标签:读取 追踪 lun 压缩 编写 特性 信息 分配 校验
一、服务器数据恢复环境部署介绍:今天为大家介绍的数据恢复成功案例服务器型号为:ORACLE-SUN-ZFS7320。服务器内涉及硬盘32块,服务器操作采用的是Windows操作系统。
·
服务器在正常运行的时候突然崩溃,没有断电、进水、异常操作、机房不稳定等外部因素。服务器管理员对设备进行重启后发现无法进入系统,需要对服务器内的数据进行恢复。
·
服务器管理员对所有硬盘进行扇区级镜像后将镜像文件送到数据恢复中心进行数据恢复。服务器数据恢复工程师对客户的故障服务器进行底层数据分析得到如下信息:故障服务器采用zfs文件系统;所有磁盘被分为4个组,每组8块硬盘;热备盘全部启用。
·
在服务器ZFS文件系统中,池被称为ZPOOL。ZPOOL的子设备可以有很多种类,包括块设备、文件、磁盘等等,在本案例中所采用的是其中的一种------三组RAIDZ作为子设备。
经过分析发现,三组RAIDZ内有两组分别启用热备盘个数为1和3。在启用热备盘后,第一组内仍出现一块离线盘,第二组内则出现两块。以此进行故障现场模拟:三组RAIDZ内第一二组分别出现离线盘,热备盘及时进行替换;热备盘无冗余状态下第一组出现一块离线盘,第二组出现两块离线盘,ZPOOL进入高负荷状态(每次读取数据都需要进行校验得到正确数据);第二组内出现第三块离线盘,RAIDZ崩溃、ZPOOL下线、服务器崩溃。
·
ZFS管理的存储池与常规存储不同,所有磁盘都由ZFS进行管理。常规RAID在存储数据时,只按照特定的规则组建池,不关心文件在子设备上的位置。而ZFS在数据存储时会为每次写入的数据分配适当大小的空间,并计算得到指向子设备的数据指针。这种特性使得RAIDZ缺盘时无法直接进行校验得到数据,必须将整个ZPOOL作为一个整体进行解析。
手工截取事务块数据,编写程序获取最大事务号入口: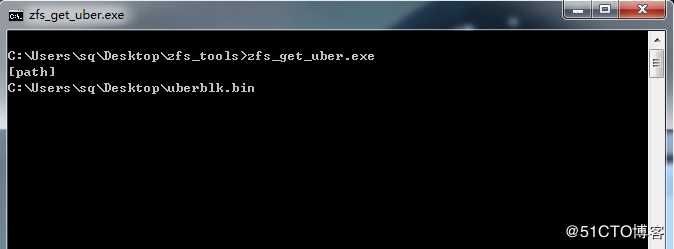
获取文件系统入口
获取到文件系统入口后,编写数据指针解析程序进行地址解析: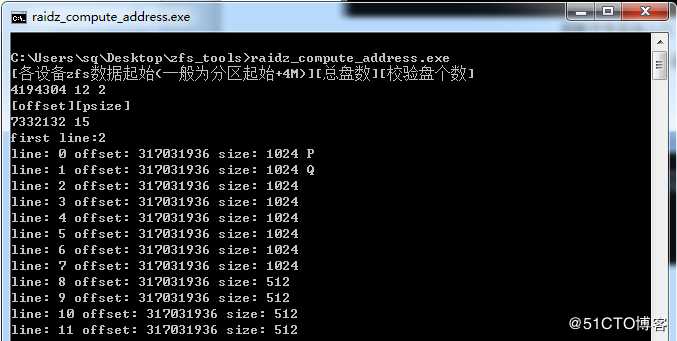
解析数据指针
获取到文件系统入口点在各磁盘分布情况后,开始手工截取并分析文件系统内部结构,入口分布所在的磁盘组无缺失盘,可直接提取信息。根据ZFS文件系统的数据存储结构顺利找到客户映射的LUN名称,进而找到其节点。
·
经过仔细分析,发现在此存储中的ZFS版本与开源版本有较大差别,无法使用公司原先开发的解析程序进行解析,所以重新编写了数据提取程序。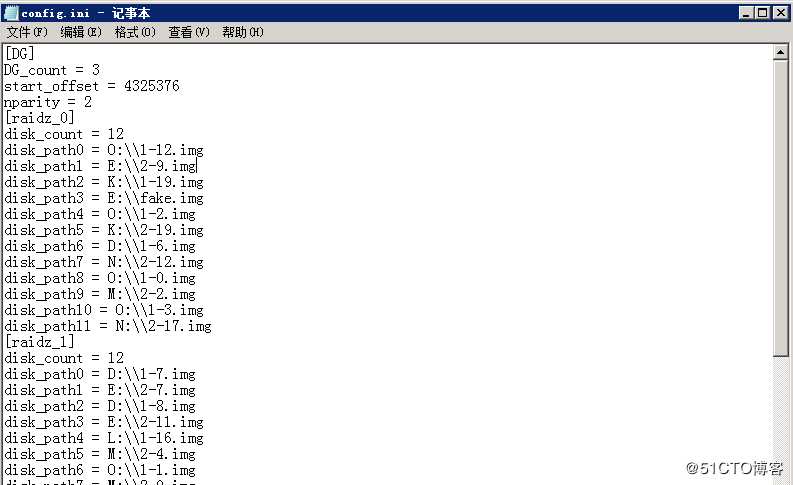
提取数据程序
由于磁盘组内缺盘个数较多,每个IO流都需要通过校验得到,提取进度极为缓慢。与客户沟通后得知,此ZVOL卷映射到XenServer作为存储设备,客户所需的文件在其中一个大小约为2T的vhd内。提取ZVOL卷头部信息,按照XenStore卷存储结构进行分析,发现2T vhd在整个卷的尾部,计算得到其起始位置后从此位置开始提取数据。
·
Vhd提取完毕后,对其内部的压缩包及图片、视频等文件进行验证,均可正常打开。
联系客户验证数据,确定文件数量与系统自动记录的文件个数一致。验证文件可用性,文件全部可正常打开,服务器数据恢复成功。
标签:读取 追踪 lun 压缩 编写 特性 信息 分配 校验
原文地址:https://blog.51cto.com/sun510/2475398