标签:改名 表名 png 也会 opentsdb ons 字段 over 挂载
本文主要介绍基于Prometheus + Grafana 监控Linux服务器。
Prometheus 可以支持多种安装方式,包括 Docker、Ansible、Chef、Puppet、Saltstack 等。下面介绍最简单的两种方式,一种是直接使用编译好的可执行文件,开箱即用,另一种是使用 Docker 镜像
首先从 官网的下载页面 获取 Prometheus 的最新版本和下载地址,目前最新版本是 2.4.3(2018年10月),执行下面的命令下载并解压:
|
1 2 |
|
然后切换到解压目录,检查 Prometheus 版本:
|
1 2 3 4 5 6 |
|
运行 Prometheus server:
|
1 |
|
使用 Docker 安装 Prometheus 更简单,运行下面的命令即可:
|
1 |
|
一般情况下,我们还会指定配置文件的位置:
|
1 2 3 |
|
我们把配置文件放在本地 ~/docker/prometheus/prometheus.yml,这样可以方便编辑和查看,通过 -v 参数将本地的配置文件挂载到 /etc/prometheus/ 位置,这是 prometheus 在容器中默认加载的配置文件位置。如果我们不确定默认的配置文件在哪,可以先执行上面的不带 -v 参数的命令,然后通过 docker inspect 命名看看容器在运行时默认的参数有哪些(下面的 Args 参数):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
|
正如上面两节看到的,Prometheus 有一个配置文件,通过参数 --config.file 来指定,配置文件格式为 YAML。我们可以打开默认的配置文件 prometheus.yml 看下里面的内容:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
|
Prometheus 默认的配置文件分为四大块:
scrape_interval 表示 Prometheus 多久抓取一次数据,evaluation_interval 表示多久检测一次告警规则;prometheus 的 job,这是因为 Prometheus 在启动的时候也会通过 HTTP 接口暴露自身的指标数据,这就相当于 Prometheus 自己监控自己,虽然这在真正使用 Prometheus 时没啥用处,但是我们可以通过这个例子来学习如何使用 Prometheus;可以访问 http://localhost:9090/metrics 查看 Prometheus 暴露了哪些指标;通过上面的步骤安装好 Prometheus 之后,我们现在可以开始体验 Prometheus 了。Prometheus 提供了可视化的 Web UI 方便我们操作,直接访问 http://localhost:9090/ 即可,它默认会跳转到 Graph 页面:
第一次访问这个页面可能会不知所措,我们可以先看看其他菜单下的内容,比如:Alerts 展示了定义的所有告警规则,Status 可以查看各种 Prometheus 的状态信息,有 Runtime & Build Information、Command-Line Flags、Configuration、Rules、Targets、Service Discovery 等等。
实际上 Graph 页面才是 Prometheus 最强大的功能,在这里我们可以使用 Prometheus 提供的一种特殊表达式来查询监控数据,这个表达式被称为 PromQL(Prometheus Query Language)。通过 PromQL 不仅可以在 Graph 页面查询数据,而且还可以通过 Prometheus 提供的 HTTP API 来查询。查询的监控数据有列表和曲线图两种展现形式(对应上图中 Console 和 Graph 这两个标签)。
我们上面说过,Prometheus 自身也暴露了很多的监控指标,也可以在 Graph 页面查询,展开 Execute 按钮旁边的下拉框,可以看到很多指标名称,我们随便选一个,譬如:promhttp_metric_handler_requests_total,这个指标表示 /metrics 页面的访问次数,Prometheus 就是通过这个页面来抓取自身的监控数据的。在 Console 标签中查询结果如下:
上面在介绍 Prometheus 的配置文件时,可以看到 scrape_interval 参数是 15s,也就是说 Prometheus 每 15s 访问一次 /metrics 页面,所以我们过 15s 刷新下页面,可以看到指标值会自增。在 Graph 标签中可以看得更明显:
要学习 PromQL,首先我们需要了解下 Prometheus 的数据模型,一条 Prometheus 数据由一个指标名称(metric)和 N 个标签(label,N >= 0)组成的,比如下面这个例子:
|
1 |
|
这条数据的指标名称为 promhttp_metric_handler_requests_total,并且包含三个标签 code、instance 和 job,这条记录的值为 106。上面说过,Prometheus 是一个时序数据库,相同指标相同标签的数据构成一条时间序列。如果以传统数据库的概念来理解时序数据库,可以把指标名当作表名,标签是字段,timestamp 是主键,还有一个 float64 类型的字段表示值(Prometheus 里面所有值都是按 float64 存储)。
这种数据模型和 OpenTSDB 的数据模型是比较类似的,详细的信息可以参考官网文档 Data model。另外,关于指标和标签的命名,官网有一些指导性的建议,可以参考 Metric and label naming 。
虽然 Prometheus 里存储的数据都是 float64 的一个数值,但如果我们按类型来分,可以把 Prometheus 的数据分成四大类:
Counter 用于计数,例如:请求次数、任务完成数、错误发生次数,这个值会一直增加,不会减少。Gauge 就是一般的数值,可大可小,例如:温度变化、内存使用变化。Histogram 是直方图,或称为柱状图,常用于跟踪事件发生的规模,例如:请求耗时、响应大小。它特别之处是可以对记录的内容进行分组,提供 count 和 sum 的功能。Summary 和 Histogram 十分相似,也用于跟踪事件发生的规模,不同之处是,它提供了一个 quantiles 的功能,可以按百分比划分跟踪的结果。例如:quantile 取值 0.95,表示取采样值里面的 95% 数据。更多信息可以参考官网文档 Metric types,Summary 和 Histogram 的概念比较容易混淆,属于比较高阶的指标类型,可以参考 Histograms and summaries 这里的说明。
这四种类型的数据只在指标的提供方作区分,也就是上面说的 Exporter,如果你需要编写自己的 Exporter 或者在现有系统中暴露供 Prometheus 抓取的指标,你可以使用 Prometheus client libraries,这个时候你就需要考虑不同指标的数据类型了。如果你不用自己实现,而是直接使用一些现成的 Exporter,然后在 Prometheus 里查查相关的指标数据,那么可以不用太关注这块,不过理解 Prometheus 的数据类型,对写出正确合理的 PromQL 也是有帮助的。
下载:wget https://dl.grafana.com/oss/release/grafana-6.3.3-1.x86_64.rpm
安装:sudo yum localinstall grafana-6.3.3-1.x86_64.rpm -y
启动:systemctl enable grafana-server.service
systemctl start grafana-server.service
# web页面3000 登录信息:admin/admin
# 安装插件
grafana-cli plugins install grafana-piechart-panel
systemctl restart grafana-server
安装完成之后,我们访问 http://localhost:3000/ 进入 Grafana 的登陆页面,输入默认的用户名和密码(admin/admin)即可。
要使用 Grafana,第一步当然是要配置数据源,告诉 Grafana 从哪里取数据,我们点击 Add data source 进入数据源的配置页面:
我们在这里依次填上:
要注意的是,这里的 Access 指的是 Grafana 访问数据源的方式,有 Browser 和 Proxy 两种方式。Browser 方式表示当用户访问 Grafana 面板时,浏览器直接通过 URL 访问数据源的;而 Proxy 方式表示浏览器先访问 Grafana 的某个代理接口(接口地址是 /api/datasources/proxy/),由 Grafana 的服务端来访问数据源的 URL,如果数据源是部署在内网,用户通过浏览器无法直接访问时,这种方式非常有用。
配置好数据源,Grafana 会默认提供几个已经配置好的面板供你使用,如下图所示,默认提供了三个面板:Prometheus Stats、Prometheus 2.0 Stats 和 Grafana metrics。点击 Import 就可以导入并使用该面板。
我们导入 Prometheus 2.0 Stats 这个面板,可以看到下面这样的监控面板。如果你的公司有条件,可以申请个大显示器挂在墙上,将这个面板投影在大屏上,实时观察线上系统的状态,可以说是非常 cool 的。
目前为止,我们看到的都还只是一些没有实际用途的指标,如果我们要在我们的生产环境真正使用 Prometheus,往往需要关注各种各样的指标,譬如服务器的 CPU负载、内存占用量、IO开销、入网和出网流量等等。正如上面所说,Prometheus 是使用 Pull 的方式来获取指标数据的,要让 Prometheus 从目标处获得数据,首先必须在目标上安装指标收集的程序,并暴露出 HTTP 接口供 Prometheus 查询,这个指标收集程序被称为 Exporter,不同的指标需要不同的 Exporter 来收集,目前已经有大量的 Exporter 可供使用,几乎囊括了我们常用的各种系统和软件,官网列出了一份 常用 Exporter 的清单,各个 Exporter 都遵循一份端口约定,避免端口冲突,即从 9100 开始依次递增,这里是 完整的 Exporter 端口列表。另外值得注意的是,有些软件和系统无需安装 Exporter,这是因为他们本身就提供了暴露 Prometheus 格式的指标数据的功能,比如 Kubernetes、Grafana、Etcd、Ceph 等。
这一节就让我们来收集一些有用的数据。
首先我们来收集服务器的指标,这需要安装 node_exporter,这个 exporter 用于收集 *NIX 内核的系统,如果你的服务器是 Windows,可以使用 WMI exporter。
和 Prometheus server 一样,node_exporter 也是开箱即用的:
|
1 2 3 4 |
|
node_exporter 启动之后,我们访问下 /metrics 接口看看是否能正常获取服务器指标:
|
1 |
如果一切 OK,我们可以修改 Prometheus 的配置文件,将服务器加到 scrape_configs 中:
|
1 2 3 4 5 6 7 |
|
修改配置后,需要重启 Prometheus 服务,或者发送 HUP 信号也可以让 Prometheus 重新加载配置:
|
1 |
|
在 Prometheus Web UI 的 Status -> Targets 中,可以看到新加的服务器:
在 Graph 页面的指标下拉框可以看到很多名称以 node 开头的指标,譬如我们输入 node_load1 观察服务器负载:
六、一些常用监控举例
1、监控linux机器(node-exporter)
https://github.com/prometheus/node_exporter/releases/download/v0.17.0/node_exporter-0.17.0.linux-amd64.tar.gz
(1)被监控的机器安装node-exporter
tar -xvf node_exporter-0.17.0.linux-amd64.tar.gz -C /usr/local/
(2)启动node-exporter
/usr/local/node_exporter-0.17.0.linux-amd64/node_exporter &
(3)普罗米修斯配置文件添加监控项
vim /usr/local/Prometheus/prometheus.yml
默认node-exporter端口为9100
- job_name: ‘Prometheus‘
static_configs:
- targets: [‘192.168.0.102:9100‘]
labels:
instance: Prometheus
重启普罗米修斯或重新加载配置文件 killall -HUP prometheus
(4)grafana导入画好的dashboard
dashboard json
链接:https://pan.baidu.com/s/1Dlm0IHTgRmc0q2P82cDjKg 提取码:myv6

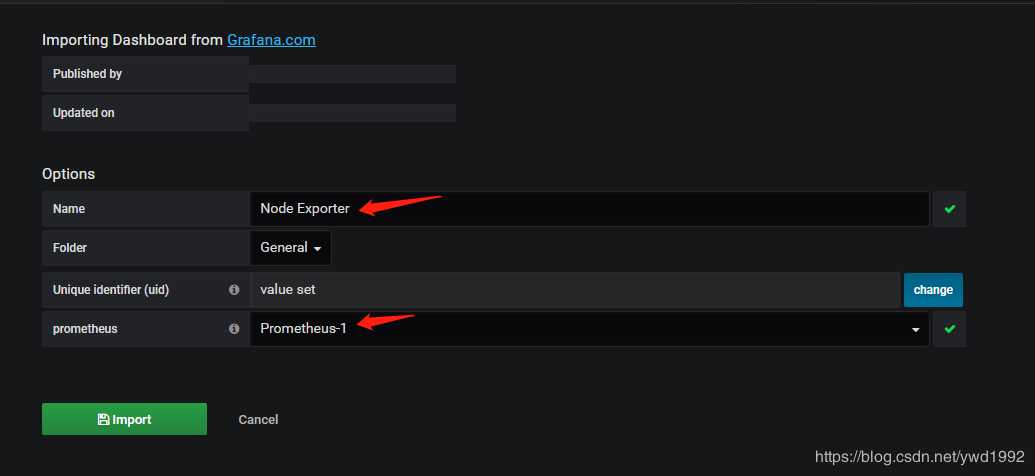
修改名字,选择我们前文创建好的数据源,点击导入即可
如果没有任何显示,是grafana缺少相关显示需要用到的插件piechart,grafana的默认插件目录是/var/lib/grafana/plugins,可以将下载好的插件解压到这个目录,重启grafana即可
piechart插件:
链接:https://pan.baidu.com/s/1tvZWI9vhAqvJhojKmDlmew 提取码:tlyl
service grafana-server restart
/usr/sbin/grafana-cli plugins ls #查看已安装插件
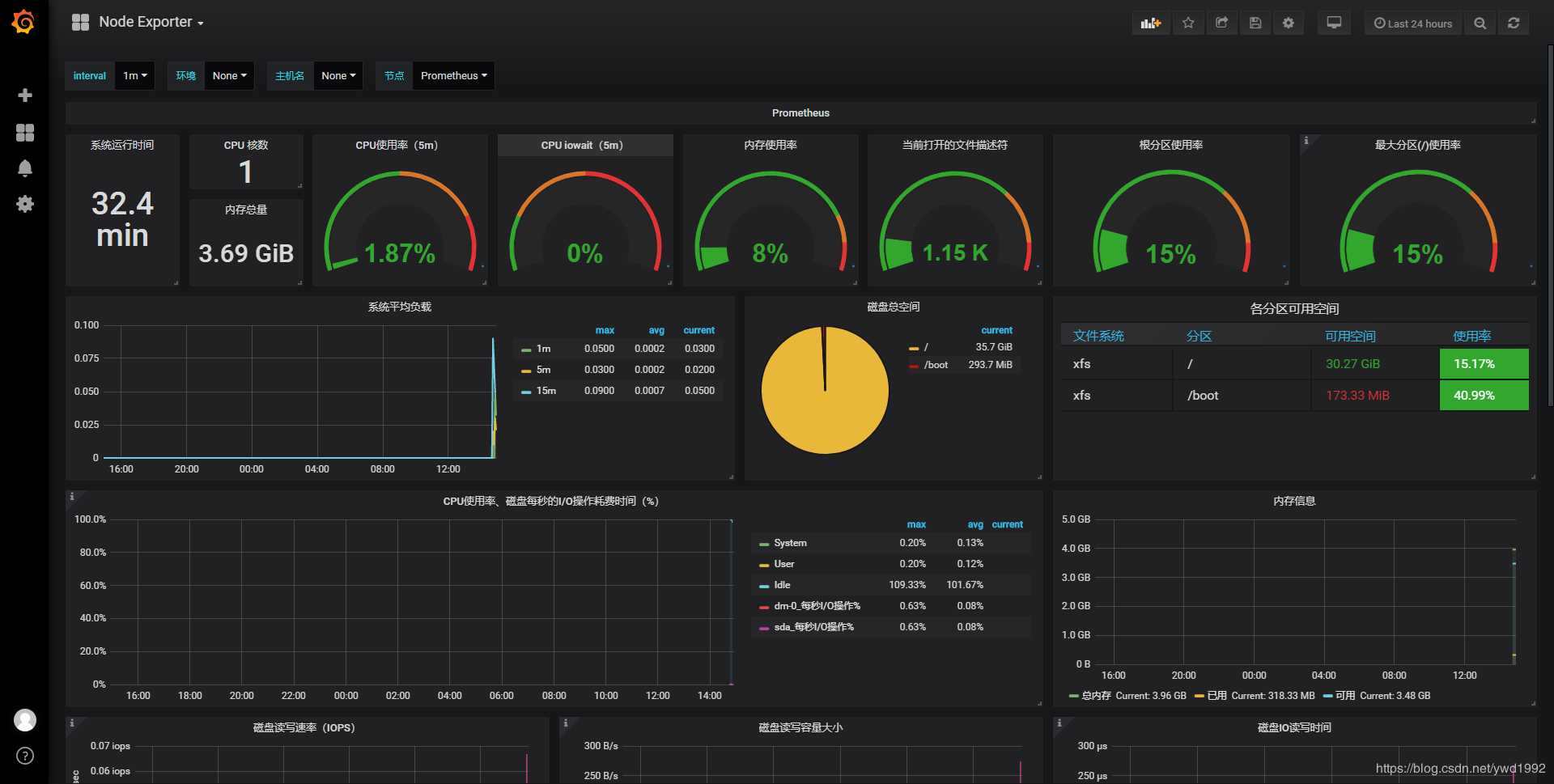
再刷新grafana页面,即可看到我们刚才设置好的node监控
https://github.com/martinlindhe/wmi_exporter/releases
(1)被监控windows机器安装wmi-exporter,会自动创建一个开机自启的服务
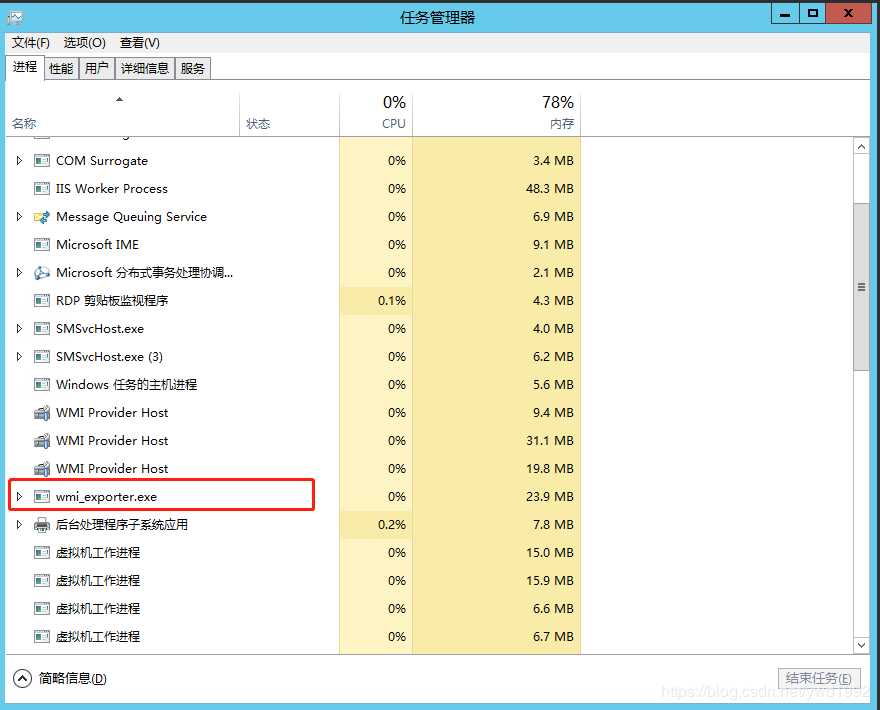
(2)普罗米修斯配置文件添加配置项
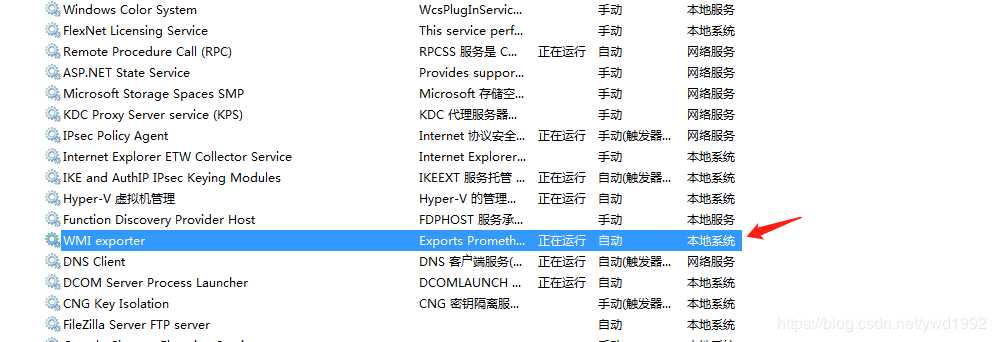
vim /usr/local/Prometheus/prometheus.yml
默认wmi-exporter端口为9182
- job_name: ‘Prometheus‘
static_configs:
- targets: [‘192.168.0.102:9182‘]
重启普罗米修斯
(3)grafana导入画好的dashboard,选择普罗米修斯数据源
链接:https://pan.baidu.com/s/1nfTE2dqcr6NYldlBm_lnfw 提取码:ohv4
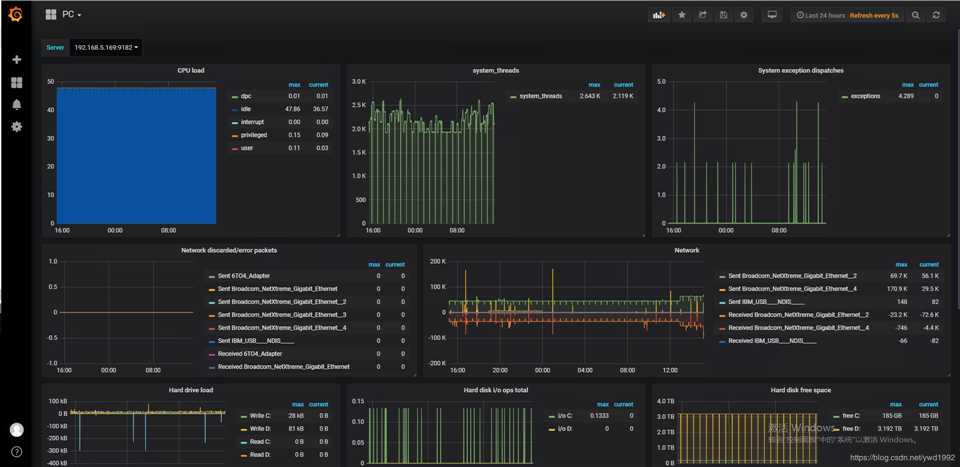
七:一些网些
1、https://grafana.com/grafana/dashboards --监控模板下载
参考
1、https://blog.csdn.net/wshl1234567/article/details/100107167
2、https://juejin.im/post/5d79d804e51d453b7779d5ce#heading-26
3、https://blog.csdn.net/ywd1992/article/details/85989259
标签:改名 表名 png 也会 opentsdb ons 字段 over 挂载
原文地址:https://www.cnblogs.com/dudu99/p/12303961.html