标签:XML chrome == python列表 https cto http style 指定
参考文档:https://weread.qq.com/web/reader/37132a705e2b2f37196c138k98f3284021498f137082c2e
说明:我才接触网络爬虫,在看《python网络爬虫入门到实践》一书时,作者写了个实例获取豆瓣电影TOP250的所有电影的电影名称,我在此基础上进行了更进一步的改进,获取了所有的相关信息,并用表格将这些信息保存下来。
相关知识:
网络爬虫分为三个步骤: 第一步:伪装为浏览器访问;第二步:解析网页代码;第三步:存储数据。
(1)第一步使用requests模块实现
我们需要使用到request模块的get()方法,该方法模仿为浏览器访问,返回的是网页代码内容。
参考文档:http://cn.python-requests.org/zh_CN/latest/user/quickstart.html#url
(2)第二步使用BeautifulSoup模块实现
我们需要用到BeautifulSoup的find()方法。使用find()方法可通过标签的不同属性过滤html页面。定义如下:
find(self, name=None, attrs={}, recursive=True, text=None, **kwargs)
name:可以传入一个标签或多个标签名称组成的python列表。例如:findAll([‘h1’, ‘h2’])
attrs:用一个python字典封装的一个标签的若干属性和对应的属性值。例如:findAll(‘span’, {‘class’: {‘green’, ‘red’}})
recursive:布尔变量,若为True,会根据要求去查找标签参数的所有子标签,以及子标签的子标签。若为False,只查找文档的一级标签。
text:用标签的文本内容去匹配,而不是标签的属性。
kwargs:选择那些具有指定属性的标签。
参考链接:https://www.crummy.com/software/BeautifulSoup/bs3/documentation.zh.html
第三步我们将数据存放在表格中。
我们使用xlwt模块进行表格的写入操作,将获取到的信息保存到表格中。
代码如下:
1 # encoding:utf-8 2 3 ‘‘‘ 4 目的:获取豆瓣电影TOP250的所有电影的相关信息,网页地址为:https://movie.douban.com/。 5 环境:python 3.7.3 6 所需的库:requests、BeautifulSoup、xlwt 7 ‘‘‘ 8 9 import logging 10 import xlwt 11 import requests 12 import string 13 from bs4 import BeautifulSoup 14 15 headers = { 16 ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36‘,17 ‘Host‘: ‘movie.douban.com‘ 18 } 19 20 # 将获取的信息保存到表格中 21 def save_movie(content): 22 workbook = xlwt.Workbook(encoding = ‘ascii‘) 23 worksheet = workbook.add_sheet(‘Movies info‘) 24 style = xlwt.XFStyle() # 初始化样式 25 font = xlwt.Font() # 为样式创建字体 26 font.name = ‘Times New Roman‘ 27 font.bold = True # 黑体 28 font.underline = True # 下划线 29 font.italic = True # 斜体字 30 style.font = font # 设定样式 31 worksheet.write(0, 0, ‘title‘) 32 worksheet.write(0, 1, ‘actor‘) 33 worksheet.write(0, 2, ‘score‘) 34 worksheet.write(0, 3, ‘quote‘) 35 for i, item in enumerate(content): 36 for j in range(4): 37 worksheet.write(i+1, j, content[i][j]) 38 workbook.save(‘./movie_info.xls‘) # 保存文件 39 40 41 # 获取与move相关的信息 42 # 主要包括:title、actor、score、quote 43 def get_moves(): 44 movies_info = [] 45 movies_titles = [] 46 movies_actors = [] 47 movies_scores = [] 48 movies_quotes = [] 49 50 for i in range(10): 51 link = ‘https://movie.douban.com/top250?start=%d&filter=‘ % i*25 52 r = requests.get(link, headers=headers, timeout=10) 53 print (str(i+1), ‘页响应状态码:‘, r.status_code) 54 soup = BeautifulSoup(r.text, ‘lxml‘) 55 soup = BeautifulSoup(r.text, ‘lxml‘) 56 div_hd_list = soup.findAll(‘div‘, {‘class‘: ‘hd‘}) 57 div_bd_list = soup.findAll(‘div‘, {‘class‘: ‘bd‘}) 58 score_list = soup.findAll(‘span‘, {‘class‘: ‘rating_num‘}) 59 quote_list = soup.findAll(‘p‘, {‘class‘: ‘quote‘}) 60 for item in div_hd_list: 61 title = item.a.span.text.strip() 62 movies_titles.append(title) 63 for i, item in enumerate(div_bd_list): 64 if (i == 0): continue 65 content = item.p.text.strip().replace(u‘\xa0‘, u‘‘) 66 actor = content[: content.find(u‘主演‘)] 67 actor = actor[:actor.find(u‘主‘)] 68 movies_actors.append(actor) 69 for item in score_list: 70 score = item.text.strip() 71 movies_scores.append(score) 72 for item in quote_list: 73 quote = item.span.text.strip() 74 movies_quotes.append(quote) 75 print (len(movies_actors)) 76 print (len(movies_quotes)) 77 for i in range(len(movies_titles)): 78 item = [movies_titles[i], movies_actors[i], movies_scores[i], movies_quotes[i]] 79 movies_info.append(item) 80 81 return movies_info 82 83 84 if __name__ == "__main__": 85 movies_info = get_moves() 86 save_movie(movies_info)
上述代码在获取“导演”这个信息时,使用div_bd_list = soup.findAll(‘div‘, {‘class‘: ‘bd‘})获取到的列表第一个元素需要除去,不是我们想要的元素。
另外代码中的header信息可以在浏览器(我使用的是chrome)中获得:在chrome中点击检查,在选择network可以看到Request Headers请求头的主要信息。
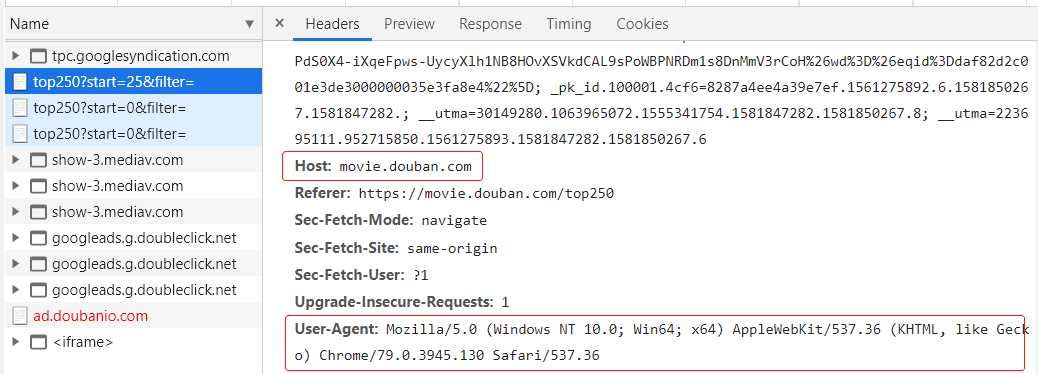
标签:XML chrome == python列表 https cto http style 指定
原文地址:https://www.cnblogs.com/mrlayfolk/p/12319414.html