服务器,每一个台机器都存储文件系统数据的一部分,这种情况下硬件故障是常态。
而 HDFS 可检测故障并从中快速自动恢复。
HDFS 设计用于批处理而不是用户的交互式使用,
其重点是数据访问的高吞吐量而并不追求数据访问的低延迟。
HDFS 的核心目标就是为处理具有大数据量的应用,在其上运行的应用的文件大小一般都为 TB 级别。
HDFS 可提供高聚合数据带宽并且要扩展到集群中的数百个节点上,并对于单个应用可支持上千万个文件。
HDFS 应用程序是一个"一次写入多次读取"的文件访问模型。
这种模型可以简化数据的一致性问题并且能够实现高吞吐数据访问。
官方文档表示有计划支持追加写入文件的功能。
当一个计算程序与数据同在一个物理节点上时,运算最高效,特别是当数据量特别大时,移动计算远优于移动数据集。
移动计算可以最大限度地减少网络拥塞并提高系统的整体吞吐量。
HDFS 设计的是将计算迁移到更靠近数据所在的位置,而不是将数据移动到运行应用程序的位置。
HDFS 为应用程序提供了接口,使其自身更靠近数据。
HDFS 的设计便于从一个平台移植到另一个平台。
这有助于广泛采用 HDFS 作为大量应用程序的首选大数据处理平台。
NameNode 与 DataNode 是 HDFS 系统的重要知识点。 HDFS 是 master/slave 体系结构。
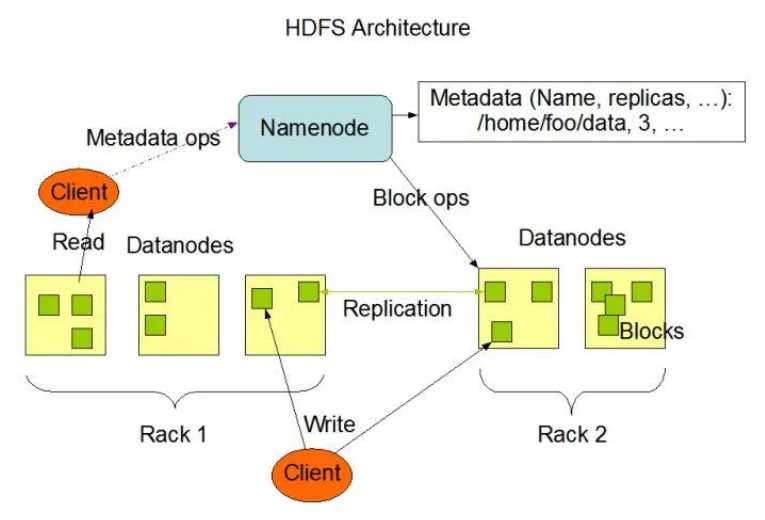
一个 HDFS 集群是由单个 NameNode 和众多 DataNode 组成,文件会被分成一个或多个块,这些块存储在一组 DataNode 中。
因为 HDFS 是用 Java 语言搭建的,所以只要是支持 Java 语言的机器都可以运行 NameNode 和 DataNode。并且因为 Java 的高可移植性,HDFS 也具有非常广泛的应用范围。
一种典型的 HDFS 部署模式是指定一个物理主机运行 NameNode,然后其余的机器运行 DataNode,在实际部署情况中,一般都是一台主机部署一个 DataNode。
群集中存在单个 NameNode 极大地简化了系统的体系结构。
NameNode 是所有 HDFS 元数据的决定者和存储库。
系统的这种设计使用户数据永远不会流经 NameNode,可理解 NameNode 为整个系统的中枢。
首先图中的 rack 翻译为“机架”,可以理解为两个处于不同地方的机群,每个机群内部有自己的连接方式。
其次在 DataNode 中存储的不是单个文件,而是文件块(Block),
在 HDFS 中,每个大文件会拆分成多个 Block,然后将这些 Block 散布存储在不同的 DataNode 中,
并且每个 Block 会有多个复制,也会存储到其他的 DataNode中。
上图分别解释了“读”和“写”两种操作:
当有客户端要向 HDFS 写入文件时,图中将文件拆分的 Block 写入到了两个机架的 DataNode 中,
一般情况下就是两个机架的两个物理主机中,
可以看出文件数据没有经过 NameNode。----客户端写,文件数据不经过NameNode
数据写入的过程见(“数据复制流水线”)
当有客户端要从 HDFS 读取文件时,
会将操作命令传向 NameNode, -----客户端读,操作命令经过NameNode。由NameNode转化操作,指挥相应DataNode将数据返回客户端
然后 NameNode 转为对应的数据块的操作,指挥相应的 DataNode 将所需数据返回给客户端。
还有一个节点图中没有显示,叫作 Secondary Namenode,是辅助后台程序,
主要负责与 NameNode 进行通信,定期保存 HDFS 元数据的快照及备份其他 NameNode 中的内容,日常 Standby,
当 NameNode 故障时顶替 NameNode 使用。
NameNode 是管理文件系统命名空间的主服务器,用于管理客户端对文件的访问,
执行文件系统命名空间操作,如打开,关闭和重命名文件和目录。
它还确定了Block 到 DataNode 的映射。
NameNode 做着有关块复制的所有决定,它定期从群集中的每个 DataNode 接收 Heartbeat 和 Blockreport。
收到 Heartbeat 意味着 DataNode正常运行,Blockreport 包含 DataNode 上所有块的列表。
DataNode 通常是群集中每个节点一个,用于存储数据,负责提供来自文件系统客户端的读写请求。
并且还会根据 NameNode 的指令执行块创建,删除和复制
HDFS 支持传统的分层文件组织,文件系统命名空间层次结构与大多数其他现有文件系统类似,一个用户或者应用可以创建文件夹并且在这个文件夹里存储文件。HDFS 不支持 Linux 里的硬链接和软连接。NameNode 维护着文件系统的命名空间,其记录对文件系统命名空间或其属性的任何更改,NameNode 还会存储复制因子数据块的副本数称为该数据块的复制因子
MetaData)也存储在 NameNode 中,NameNode 使用名为 EditLog 的事务日志来持久记录文件系统元数据发生的每个更改。HDFS 中创建新文件会导致 NameNode 将记录插入 EditLog,以指示此情况。NameNode 使用其本地主机OS文件系统中的文件来存储 EditLog。FsImage 的文件中。 FsImage 也作为文件存储在 NameNode 的本地文件系统中。NameNode 在整个内存中保存整个文件系统命名空间和文件的数据块映射。当 NameNode 启动,或者检查点由可配置的阈值触发时,它从磁盘读取 FsImage 和 EditLog,并先将 FsImage 中的文件系统元数据信息加载到内存,然后把 EditLog 中的所有事务应用到内存中的 FsImage,最后将此新版本同步到磁盘上的 FsImage。然后它可以截断旧的 EditLog,因为它的事务已应用于持久性 FsImage。此过程称为检查点。检查点的目的是通过获取文件系统元数据的快照并将其保存到 FsImage 来确保 HDFS 具有文件系统元数据的一致视图。尽管直接从内存中读取 FsImage 很高效,但直接对 FsImage 进行增量编辑效率不高。我们不会修改每个编辑的 FsImage,而是在 Editlog 中保留编辑内容。
在检查点期间,Editlog 的更改将应用于 FsImage。可以以秒为单位的给定时间间隔(dfs.namenode.checkpoint.period)触发检查点,或者在累积给定数量的文件系统事务(dfs.namenode.checkpoint.txns)之后触发检查点。如果同时设置了这两个属性,则一旦满足其中一个阈值就可触发检查点。
HDFS 旨在跨大型集群中的计算机可靠地存储非常大的文件。它将每个文件存储为一系列块,除最后一个块之外的文件中的所有块都具有相同的大小,HDFS 使用的默认块大小为 128MB。复制文件的块以实现容错,且一般复制出的文件块会存储到不同的 DataNode 中。数据块的大小以及复制因子都是可以由用户设置。HDFS中的文件是一次写入的,并且在任何时候都只能有一个写入器。
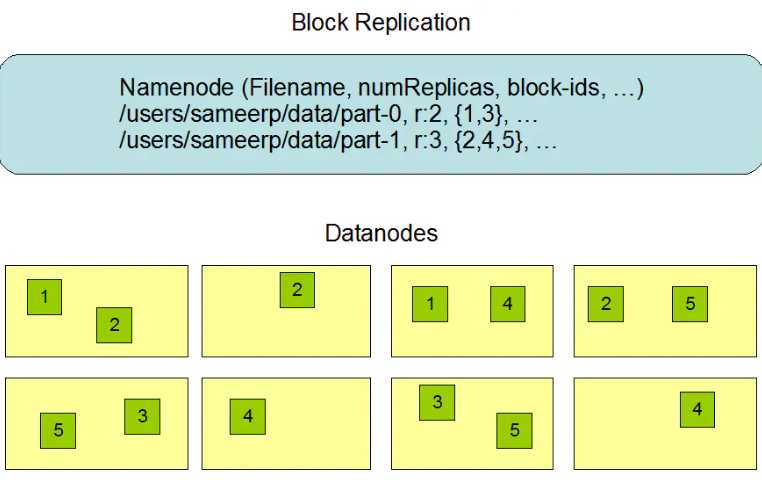
part-0 文件复制因子为r:2,其拆分的数据块号有{1,3},所以 1 号数据块在第1,第3个 DataNode 上,3 号数据块在第5,第6个DataNode上;part-1文件解释同理。而这些信息都存储在 NameNode 中。HDFS 副本放置策略是一个值得研究的课题,因为这切实关系到 HDFS 的可依赖性与表现,并且经过优化的副本放置策略也使得 HDFS 相比其他分布式文件系统具有优势。在大部分的实际案例中,当复制因子是 r = 3 时,HDFS 的放置策略是:
将一个复制品放置到写入器操作的 DataNode中,
第二个复制品放置到另一个远程机架上的一个节点中,
然后最后一个复制品则放置同一个远程机架的不同物理节点中。
这种放置策略可以有效的减少机架之中的通信以提高系统的表现。
因为不同机架的物理节点的通信需要通过交换机,
而在大多数情况下,同一机架中的计算机之间的网络带宽大于不同机架中的计算机之间的网络带宽。
如果复制因子大于3,则随机确定第4个及以后副本的放置,同时保持每个机架的副本数量低于上限。
上限数一般为:
(副本数-1)/ 机架 + 2
由于 NameNode 不允许 DataNode 具有同一块的多个副本,因此,能创建的最大副本数是此时 DataNode 的总数。
当有客户端请求读取时,HDFS 为了最小化全局带宽消耗与读取延迟,会优先选择离读取客户端最近的数据副本。
HDFS 通信协议都分层在 TCP/IP 协议之上。当客户端将数据写入复制因子为 r = 3 的 HDFS 文件时,
NameNode 使用 replication target choosing algorithm 检索 DataNode 列表。
此列表包含将承载该块副本的 DataNode。
然后客户端向第一个 DataNode 写入,第一个 DataNode 开始分批接收数据,将每个部分写入其本地存储,并将该部分传输到列表中的第二个 DataNode。
第二个 DataNode 又开始接收数据块的每个部分,将该部分写入其存储,然后将该部分刷新到第三个 DataNode。
最后,第三个 DataNode 将数据写入其本地存储。
可见,DataNode 是从流水线中的前一个接收数据,同时将数据转发到流水线中的下一个,数据是从一个 DataNode 流水线到下一个 DataNode。
应用可以以多种方式操控 HDFS 上的文件,其中通过 FS Shell 可以像操控 Linux 文件系统一般,常用命令有:
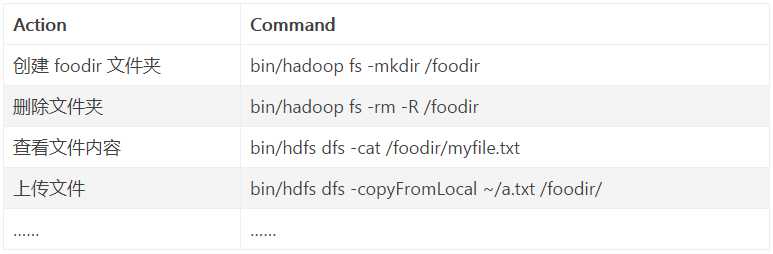
会发现这里有两种命令前缀,一个是 hadoop fs,一个是 hdfs dfs
区别是:hadoop fs 可以用于其他文件系统,不止是hdfs文件系统内,也就是说该命令的使用范围更广;而 hdfs dfs 专门针对hdfs分布式文件系统。
还有一个前缀为 hadoop dfs,这个已经过时,建议不要使用
如果启用了垃圾箱配置,则 FS Shell 删除的文件不会立即从 HDFS 中删除,而是 HDFS 将其移动到垃圾目录(/user/username/.Trash)。
在垃圾箱中,被删除文件的生命周期到期后,NameNode 将从 HDFS 命名空间中删除该文件。删除文件会导致释放与文件关联的块。
注意:在用户删除文件的时间与 HDFS 中相应增加的可用空间之间可能存在明显的时间延迟。
如果启用了垃圾箱配置,想直接彻底删除,命令为:hadoop fs -rm -r -skipTrash a.txt
当文件的复制因子减少时,NameNode 选择可以删除的多余副本。
下一个 Heartbeat 将此信息传输到 DataNode。
然后,DataNode删除相应的块,并在群集中显示相应的可用空间。
MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题
1>拿到日志中的一行数据 2>切分各个字段,获取我们所需要的字段 3>如果所需要的字段过多的话,可以考虑用Hadoop中自定义的数据类型进行封装处理
1>指定输入文件的路径,并将输入文件在逻辑上切分成若干个split数据片。随后对输入切片按照一定的规则解析成键值对<k1,v1>,其中k1就是我们常说的起始偏移量,v1就是行文本的内容。 2>调用自己编写的map函数,将输入的键值对<k1,v1>转化成键值对<k2,v2>,其中每一个键值对<k1,v1>都会调用一次map函数。 3>对输出的键值对<k2,v2>进行分区、排序、分组,其中分组就是相同的key的value放到同一个集合当中。 4>(可选)对分组后的数据进行本地归并处理(combiner)。
5>对多个Mapper任务的输出,按照不同的分区,通过网络拷贝到不同的Reducer节点上进行处理,随后对多个Mapper任务的输出进行合并,排序。 6>调用自己编写的reduce函数,将输入的键值对<k2,v2s>转化成键值对<k3,v3>
7>将Reducer任务的输出保存到指定的文件中。
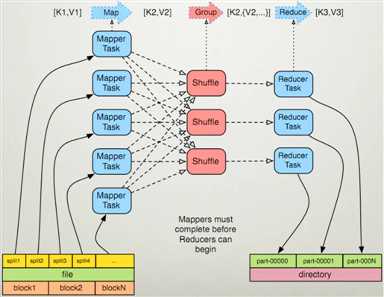
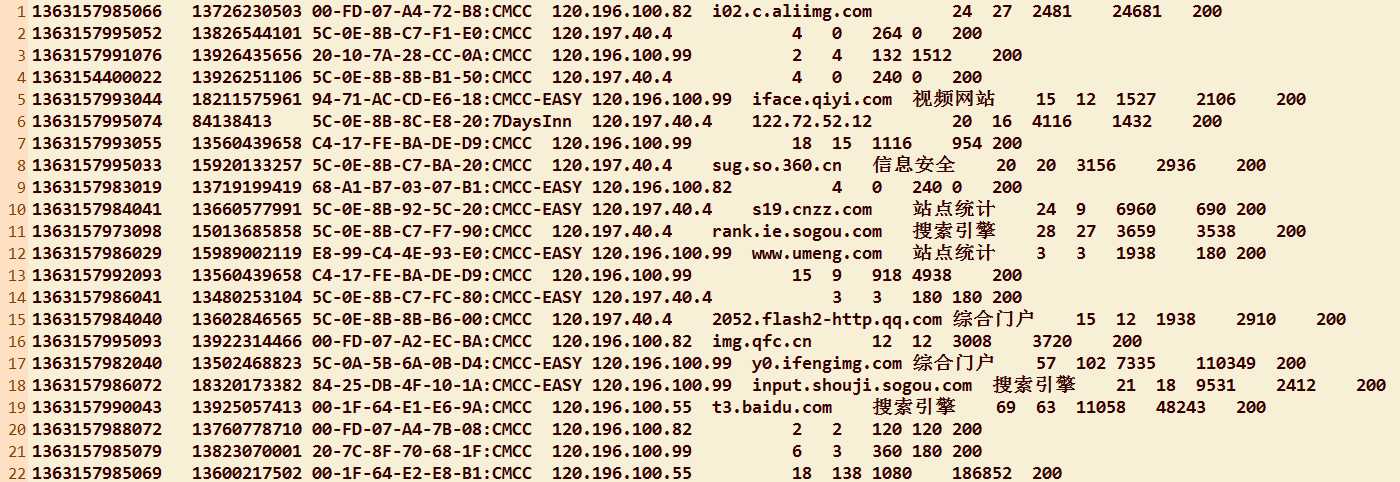
例如:
![]()
package com.appache.celephone3; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class FlowCount { public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt"; public static String path2 = "hdfs://hadoop:9000/dirout/"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://hadoop:9000/"); FileSystem fileSystem = FileSystem.get(conf); if(fileSystem.exists(new Path(path2))) { fileSystem.delete(new Path(path2), true); } Job job = new Job(conf,"FlowCount"); job.setJarByClass(FlowCount.class); //编写驱动 FileInputFormat.setInputPaths(job, new Path(path1)); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //shuffle洗牌阶段 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job, new Path(path2)); //将任务提交给JobTracker job.waitForCompletion(true); //查看程序的运行结果 FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000")); IOUtils.copyBytes(fr,System.out,1024,true); } }
package com.appache.celephone3; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException { String line = v1.toString();//拿到日志中的一行数据 String[] splited = line.split("\t");//切分各个字段 //获取我们所需要的字段 String msisdn = splited[1]; String upFlow = splited[8]; String downFlow = splited[9]; long flowsum = Long.parseLong(upFlow) + Long.parseLong(downFlow); context.write(new Text(msisdn), new Text(upFlow+"\t"+downFlow+"\t"+String.valueOf(flowsum))); } }
package com.appache.celephone3; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException { long upFlowSum = 0L; long downFlowSum = 0L; long FlowSum = 0L; for(Text v2:v2s) { String[] splited = v2.toString().split("\t"); upFlowSum += Long.parseLong(splited[0]); downFlowSum += Long.parseLong(splited[1]); FlowSum += Long.parseLong(splited[2]); } String data = String.valueOf(upFlowSum)+"\t"+String.valueOf(downFlowSum)+"\t"+String.valueOf(FlowSum); context.write(k2,new Text(data)); } }
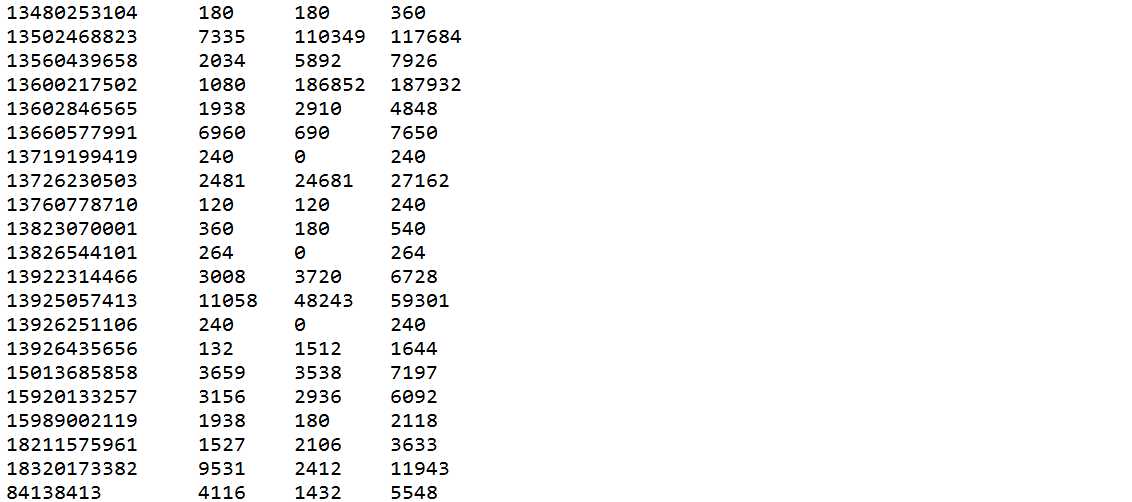

对于上面的电信数据,统计同一个用户的上行总流量和,下行总流量和以及上下总流量和,并且手机号(11位)的信息输出到一个文件中,非手机号(8位)的信息输出到一个文件中
代码示例:
package com.appache.partitioner; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class FlowCount { public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt"; public static String path2 = "hdfs://hadoop:9000/dirout/"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.default.name", "hdfs://hadoop:9000/"); FileSystem fileSystem = FileSystem.get(conf); if(fileSystem.exists(new Path(path2))) { fileSystem.delete(new Path(path2), true); } Job job = new Job(conf,"FlowCount"); job.setJarByClass(FlowCount.class); FileInputFormat.setInputPaths(job, new Path(path1)); job.setInputFormatClass(TextInputFormat.class);//<k1,v1> job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(FlowBean.class);//<k2,v2> //shuffle阶段:分区、排序、分组、本地归并 job.setPartitionerClass(MyPartitioner.class); job.setNumReduceTasks(2); //<k2,v2s> job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(FlowBean.class); job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job, new Path(path2)); //提交作业 job.waitForCompletion(true); } }
package com.appache.partitioner; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; public class FlowBean implements Writable { long upFlow ; //上行流量 long downFlow; //下行流量 long flowSum; //总流量 public FlowBean() {} public FlowBean(String upFlow,String downFlow) { this.upFlow = Long.parseLong(upFlow); this.downFlow = Long.parseLong(downFlow); this.flowSum = Long.parseLong(upFlow) + Long.parseLong(downFlow); } public long getupFlow() {return upFlow;} public long getdownFlow() {return downFlow;} public long getflowSum () {return flowSum;} @Override public void write(DataOutput out) throws IOException { out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(flowSum); } @Override public void readFields(DataInput in) throws IOException { upFlow = in.readLong(); downFlow = in.readLong(); flowSum = in.readLong(); } public String toString() { return upFlow+"\t"+downFlow+"\t"+flowSum; } }
package com.appache.partitioner; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, Text, FlowBean> { @Override protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException { String line = v1.toString();//拿到日志中的一行数据 String[] splited = line.split("\t");//切分各个字段 //获取我们所需要的字段 String msisdn = splited[1];//手机号 k2 FlowBean flowData = new FlowBean(splited[8],splited[9]);//<100,200> context.write(new Text(msisdn), flowData); } }
package com.appache.partitioner; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Partitioner; public class MyPartitioner extends Partitioner<Text,FlowBean> //分区<18330267966,{100,200}> { @Override public int getPartition(Text k2, FlowBean v2, int numPartitions) { String tele = k2.toString(); if(tele.length() == 11) return 0; //手机号的信息输出到0区 else return 1; //非手机号的信息输出到1区 } }
package com.appache.partitioner; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<Text, FlowBean, Text, FlowBean> { @Override protected void reduce(Text k2, Iterable<FlowBean> v2s,Context context)throws IOException, InterruptedException { long upFlow = 0L; long downFlow = 0L; long flowSum = 0L; for(FlowBean v2: v2s) { upFlow += v2.getupFlow(); downFlow += v2.getdownFlow(); flowSum += v2.getflowSum(); } context.write(k2, new FlowBean(upFlow+"",downFlow+"")); //将数据输出到指定的文件当中 } }
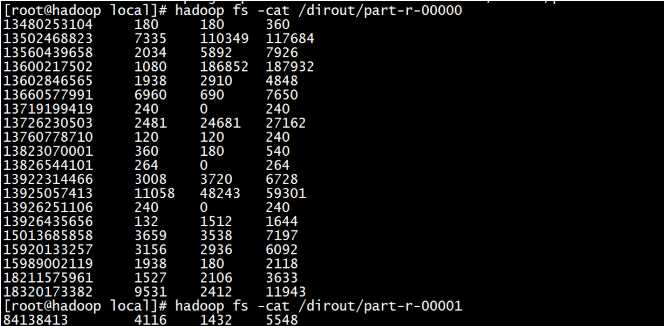

对于上面业务得到的统计结果:
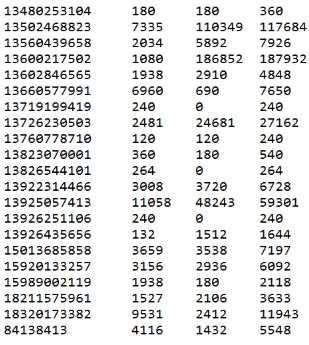
先按照总流量由低到高排序,在总流量相同的情况下,按照下行流量和从低到高排序:
实例代码:
package com.appache.sort; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class FlowCount { public static String path1 = "hdfs://hadoop:9000/flowCount.txt"; public static String path2 = "hdfs://hadoop:9000/dirout/"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://hadoop:9000/"); FileSystem fileSystem = FileSystem.get(conf); if(fileSystem.exists(new Path(path2))) { fileSystem.delete(new Path(path2), true); } Job job = new Job(conf, "FlowCount"); job.setJarByClass(FlowCount.class); //编写驱动 FileInputFormat.setInputPaths(job,new Path(path1)); //输入文件的路径 job.setInputFormatClass(TextInputFormat.class);//<k1,v1> job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(FlowBean.class); job.setMapOutputValueClass(NullWritable.class); //shuffle优化阶段 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(FlowBean.class); job.setOutputValueClass(NullWritable.class); job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job,new Path(path2)); job.waitForCompletion(true); //查看运行结果: FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000")); IOUtils.copyBytes(fr,System.out,1024,true); } }
package com.appache.sort; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.WritableComparable; public class FlowBean implements WritableComparable<FlowBean> { private String msisdn; //获取我们所需要的字段 private long upFlow; private long downFlow; private long flowSum; public FlowBean(){} public FlowBean(String msisdn,String upFlow,String downFlow,String flowSum) { this.msisdn = msisdn; this.upFlow = Long.parseLong(upFlow); this.downFlow = Long.parseLong(downFlow); this.flowSum = Long.parseLong(flowSum); //通过构造函数自动求取总流量 } public String getMsisdn() { return msisdn; } public long getUpFlow() { return upFlow; } public long getDownFlow() { return downFlow; } public long getFlowSum() { return flowSum; } @Override //所谓序列化就是将对象写到字节输出流当中 public void write(DataOutput out) throws IOException { out.writeUTF(msisdn); out.writeLong(upFlow); out.writeLong(downFlow); out.writeLong(flowSum); } @Override //所谓反序列化就是将对象从输入流当中给读取出来 public void readFields(DataInput in) throws IOException { this.msisdn = in.readUTF(); this.upFlow = in.readLong(); this.downFlow = in.readLong(); this.flowSum = in.readLong(); } @Override //指定比较的标准 public int compareTo(FlowBean obj) { if(this.flowSum == obj.flowSum) return (int)(obj.downFlow - this.downFlow); //下行流量由高到底 else return (int)(this.flowSum - obj.flowSum); //总流量由低到高 } public String toString() { return this.msisdn+"\t"+this.upFlow+"\t"+this.downFlow+"\t"+this.flowSum; } }
package com.appache.sort; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, FlowBean, NullWritable> { @Override protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException { //拿到日志中的一行数据 String line = v1.toString(); //切分各个字段 String[] splited = line.split("\t"); //获取我们所需要的字段---并用FlowBean存储我们所需要的字段 FlowBean flowdata = new FlowBean(splited[0],splited[1],splited[2],splited[3]); context.write(flowdata, NullWritable.get()); //<{18330267966,100,200},null> } }
package com.appache.sort; import java.io.IOException; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<FlowBean, NullWritable, FlowBean, NullWritable> { @Override protected void reduce(FlowBean k2, Iterable<NullWritable> v2s,Context context)throws IOException, InterruptedException { for(NullWritable v2:v2s) { context.write(k2, NullWritable.get()); } } }
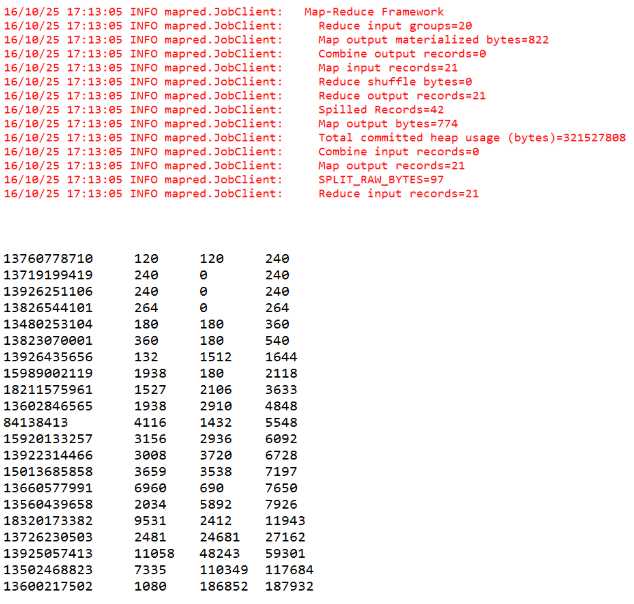

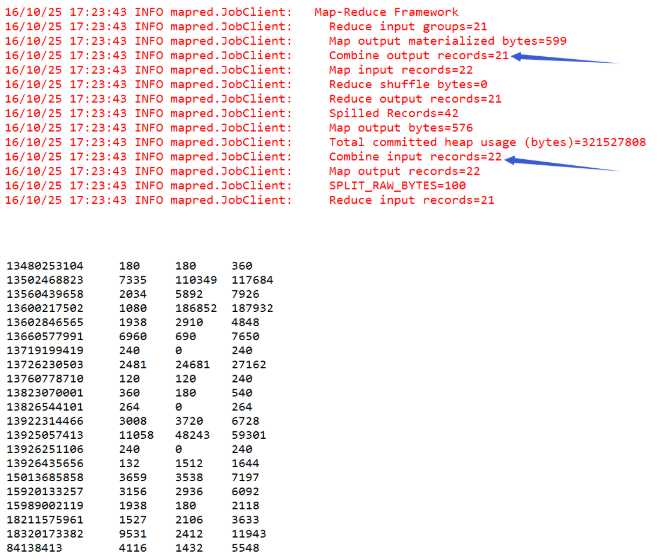
具体业务描述:对于上面的电信数据,统计同一个用户的上行总流量和,下行总流量和以及上下总流量和,代码中要求加入本地归并优化方式:
代码示例:
package com.appache.celephone3; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.FSDataInputStream; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IOUtils; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class FlowCount { public static String path1 = "hdfs://hadoop:9000/dir/flowdata.txt"; public static String path2 = "hdfs://hadoop:9000/dirout/"; public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); conf.set("fs.default.name","hdfs://hadoop:9000/"); FileSystem fileSystem = FileSystem.get(conf); if(fileSystem.exists(new Path(path2))) { fileSystem.delete(new Path(path2), true); } Job job = new Job(conf,"FlowCount"); job.setJarByClass(FlowCount.class); //编写驱动 FileInputFormat.setInputPaths(job, new Path(path1)); job.setInputFormatClass(TextInputFormat.class); job.setMapperClass(MyMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Text.class); //加入本地归并优化方式: job.setCombinerClass(MyReducer.class); job.setNumReduceTasks(2); //shuffle洗牌阶段 job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); job.setOutputFormatClass(TextOutputFormat.class); FileOutputFormat.setOutputPath(job, new Path(path2)); //将任务提交给JobTracker job.waitForCompletion(true); //查看程序的运行结果 FSDataInputStream fr = fileSystem.open(new Path("hdfs://hadoop:9000/dirout/part-r-00000")); IOUtils.copyBytes(fr,System.out,1024,true); } }
package com.appache.celephone3; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class MyMapper extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable k1, Text v1,Context context)throws IOException, InterruptedException { String line = v1.toString();//拿到日志中的一行数据 String[] splited = line.split("\t");//切分各个字段 //获取我们所需要的字段 String msisdn = splited[1]; String upFlow = splited[8]; String downFlow = splited[9]; long flowsum = Long.parseLong(upFlow) + Long.parseLong(downFlow); context.write(new Text(msisdn), new Text(upFlow+"\t"+downFlow+"\t"+String.valueOf(flowsum))); } }
package com.appache.celephone3; import java.io.IOException; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReducer extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text k2, Iterable<Text> v2s,Context context)throws IOException, InterruptedException { long upFlowSum = 0L; long downFlowSum = 0L; long FlowSum = 0L; for(Text v2:v2s) { String[] splited = v2.toString().split("\t"); upFlowSum += Long.parseLong(splited[0]); downFlowSum += Long.parseLong(splited[1]); FlowSum += Long.parseLong(splited[2]); } String data = String.valueOf(upFlowSum)+"\t"+String.valueOf(downFlowSum)+"\t"+String.valueOf(FlowSum); context.write(k2,new Text(data)); } }


YARN在Hadoop中的功能作用有两个,
第一是负责Hadoop集群中的资源管理(resource management),
第二是负责对任务进行调度和监控(scheduling/monitoring)。
YARN分别提供了相应的组件完成这两项工作。
YARN在管理资源上采用的是master/slave架构。
在整个YARN集群中,在其中一个节点上运行ResourceManager进程作为master,其余每个节点上都运行一个NodeManager进程作为slave。
ResourceManager负责对集群中的所有资源进行统一的管理和调度。
NodeManager进程负责单个节点上的资源管理,它监控一个节点上的资源使用情况(如cpu,内存,硬盘,网络等)并将其report给ResourceManager。
ResourceManager有两个主要的组件:Scheduler和ApplicationsManager。
其中的Scheduler就负责为集群中运行的各个application分配所需要的资源。
Scheduler只负责资源的调度,它不做任何对application监控或跟踪的工作,此外,在任务由于各种原因执行失败时,它也不负责对任务进行重启。
Scheduler根据application对资源的需求执行其资源调度功能。
它将cpu、内存、硬盘、网络等资源合并成一个整体,抽象成Container进行资源分配。Container就是Scheduler进行资源分配的一个单位,也是运行各个任务的容器。
此外,Scheduler是一个可插拔的组件,
用户可根据自己的需要设计新的Scheduler,YARN提供了多种可直接使用的调度器,比如Fair Scheduler和Capacity Scheduler等。
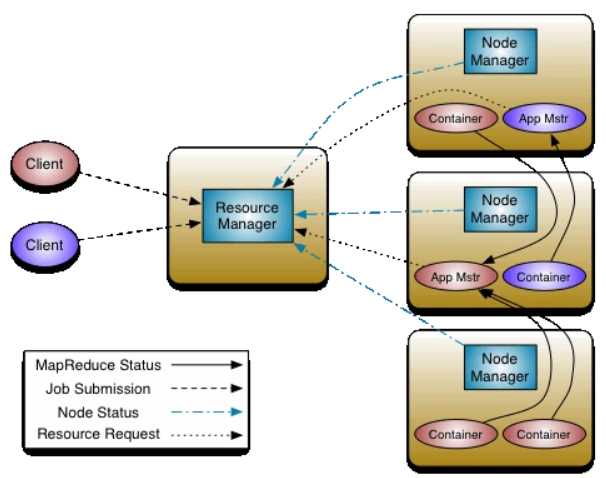
ApplicationMaster组件(master中)负责跟踪和管理一次提交的作业(job),它负责为job的运行向ResourceManager中的Scheduler组件申请资源,并通过NodeManger(slave中)启动和监控这个job的所有task。
ResourceManager中的ApplicationsManager组件会对所有job的ApplicationMaster进行管理,
它首先会为ApplicationMaster组件分配资源,使其运行在一个slave节点的Container中。
并负责监控ApplicationMaster的运行状态,在Container出现异常时对ApplicationMaster进行重启。
ApplicationsManager负责管理整个集群中的所有job,
包括job的提交、与Scheduler协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
上面我们已经介绍了YARN中的全部组件的作用,现在我们详细说一下YARN的架构。
ResourceManager是集群中的master节点,作为老大统一管理集群中的所有资源分配。
集群中可以存在多个NodeManager节点,NodeManager负责其所在机器上的资源管理,并将资源使用情况report给ResourceManager节点。
Container是YARN中的资源抽象,它封装了一个节点上的多维度资源,如内存、CPU、磁盘、网络等。
从图中可以看到,一个NodeManager节点上同时存在多个Container。提交作业的每个task都运行在一个Container中。
首先,对于每个提交的作业都必须要有一个ApplicationMaster(如这里的两个作业分别对应一个ApplicationMaster)。
ApplicationMaster对作业的所有任务进行跟踪监控和管理,可以看到作业下的每个任务都将执行statue汇报给ApplicationMaster。
此外,ApplicationMaster还负责向ResourceManager申请资源。
常见的操作有提交一个作业、杀死一个作业等。
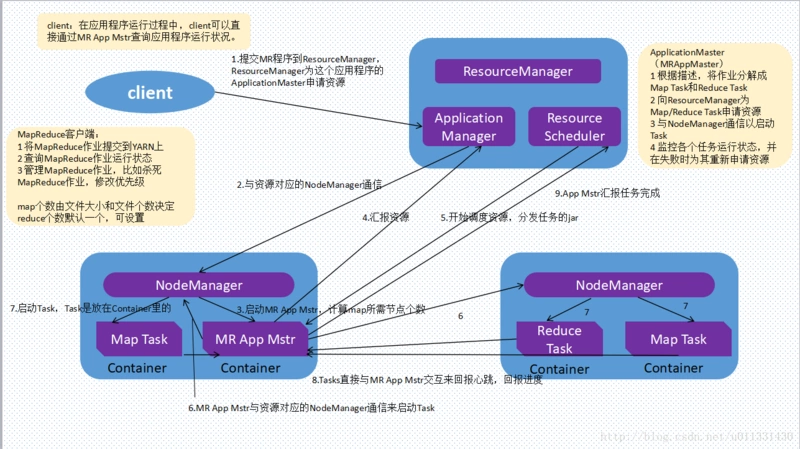
1.Client向YARN提交一个job,首先向ResourceManager中的ApplicationManager申请资源,用于运行本作业的ApplicationMaster。
2.ApplicationManager给集群中的一个NodeManager发命令,通知其创建一个Container并运行作业的ApplicationMaster。
3.NodeManager创建一个Container并启动作业的ApplicationMaster。
4.ApplicationMaster将自己注册到ApplicationManager,使得ApplicationManager可以监控到Job的执行状态,Client也可以通过ApplicationManager对作业进行控制。
5.Scheduler将资源分配信息发给ApplicationMaster。
6.ApplicationMaster将获取到的资源分配信息发送给各个NodeManager。
7.各个NodeManager接收到资源分配命令,创建Container并启动对应的task。
8.各个task直接与ApplicationMaster进行通信,汇报心跳和任务执行进度。
9.所有的Task都执行完毕,将讲过反馈给ApplicationMaster。ApplicationMaster再将任务执行的结果反馈ApplicationManager。
https://www.jianshu.com/p/325a19d75d41
标签:compare 多个 通用 读取 数据类型 完成 protected 时间 pen
原文地址:https://www.cnblogs.com/ssyfj/p/12283765.html