标签:Lucene style http io ar os sp strong on
没有开头语我会死啊~好的,IK是啥、怎么用相信看这篇文章的人都不需要我过多解释了,我也解释不好。下面开始正文:

从上至下的来看:
其中IKSegmenter在IK中默认三个实现:
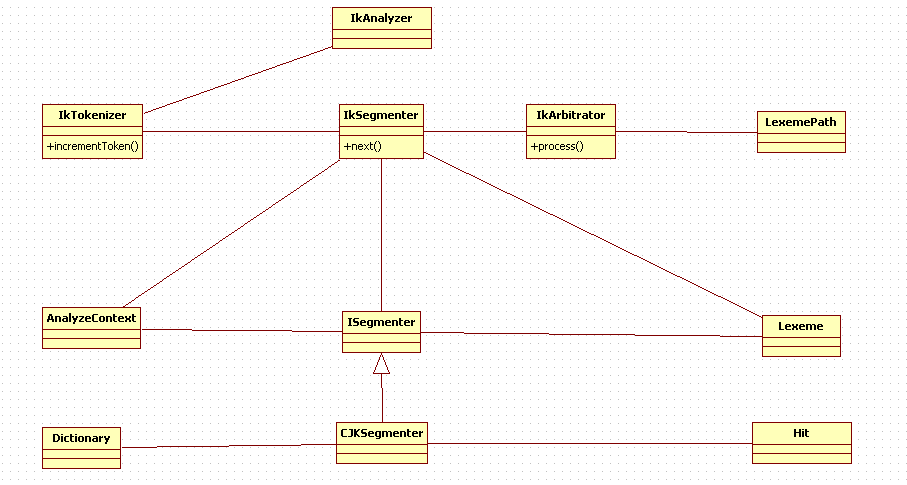
已经在3中描述。更具体的说是Segmenter会逐字识别词元,设输入”中华人民共和国“并且”中“单个字也是字典里的一个词,那么过程是这样的:”中“是词元也是前缀(因为有各种中开头的词),加入词元”中“;继续下一个词”华“,由于中是前缀,那么可以识别出”中华“,同时”中华“也是前缀因此加入”中华“词元,并把其作为前缀继续;接下来继续发现“华人”是词元,“中华人”是前缀,以此类推……
个人对迭代的理解就应是上述逐个前缀迭代的算法:中、中华、华人、中华人民、人民、中华人民共和国(举例而已,不全)。
如上就是正向的。
标签:Lucene style http io ar os sp strong on
原文地址:http://my.oschina.net/pangyangyang/blog/340325