标签:对象 value aggregate 表名 http name 第一条 author 生成
基于对象查询的通式就是:先查找到已知条件,然后使用关联方法去查(正、反不同)。
(1)正向查询和反向查询
由关联表去查被关联表,叫正向查询。反之,为反向查询。
分正向、反向查询的原因:
正、反查询方法不同。正向查询通过关联属性去查,而反向查询通过关联表的表名小写去查。(反正都和关联表有关)
(2)一对一
首先明晰四张表和多对多关系生成表的关系和字段
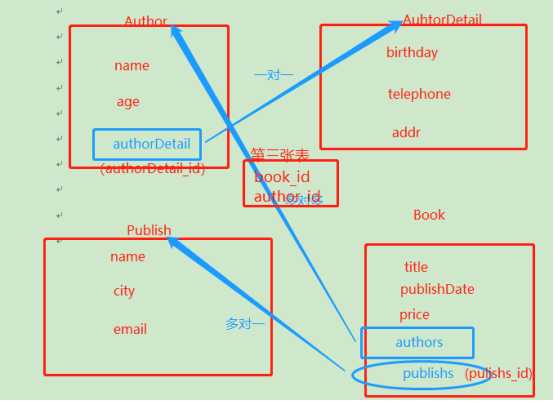
A.正向查询 关联属性名
#查询张三的地址
首先找到张三(张三在Book)

注:.first()是拿到第一条记录。是model对象
其次,判断关联方法
由Author表查AuthorDetail表是正向查询,用关联属性名:

Author_obj.authorDetail就关联到AuthorDetail表了,再通过点的方式查到里面具体的字段值
B.反向查询 关联表类名小写
#通过地址苏州查出是谁住那
首先:找到苏州的那个记录(在AuthorDetil表中)

其次:判断关联方法
这是反向查询。用关联表类名的小写去关联到关联表

author_detail_obj.author就关联到关联表了,再通过点的方式调用其中的name.
(3)一对多
一对多和一对一方法一样。只是在反向查询时(一对多固定的外键(关联属性)在多的一方,意味着从多到一是正向,从一到多为反向),查询的结果是个集合,此时关联方法为关联类名的小写_set方式,不同于一对一反向查询直接关联类名的小写。
A正向查询 关联属性名
#查询三国演义这本书的出版社是那个

B反向查询 关联表类名小写_set
# 查询人民出版社出版哪些书

.all()就查出该集合所有的记录。
(4)多对多
多对多和一对多查询方式一样
A正向查询 关联属性名
#三国演义这本书谁写的 (Book---------》Author)

B反向查询 关联表类名小写_set
# 张三写了哪些书

基于双下划线的查询就一句话:正向查询按字段,反向查询按表名小写用来告诉ORM引擎join哪张表,一对一、一对多、多对多都是一个写法
注:基于上下划线的正、反向查询是基于具体查询时通过哪张表查询。因此一个查找会有正反两个方法。而基于对象查询的是在读题是就确定唯一一个查询(是正向还是反向?)
(1)一对一
查询张三的地址:(Author AuthorDetail)
Models.Author.objects.filter(name=”张三”).values(“authorDetail__addr”) 正向
Modesl.AuthorDetail.objects.filter(author__name=”张三”).values(“addr”) 反向
查询在苏州的作者名字
Models.Author.objects.filter(authorDetail__addr=”苏州”).valuse(“name”) 正向
Models.AuthorDetail.objects.filter(addr=”苏州”).values(“author__name”) 反向
总结:
A.首先确定是用正向还是反向方法,决定models.类名.objects. 的类名是什么。
B题目中有:由a查出b。a在filter()里,b在.values()里。根据前面的类名找出a,b哪个在类里,直接写。(注:filter()里是关键字的形式。values()里是字符串的形式)
C.剩下一个根据正向反向原则去写:正向写关联属性名,反向写关联类名小写。加双下划线__
(2)一对多
查询三国演义这本书的出版社是那个 (Book 、Publish)
Models.Book.objects.filter( title=”三国演义”).values(“publishs__name”) 正向
Models.Publish.objects.filter(book__title=”三国演义”).values(“name”) 反向
查询人民出版社出版哪些书 (Book 、Publish)
Models.Book.objects.filter(pubishs__name=”人民出版社”).values(“title”) 正向
Models.Publish.objects.filter(name=”人民出版社”).values(“book__title”) 反向
(3)多对多
三国演义是谁写的 (Book Author)
Models.Book.objects.filter(title=”三国演义”).values(“authors__name”) 正向
Models.Author.objects.filter(book__title=”三国演义”).values(“”name) 反向
张三写了哪些书
Models.Book.objects.filter(authors__name=”张三”).values(“title”)
Models.Author.objects.filter(name=”张三”).values(“book__titele”)
(4)进阶查询------多张表
人民出版社出版的书及作者的名称 (Book Author Publish)
Models.Book.objects.filter(publishs__name=”人民出版社”).values(“title”,”authors__name”) Models.Author.objects.filter(book__publishs__name=”人民出版社”).values(“book__title”,”name”) Models.Publish.objects.filter(name=”人民出版社”).values(“book__title”,”book__authors__name”)
手机号以5开头的作者出版过的所有书籍名称以及出版社名称
四张表 (AuthorDetail,Author,Publish,Book)
方式一:
Models.AuthorDetial.filter(telephone__startswith(“5”)).values(“author__book__title”,”author__book__publishs__name”)
方式二:
Models.Author.objects.filter(authorDetail__telephone__startswith(“5”)).values(“book__title”,”book__publishs__name”)
方式三:
Models.Publish.objects.filter(book__authors__authorDetail__telephone__startswith(“5”)).values(“book__title”,”name”)
方式四:
Models.Book.objects.filter(authors__authorDetail__telephone__startswith(“5”)).values(“title”,”publishs__name”)
关键点:

弄清正向反向关系(正向用关联属性名,反向用关联表类名小写)
以控制器的表为基础,去找。Filter里是已知条件,values里是未知条件。
1.分组
(1)单表分组查询
查询每个出版社的名称以及所在的出版书的本数
A.sql语句
Select title,count(*) from Book group by publishs_id
B.ORM语句
ret=models.Book.objects.values(‘publishs_id’).annotate(a=Count(‘id’)).values(‘title’,’a’)
注:values为分组依据。不写默认依据为id。Annotate里面是聚合函数,而其要有别名。Annotate是对分组统计的结果,即要统计的内容。values进行取值
(2)多表查询
统计每个出版社出版的书籍的平均价格(Book,)
方式一
ret = models.Book.objects.values(‘publishs‘).annotate(a=Avg(‘price‘)).values(‘a’)
分组依据是出版社。从Book表开始找,publishs是关系属性,可作为分组依据(publish_id也可)。聚合函数里直接统计price
方式二:
ret=models.Publish.objects.annotate(a=Avg(‘book__price‘)).values(‘a’)
这个方式更直观。分组依据是出版社,直接从Publish表开始找。不写values(分组依据),默认通过Publish的id去找。统计内容书的平均价格,不在Publish表,在Book表中,因此要通过双下划线进行联表操作。反向查询用关联表名小写,所以为book__price
注意:values()里可以写多个分组依据。当values里所有字段共同相同时才算一组。
总结:跨表分组查询本质就是将关联表join成一张表。可以通过双下划线的方式跨表查询。
2.F查询和Q查询
(1)F查询
F查询针对单表的操作(自己表的两个字段进行比较、字段进行运算)
查询书的点赞数大于评论数的书
from django.db.models import F Ret=models.Book.objects.filter(goot__gt=F(‘comment’)))
让书籍表中所有书的价格都加上10
models.Book.objects.all().update(price=F(‘price‘)+10)
(2)Q查询
Filter里的关键字查询都是按照AND(,)查询的,Q查询提供更多的查询方法。或|、与&、非(~)
查询评论数和点赞数都大于80的书籍
ret=models.Book.objects.filter(Q(good__gt=80)|Q(comment__gt=80))
Q查询有优先级。&>|
ret=models.Book.objects.filter(Q(good__gt=80)|Q(comment__gt=80)&Q(price__gt=100))
先算后面的&,再算前面的|
ret=models.Book.objects.filter(Q(good__gt=80)|Q(comment__gt=80)&Q(price__gt=100),title=“三国演义”)
前面的Q查询作为一个整体,再和,后面的一起查询。
3.练习题
#1.查询每个作者的名称和他们的书的最高价格 #没有已知条件。就用分组(Author表的id作为分组条件。)
ret=models.Author.objects.annotate(a=Max(‘book__price‘)).values(‘name‘,‘a‘) print(ret)
#2.查询作者id大于2的作者姓名和他出版书的平均价格
ret=models.Author.objects.filter(id__gt=2).annotate(a=Avg(‘book__price‘)).values(‘name‘,‘a‘) print(ret)
#3.查询作者id大于1的作者或者年龄大于15的作者的名称以及出版的书的最高价格
ret=models.Author.objects.filter(Q(id__gt=1)|Q(age__gt=15)).annotate(a=Max(‘book__price‘)).values(‘name‘,‘a‘) print(ret)
# 4查询每个作者出版的书的最高价格的平均值 #两次统计 先分组 再聚合(把前面的结果做个统计结果)
ret=models.Author.objects.annotate(a=Max("book__price")).values(‘a‘).aggregate(Avg(‘a‘)) print(ret)
标签:对象 value aggregate 表名 http name 第一条 author 生成
原文地址:https://www.cnblogs.com/yq055783/p/12359922.html