标签:big bom png 可变 计算 小端 存储 中国大陆 交换
字符和字节不太一样,任何一个文字或符号都是一个字符,但是所占字节不一定,不同的编码导致一个字符所占的内存不同。
例如:标点符号"+"是一个字符,汉字"我们"是两个字符,在GBK编码中一个汉字占2个字节,在UTF-8编码中一个汉字占3个字节。
随着时代的发展,程序员们希望在计算机中显示字符,但计算机只能识别0和1的二进制数。于是就有了编码规范。
所谓的字符集其实是一套编码规范中的子概念,为了显示字符,国际组织就指定了编码规范,希望使用不同的二进制数来表示代表不同的字符,这样电脑就可以根据二进制数来显示其对应的字符。我们通常就称呼其为xx编码,xx字符集。
例如:GBK 编码规范,根据这套编码规范,计算机就可以在中文字符和二进制数之间相互转换。而使用GBK编码就可以使计算机显示中文字符。
编码规范里的3个子概念:
一套编码规范不一定包含世界上所有的字符,每套编码规范都有自己的使用场景。而字库表就存储了编码规范中能显示的所有字符,计算机就是根据二进制数从字库中找到字符然后显示给用户,相当于一个存储字符的数据库。
例如:几乎所有汉字都保存在GBK编码规范的字库表中。所以可以显示汉字,但法语、俄语并不在其字库表中,所以GBK不能显示法语、俄语等不包含在其中的字符。
在一个字库表中,每一个字符都有一个对应的二进制地址,而编码字符集就是这些地址的集合。字符集和字库表一一对应,相互转换,这是电脑识别字符的关键。
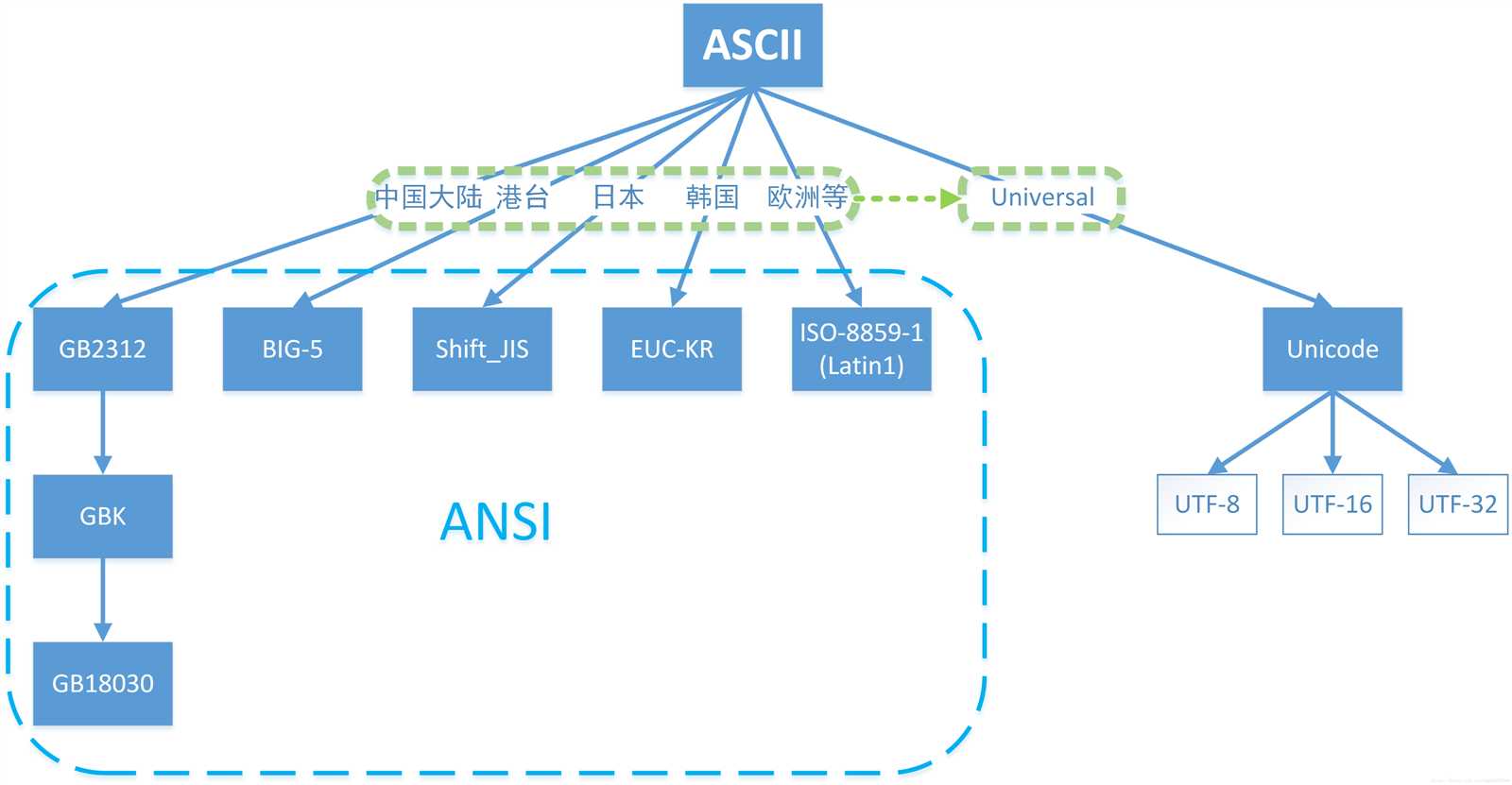
如果把世界上不同国家文明的所有字符都放在一起组成一个集合,那么我们常见的 ASCII、GB2312、GBK、GB18030、BIG5 字符集都只是包含了该集合的一部分而已。而Unicode字符集是可以包含所有国家文明中的所有字符的。
知道字库表和编码字符集后,我们就可以直接使用二进制地址来得到字符了。但直接使用字符对应的二进制地址来显示文字是十分浪费的,Unicode 编码规范中包括了几百万个字符,想要包括几百万个不同的字符,起码需要3个字节的容量,为了方便将来扩展,Unicode还保留了更多未使用的空间,最多可以存储4个字节的容量。
因此为了区分每个字符,哪怕是00000000 00000000 00000000 00001111这种其实只占了一个字节的字符,我们也要为它分配4个字节的空间,这就导致一个可以用1G保存的文件,现在需要4G才能保存,这是极其浪费的做法。
于是程序员就定下了一套算法来节省空间,而每种不同的算法都被称作一种编码方式。一套编码规范可以有多种不同的编码方式,不同的编码方式有不同的适应场景。例如:UTF-8就是一种编码方式,Unicode是一种编码规范。此外Unicode还有UTF-16、UTF-32这两种编码方式。不同的编码方式节约的空间不同。总结:一个较短的二进制数,通过一种编码方式,转换成编码字符集中正常的地址,然后在字库表中找到一个对应的字符,最终显示给用户。
计算机一开始发明的时候是用来解决数字计算的问题,后来人们发现,计算机还可以做更多的事,例如文本处理。但由于计算机只识"数",因此人们必须告诉计算机哪个数字来代表哪个特定字符,例如65代表字母‘A‘,66代表字母‘B‘,以此类推。但是计算机之间字符-数字的对应关系必须得一致,否则就会造成同一段数字在不同计算机上显示出来的字符不一样。因此美国国家标准协会ANSI制定了一个标准,规定了常用字符的集合以及每个字符对应的编号,这就是ASCII字符集(Character Set)也称ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)。
为了表示更多的欧洲等国家使用的字符,对原始的ASCII编码范围进行了扩充,采用一个字节256种不同状态来表示256种不同的字符。ISO-8859-1编码是单字节编码,向下兼容ASCII,它的编码范围使用了单字节内的所有空间(即8位,0-255),在支持ISO-8859-1的系统中传输和存储其他任何编码的字节流都不会被抛弃。换言之,把其他任何编码的字节流当作ISO-8859-1编码看待都没有问题。这是个很重要的特性,MySQL数据库默认编码是Latin1就是利用了这个特性。ASCII编码是一个7位的容器,ISO-8859-1编码是一个8位的容器。
上面我们提到的字符集都是基于单字节编码,也就是说一个字节翻译成一个字符,这对于拉丁语系国家来说足够了。但是对于亚洲国家来说,256个字符是远远不够用。因此在保持和ASCII字符集的兼容下,就发明了多字节编码方式,相应的字符集就称为多字节字符集。对于单字节字符集来说,代码页中只需要有一张码表即可,上面记录着256个数字代表的字符,程序只需要做简单的查表操作就可以完成编解码的过程。对于多字节字符集,代码页中通常会有很多码表,根据第一个字节来选择不同的码表进行解析。
目前最常用的中文字符集GB2312,涵盖了所有简体字符以及一部分其他字符;GBK则在GB2312的基础上加入了对繁体字符等其他非简体字符。GBK字符集中所有字符占2个字节,不论中文英文都是2个字节。从ASCII、GB2312到GBK,这些编码方法是向下兼容的,即同一个字符在这些方案中总是有相同的编码,后面的标准支持更多的字符。在这些编码中,英文和中文可以统一地处理。区分中文编码的方法是高字节的最高位不为0。GB2312、GBK都属于双字节字符集(DBCS)
不同ASCII衍生字符集的出现,会让文档交流变得非常困难。如美国ANSI组织制定了ANSI标准字符编码,ISO组织制定的各种ISO标准字符编码,还有各国也会制定一些国家标准字符集,例如中国的GBK,GB2312和GB18030。
操作系统在发布的时候,通常会往机器里预装这些标准的字符集还有平台专用的字符集,这样只要你的文档是使用标准字符集编写的,通用性就比较高了。例如你用GB2312字符集编写的文档,在中国大陆内的任何机器上都能正确显示。同时,我们也可以在一台机器上阅读多个国家不同语言的文档了,前提是本机必须安装该文档使用的字符集。
虽然通过使用不同字符集,我们可以在一台机器上查阅不同语言的文档,但是我们仍然无法解决一个问题:在一份文档中显示所有字符。为了解决这个问题,我们需要一个全人类达成共识的巨大的字符集,这就是Unicode字符集。Unicode简称为UCS。Unicode字符集涵盖了目前人类使用的所有字符,并为每个字符进行统一编号,分配唯一的字符码(Code Point)。Unicode字符集将所有字符按照使用上的频繁度划分为17个层面(Plane),每个层面上有2^16=65536个字符码空间。其中第0个层面BMP,基本涵盖了当今世界用到的所有字符。其他的层面要么是用来表示一些远古时期的文字,要么是留作扩展。我们平常用到的Unicode字符,一般都是位于BMP层面上的。
在Unicode出现之前,所有的字符集都是和具体编码方案绑定在一起的,都是直接将字符和最终字节流绑定死了。例如ASCII编码系统规定使用7比特来编码ASCII字符集;GB2312以及GBK字符集,限定了使用最多2个字节来编码所有字符,并且规定了字节序。这样的编码系统通常用简单的查表,也就是通过代码页就可以直接将字符映射为存储设备上的字节流了。这种方式的缺点在于,字符和字节流之间耦合得太紧密了,从而限定了字符集的扩展能力。因此Unicode在设计上考虑到了这一点,将字符集和字符编码方案分离开。
例如同样是对Unicode字符"A"进行编码,UTF-8字符编码得到的字节流是0x41,而UTF-16(大端模式)得到的是0x00 0x41。UCS只是规定如何编码,并没有规定如何传输、保存这个编码,关键在于通信双方都要认可。UTF是"UCS Transformation Format"的缩写。
UCS有两种格式:UCS-2和UCS-4。UCS-2就是用两个字节编码,它有2^16=65536个码位,UCS-4就是用4个字节编码(实际上只用了31位,最高位必须为0),它有2^31=2147483648个码位。对于Unicode来说,UCS-2和UCS-4是字符码(内码)。
UTF-8编码方案采用1-4个字节来编码字符,对于ASCII字符的编码使用单字节,和ASCII编码一摸一样。对于其他字符,则使用2-4个字节来表示。其中首字节前置1的数目代表正确解析所需要的字节数,剩余字节的高2位始终是10。例如首字节是1110xxxx,前置有3个1说明正确解析总共需要3个字节,需要和后面2个以10开头的字节结合才能正确解析得到字符。
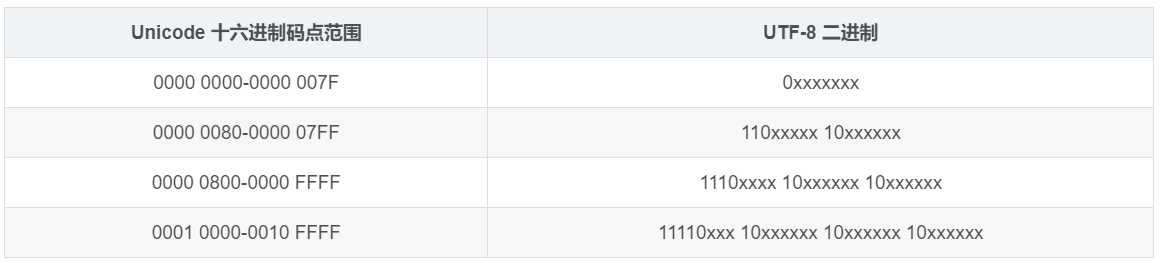
如上表所示,对于只需要1个字节的字符,UTF-8采用ASCII码的编码方式,最高位补0来表示。例如:01000001我们就是用01000001来表示,对于一个字节的字符,其实就是直接使用地址表示。而对于n个字节的字符(n>1),即大于一个字节的字符,采用第一个字节前n位补1。第n+1位填0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode字符码。
例如:汉字严的Unicode码是4E25转换成二进制就是 01001110 00100101,根据上表可知使用UTF-8字符编码后占3个字节,因此前3位是1,第4位(n+1位)是0,后面两个字节中每个字节的前两位都是10,即1110 xxxx 10 xxxxxx 10 xxxxxx。填充进去后就变成了1110 0100 10 111000 10 100101共计24位占3个字节。
由此可见,英文在UTF-8字符编码后只占1个字节,中文占了3个字节。
带签名指的是字节流以BOM标记开始。很多软件会"智能"地探测当前字节流使用的字符编码,这种探测过程出于效率考虑,通常会提取字节流前面若干个字节,看看是否符合某些常见字符编码的编码规则。由于UTF-8和ASCII编码对于纯英文的编码是一样的,无法区分开来,因此通过在字节流最前面添加BOM标记可以告诉软件,当前使用的是Unicode编码,判别成功率就十分准确了。但是需要注意,不是所有软件或者程序都能正确处理BOM标记,例如PHP就不会检测BOM标记,直接把它当普通字节流解析了。因此如果你的PHP文件是采用带BOM标记的UTF-8进行编码的,那么有可能会出现问题。
UTF-16 是介于 UTF-8 和 UTF-32 之间,使用2个或者4个字节来存储的,其长度即固定又可变。
UTF-32 是固定长度的编码,始终占用 4 个字节,足以容纳所有的 Unicode 字符。所以直接存储 Unicode 编号即可,不需要任何编码转换。浪费了空间,提高了效率。
任何能够将Unicode字符映射为字节流的编码都属于Unicode编码。中国的GB18030编码,覆盖了Unicode所有的字符,因此也算是一种Unicode编码。只不过他的编码方式并不像UTF-8或者UTF-16一样,将Unicode字符的编号通过一定的规则进行转换,而只能通过查表的手段进行编码。
GBK、GB2312等与UTF-8之间都必须通过Unicode编码才能相互转换:
GBK、GB2312 -- Unicode字符码 -- UTF-8
UTF-8 -- Unicode字符码 -- GBK、GB2312
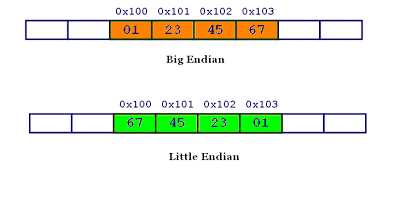
计算机硬件有两种储存数据的方式:大端字节序(big endian)和小端字节序(little endian)
大端字节序:高位字节在前,低位字节在后,这是人类读写数值的方法。
小端字节序:低位字节在前,高位字节在后。
举例来说:0x1234567的大端字节序和小端字节序的写法如下
为什么会有小端字节序?计算机电路先处理低位字节,效率比较高,因为计算都是从低位开始的。所以计算机的内部处理都是小端字节序。但是人类还是习惯读写大端字节序,所以除了计算机的内部处理,其他的场合几乎都是大端字节序,比如网络传输和文件储存。
计算机处理字节序的时候,不知道什么是高位字节,什么是低位字节。它只知道按顺序读取字节,先读第一个字节,再读第二个字节。如果是大端字节序,先读到的就是高位字节,后读到的就是低位字节。小端字节序正好相反。所以只有在读取的时候,才必须区分字节序,其他情况都不需要考虑。处理器读取外部数据的时候,必须知道数据的字节序,将其转成正确的值。然后,就正常使用这个值,完全不用再考虑字节序。即使是向外部设备写入数据,也不用考虑字节序,正常写入一个值即可。外部设备会自己处理字节序的问题。
计算机界对于传输多字节字(由多个字节来共同表示一个数据类型)时,是先传高位字节(大端)还是先传低位字节(小端)也有着不一样的看法。无论是写文件还是网络传输,实际上都是往流设备进行写操作的过程,而且这个写操作是从流的低地址向高地址开始写。对于多字节字来说,如果先写入高位字节,则称作大端模式。反之则称作小端模式。也就是说,大端模式下,字节序和流设备的地址顺序是相反的,而小端模式则是相同的。一般网络协议都采用大端模式进行传输。
乱码指的是程序显示出来的字符文本无法用任何语言去解读。造成乱码的原因就是因为使用了错误的字符编码去解码字节流。当程序使用特定字符编码解析字节流的时候,一旦遇到无法解析的字节流时,就会用?或者?来替代。因此,一旦你最终解析得到的文本包含这样的字符,而你又无法得到原始字节流的时候,说明正确的信息已经彻底丢失了,尝试任何字符编码都无法从这样的字符文本中还原出正确的信息来。
经过上边的介绍,我们可以大致认为,现在流行的一些编码方案都是在兼容ASCII的基础上来实现的。为了满足各国家地区的更多字符的编码需求,出现了ANSI编码标准,但是该编码标准在具体各地区国家的实现上是彼此不兼容的。为了满足世界各国字符编码的兼容性需求,Unicode定义了一个统一、完备的字符集。为了实现Unicode字符集在编码上的需求,又诞生了UTF-8、UTF-16等等编码方案。
标签:big bom png 可变 计算 小端 存储 中国大陆 交换
原文地址:https://www.cnblogs.com/xi-jie/p/12309045.html