标签:bsp trie cpu height ror git code loss proc
https://discuss.pytorch.org/t/how-is-the-mseloss-implemented/12972
torch在实现时非常简单,就是 ((input-target)**2).mean(),平方然后均值这个样子。
https://blog.csdn.net/xiaowei_cqu/article/details/9004193(待看)
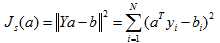
天啦,一直都没有,是我记错了。。那个根号应该是针对L2距离的,就是欧几里得距离,而不是MSE。跪。
但是这个均值,我还是有问题,为什么不是针对样本,而是针对每个值呢?我明白了,你最后获得这个不也是得需要/len(x)的嘛,也就是针对每个样本的损失了~~~.mean()算是针对每个特征的损失了。
https://www.cnblogs.com/hellojamest/p/11769467.html (待看)
RuntimeError: CUDA out of memory. Tried to allocate 1.28 GiB (GPU 0; 10.76 GiB total capacity;
8.17 GiB already allocated; 825.56 MiB free; 1.02 GiB cached)
https://github.com/pytorch/pytorch/issues/958,从这个解答中可以看出,有一个例子是给了好多全连接层,然后溢出了。这个链接的讲解是great的!!!
那我有个疑问,如果GPU溢出的话, 能不能放到cpu上来训练,但是这样的话,模型还有什么意义。。。
https://zhuanlan.zhihu.com/p/61892329 这个里面的让我很震惊啊,真的是这个意思啊,原来溢出是和数据集大小和模型大小是没关系的吗,握哭了,原来是这样。

以后遇到溢出的话,就直接只考虑把batch_size足够减小就好了。。。
https://zhuanlan.zhihu.com/p/36369878
http://theorangeduck.com/page/neural-network-not-working#batchsize
https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html

均值和标准差:
>>> scaler.mean_ array([0.5, 0.5]) >>> scaler.var_ array([0.25, 0.25])
总的过程就是x-miu/std,是标准差,不是方差哦。
标签:bsp trie cpu height ror git code loss proc
原文地址:https://www.cnblogs.com/BlueBlueSea/p/12483881.html