标签:tput tis 文档 process ica anti 利用 虚拟变量 python
Scikit-learn will not accept categorical features by default
API里面不知使用默认的特征变量名,因此需要编码
这里我还是有疑问?
两种方式是一样的
pandas.get_dummies(data, prefix=None, prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)[source]Pandas中的get_dummy()函数是将拥有不同值的变量转换为0/1数值。
举例说明:一群样本的年龄分别为19,32,56,94岁,19岁用1表示,32岁用2表示,56岁用3表示,94岁用4表示。1,2,3,4这些数值的大小本身没有意义,只是用来区分年龄。因此在实际问题中,需要将1,2,3,4转化为0/1,即如果是19岁,则为0,若不是则为1,以此类推。
import pandas as pd
df = pd.DataFrame([
['green' , 'm'],
['red' , 'n'],
['blue' , 'q']])
df.columns = ['color', 'class']
pd.get_dummies(df) 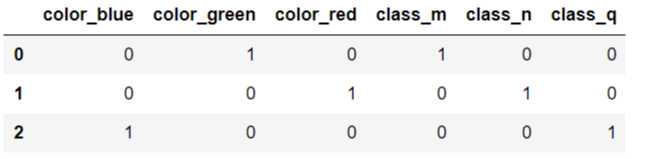
# Create dummy variables: df_region
df_region = pd.get_dummies(df)
# Print the columns of df_region
print(df_region.columns)
# Drop 'Region_America' from df_region
df_region = pd.get_dummies(df, drop_first=True)
# Print the new columns of df_region
print(df_region)填补缺失值:
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)主要参数说明:
# Import the Imputer module
from sklearn.preprocessing import Imputer
from sklearn.svm import SVC
# Setup the Imputation transformer: imp
imp = Imputer(missing_values='NaN', strategy='most_frequent', axis=0)
# Instantiate the SVC classifier: clf
clf = SVC()
# Setup the pipeline with the required steps: steps
steps = [('imputation', imp),
('SVM', clf)]连接多个转换器和预测器在一起,形成一个机器学习工作流
# Import necessary modules
from sklearn.preprocessing import Imputer
from sklearn.pipeline import Pipeline
from sklearn.svm import SVC
# Setup the pipeline steps: steps
steps = [('imputation', Imputer(missing_values='NaN', strategy='most_frequent', axis=0)),
('SVM', SVC())]
# Create the pipeline: pipeline
pipeline = Pipeline(steps)
# Create training and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Fit the pipeline to the train set
pipeline.fit(X_train, y_train)
# Predict the labels of the test set
y_pred = pipeline.predict(X_test)
# Compute metrics
print(classification_report(y_test, y_pred))
<script.py> output:
precision recall f1-score support
democrat 0.99 0.96 0.98 85
republican 0.94 0.98 0.96 46
avg / total 0.97 0.97 0.97 131```
标签:tput tis 文档 process ica anti 利用 虚拟变量 python
原文地址:https://www.cnblogs.com/gaowenxingxing/p/12307755.html