标签:左右 地方 article 展示 center 疑惑 padding int detail
本来只是想查一下为什么FFT点数 n_fft和窗长 win_length默认是相等的,但翻了好多博客和文献后发现自己对STFT存在很多的误解。所以在这里以liborsa的stft()为例,记录下各个参数的释义,以及它们选取不同的值对数据的影响。
对一段语音进行短时傅里叶变换的代码为:R = librosa.core.stft(r, n_fft, hop_length, win_length, window, center, pad_mode),其中输入为:
r语音信号n_fftFFT点数,也是补零后每一帧信号的长度。输出的行数与n_fft有关,为n_fft/2+1hop_length帧移。可以理解为下一帧相对上一帧移动了多少个采样点。使用更小的值可以在不减少频率分辨率的情况下增加输出的列数。默认是win_length/4win_length窗长。使用该长度的窗函数截取语音后得到每一帧信号。更小的值会在牺牲STFT频率分辨率的同时增加其时间分辨率center默认为Ture,即在原信号r的左右两边分别补上n_fft//2个点,使得第t帧的信号以r[t*hop_length]为中心点。当为False时,第t帧的信号以r[t*hop_length]为起点pad_mode默认为”reflect”,即在center=True时,采用镜像模式对r进行填补,比如[1, 2, 3, 4]会被补为[3, 2, 1, 2, 3, 4, 3 ,2]这部分主要参考了快速傅里叶变换(FFT)中为什么要“补零”?[1]、FFT Zero Padding[2]和Zero Padding Applications[3]
在liborsastft()中,时间分辨率(Temporal Resolution)的解释为:在时域中分辨出紧邻的冲击的能力。频率分辨率(Frequency Resolution)的解释为:在频域中分辨出紧邻的单频率音的能力。与二者相关的参数分别是win_length和n_fft,表现为win_length越小,时间分辨率越大;n_fft越大,频率分辨率越大。
我之前有一个疑惑是,文献[4]中所说:“成功进行语音分离需要具备较高的频率分辨率,这就要求在STFT时使用更长的时间窗。但时间窗的长度和系统时延是挂钩的,更长的时间窗会导致更大的时延。”那么这里为什么不选取一个较小的win_length和一个较大的n_fft,这样不就能同时提升两个分辨率了?我在实验里测试了几组数据并没有发现特别不同的地方啊。
之所以得到这个错误的判断是自己只注重拿来主义,函数能跑通就行了,没有思考过里面的原理。实际上,不能只按照win_length <= n_fft来选取它们。在实际操作中,当每帧长度不等于FFT点数时,要将窗函数的两边同时补零到n_fft长度且对每帧数据加窗(参考librosa代码和torch.stft()的说明文档)后,才能进行FFT。但这不并不是说因为会自动补零,就可以随便选取win_length。具体解释如[1]和[2]所示:
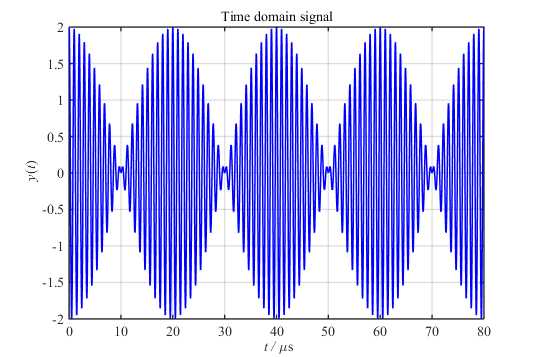
假设一个信号包含两个频率分别为\(1MHz\)和\(1.05MHz\)余弦波,采样率为\(F_S=100MHz\),且当前有\(1000\)个点的数据:
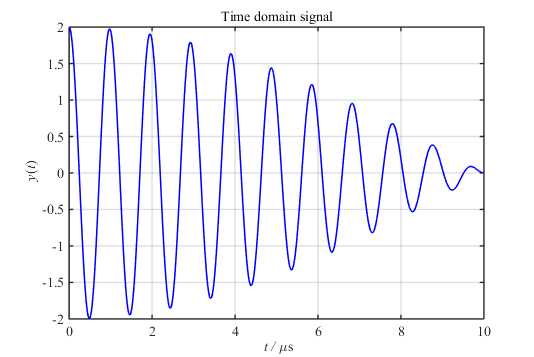
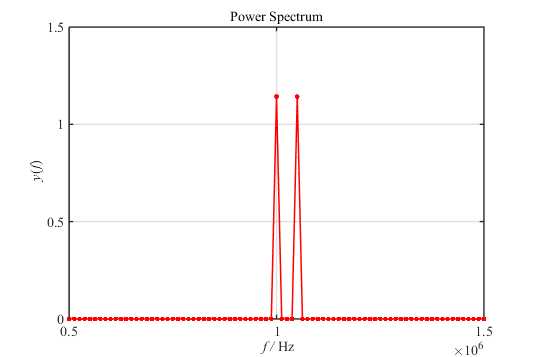
对其进行\(1000\)点FFT后得到的频谱图为:
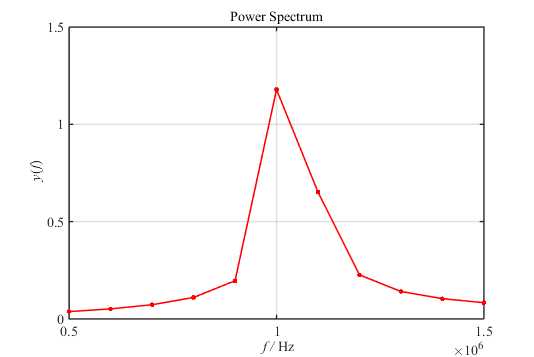
然而,在图2中我们是无法分辨出两个“紧邻的单频率音”(余弦波)的。按照我之前的理解,这是频率分辨率不够,只要增大FFT点数就能分辨出了。要做到这一步,首先需要对原信号进行补零:
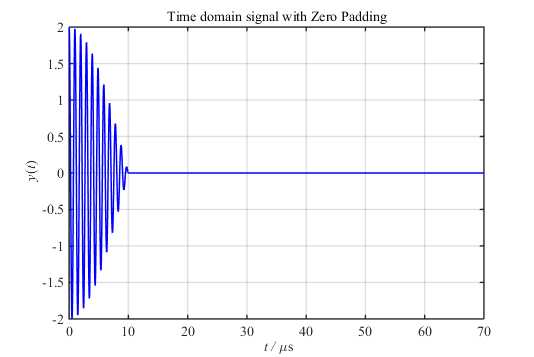
然后对补零后的数据进行\(7000\)点FFT:
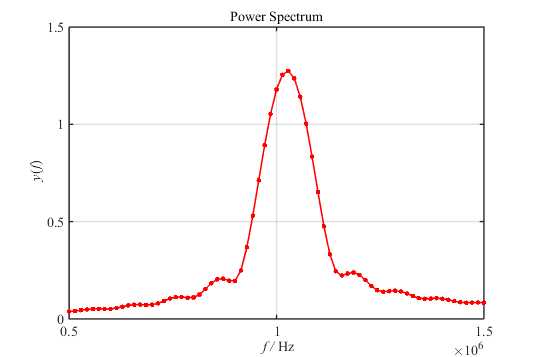
由图4可得,\(7000\)点FFT后我们还是无法从频谱图中分辨出两个余弦波。这是因为频率分辨率分为波形频率分辨率(Waveform Frequency Resolution)和FFT分辨率(FFT Resolution):
\[
\begin{equation}
\Delta R_w=\frac{1}{T}
\end{equation}
\tag{1}
\]
\[
\begin{equation}
\Delta R_{fft}=\frac{F_s}{N_{fft}}
\end{equation}
\tag{2}
\]
式中,\(T\)为原始数据的时长,\(N_{fft}\)为FFT点数。当\(T\)不变时,不论如何提升\(N_{fft}\),都不能提高波形频率分辨率\(\Delta R_w\)。[3]中对此的解释是:“在时域或频域内补零,只能提升另一个域内的插值密度(Interpolation-density),而非提升分辨率。”
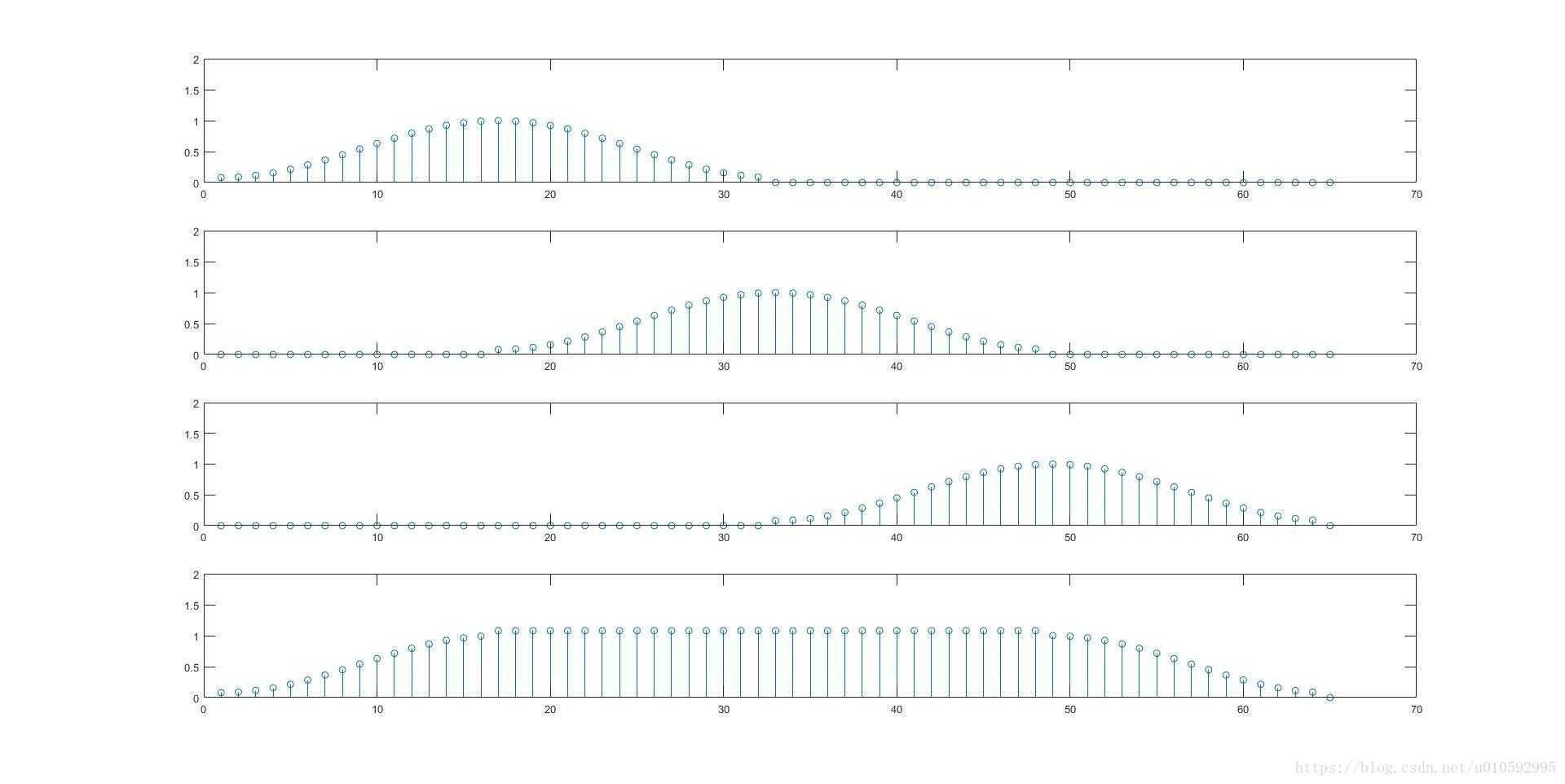
为了提升FFT分辨率,我们要收集更多的原始数据,做点数更大的FFT:
此时能够在图6中清楚地分辨出两个频率的波形。所以,要提升频率分辨率,必须同时增大每帧数据的长度win_length和FFT点数n_fft。
需要注意的是,在画语谱图时我们只需要频谱图的一半,此时的FFT分辨率为\(\Delta R_{fft}=\frac{F_s}{N_{fft}}=\frac{\frac{F_s}{2}}{\frac{N_{fft}}{2}}\)。语谱图能够展示的频率范围为\([0,\frac{F_s}{2}]\),这一点也可以通过奈奎斯特采样定理来解释。
这部分主要参考了STFT使用overlap-add重建信号[5]、Overlap-Add (OLA) STFT Processing[6]。
既然win_length和n_fft的值都不能随便选,那么hop_length...
没错,在选择窗函数和帧移时,必须要满足Constant Overlap-Add(COLA):
\[
\begin{equation}
\sum\limits_{m=-\infty}^{\infty}w(n-mR)=1,\forall n\in\mathbb{Z}
\end{equation}
\tag{3}
\]
COLA确保了输入中的每个点都有同样的权值,从而避免出现时域混叠(aliasing),以及确保ISTFT能够完美地重构原信号[7]。这是因为,在对语音进行分帧加窗时,每帧之间存在重叠的部分,且该部分在ISTFT后也会存在。比如使用矩形窗就不能完美地重构原信号:
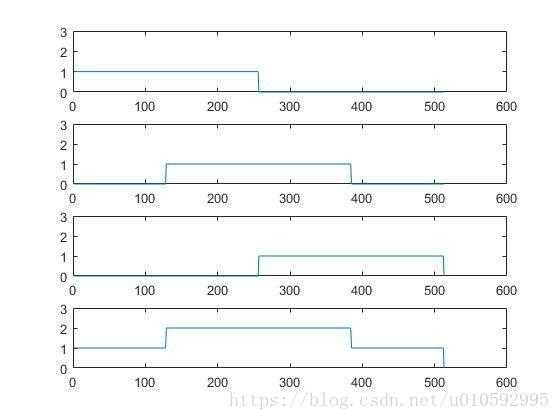
center=Ture。因为这部分无法完美重构,所以要在原数据左右两端补上\(\frac{N_{fft}}{2}\)个点,人为地让原始语音在能够完美重构信号的范围内。
在STFT中常用的\(\frac{1}{2}\)、\(\frac{2}{3}\)、\(\frac{1}{4}\)重叠率的汉宁窗符合COLA。
[4] Luo, Yi, and Nima Mesgarani. "Tasnet: time-domain audio separation network for real-time, single-channel speech separation." 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2018.
标签:左右 地方 article 展示 center 疑惑 padding int detail
原文地址:https://www.cnblogs.com/Ge-ronimo/p/12298403.html