标签:通过 数据实时同步 rod 数据处理 解决 部分 默认 基本 系统
最近公司项目中做了一个两个oracle数据库数据进行数据实时同步的功能,由于数据量和环境的因素,开发人员采用了kafka做为消息中间件来转发数据,笔者就进行了kafka的学习,记录了下面的文档,望大家多多指教,共同学习进步。
一、 Kafka介绍
Kafka是由Java和Scala编写的是一个分布式、高吞吐量、分区的、多副本的、多订阅者,基于zookeeper协调的分布式发布订阅消息系统(也可以当做MQ系统)
分布式:所有的producer、broker和consumer都会有多个,均匀分布并支持通过Kafka服务器和消费机集群来分区消息
高吞吐量:Kafka 每秒可以生产约 25 万消息(50 MB),每秒处理 55 万消息(110 MB)。
分区:将日志分区可以达到以下目的:首先这使得每个日志的数量不会太大,可以在单个服务上保存。另外每个分区可以单独发布和消费,为并发操作topic提供了一种可能。分区是负载均衡失败恢复分布式数据存储的基本单元。
二、 Kafka优点
1、解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
2、冗余:许多消息队列所采用的"插入-获取-删除"范式中,在把一个消息从队列中删除之前
3、扩展性:因为消息队列解耦了你的处理过程,所以增大消息入队和处理的频率是很容易的,只要另外增加处理过程即可
4、灵活性 & 峰值处理能力:在访问量剧增的情况下,应用仍然需要继续发挥作用,但是这样的突发流量并不常见。如果为以能处理这类峰值访问为标准来投入资源随时待命无疑是巨大的浪费。使用消息队列能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃。
5、可恢复性:系统的一部分组件失效时,不会影响到整个系统。消息队列降低了进程间的耦合度,所以即使一个处理消息的进程挂掉,加入队列中的消息仍然可以在系统恢复后被处理
6、顺序保证:在大多使用场景下,数据处理的顺序都很重要。大部分消息队列本来就是排序的,并且能保证数据会按照特定的顺序来处理。(Kafka 保证一个 Partition 内的消息的有序性)
7、缓冲:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况
8、异步通信:很多时候,用户不想也不需要立即处理消息。消息队列提供了异步处理机制,允许用户把一个消息放入队列,但并不立即处理它。想向队列中放入多少消息就放多少,然后在需要的时候再去处理它们
三、 主要应用场景
日志收集系统和消息系统。
四、 名词介绍
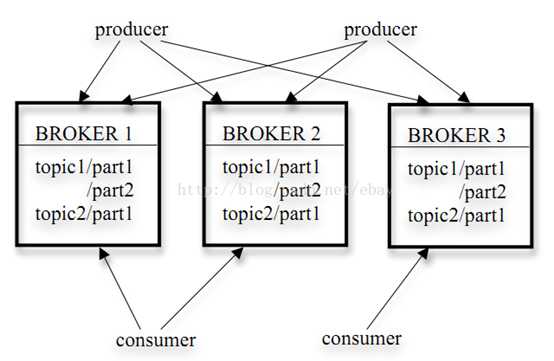
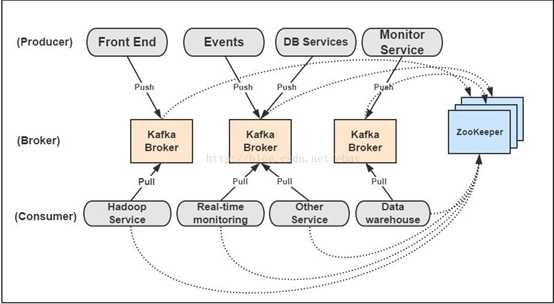
1、Broker : Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据
2、Topic : 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。
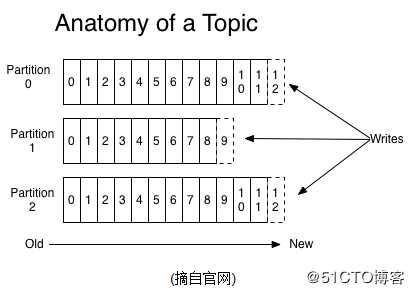
3、Partition:topic中的数据分割为一个或多个partition。每个topic至少有一个partition。每个partition中的数据使用多个segment文件存储。partition中的数据是有序的,从而保证消费是有顺序的
4、Producer:生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition
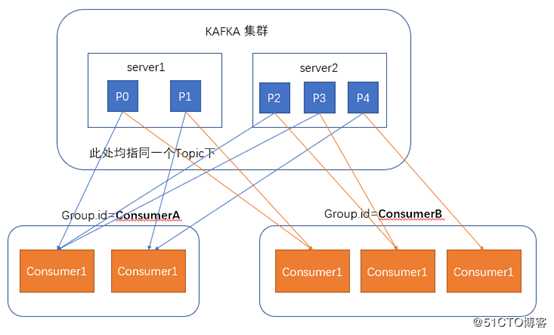
5、Consumer: 消费者可以从broker中读取数据。消费者可以消费多个topic中的数据
6、Consumer group:每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)
7、Leader: 每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
8、Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。如果Leader失效,则从Follower中选举出一个新的Leader。当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower
五、 关系图
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
标签:通过 数据实时同步 rod 数据处理 解决 部分 默认 基本 系统
原文地址:https://www.cnblogs.com/huangfeifei/p/12450875.html