标签:rdo 访问 ora 方式 ref 概述 monitor 不同 content
ceph 本质上 就是一个 RADOS (
Reliable Automatic Distributed Object Storage) 可靠的,自动的分布式 对象 存储。
Ceph 内部都是自动的实现 容错机制,基于 CRUSH 算法。当有一块磁盘坏了,会自动的进行 容错机制。
ceph 的特性
文件存储、块存储、对象存储)视图 的一个概念,由cluster map管理整个集群的状态)其实感觉 Ceph 理念是 使用廉价的设备 部署一套 比较完善的存储集群
Ceph 底层是一个 RADOS,在此上层,提供一个 Librados 的库,用于 其他组件想使用下层的 rados,则需要调用 Librados 实现。
而对应的三种类型的存储,实现调用 Librados 的组件也不相同:
CephFS 组件,通过调用 Librados 实现访问 RADOSlibrbd 组件,通过调用 Librados 实现访问 RADOSradosgw组件,通过调用 Librados 实现访问 RADOS如下图:
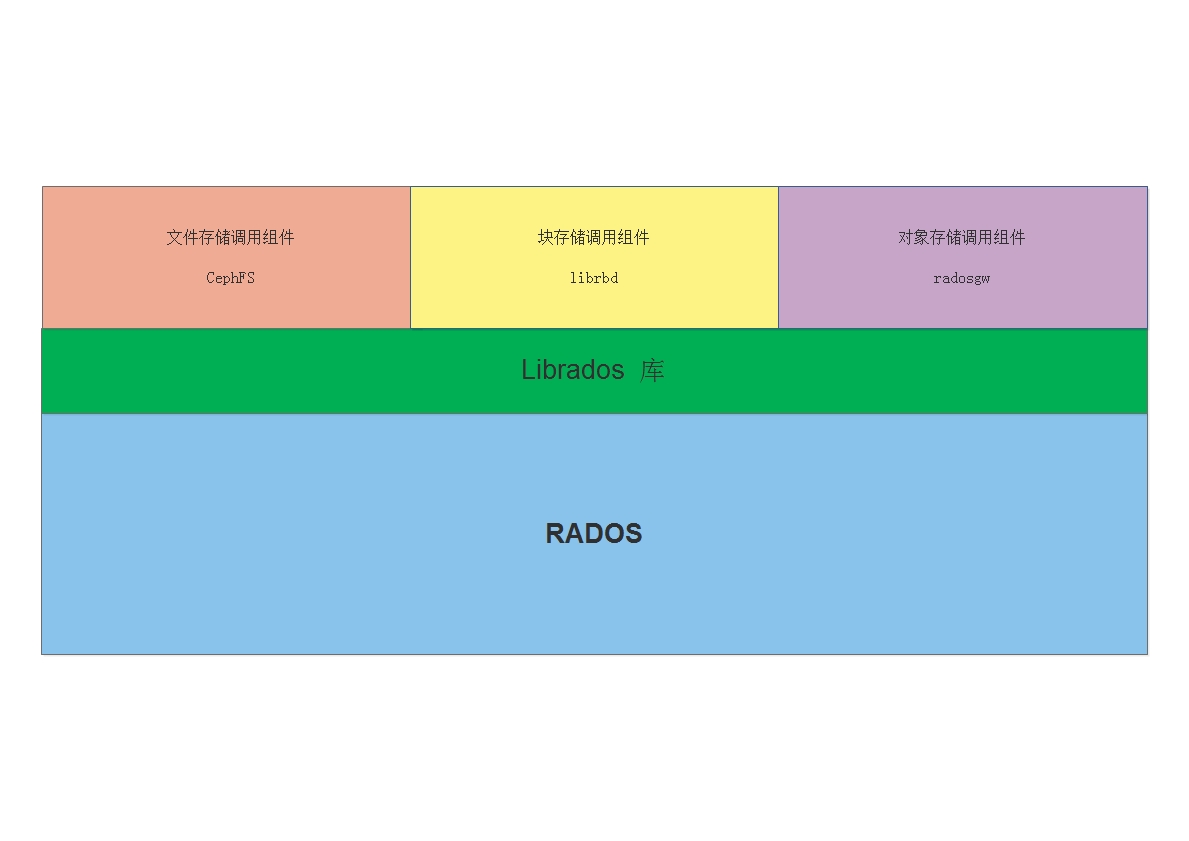
实际场景中,如 OpenStack 私有云环境中,使用 Ceph (librbd) 来提供整个集群的块存储。
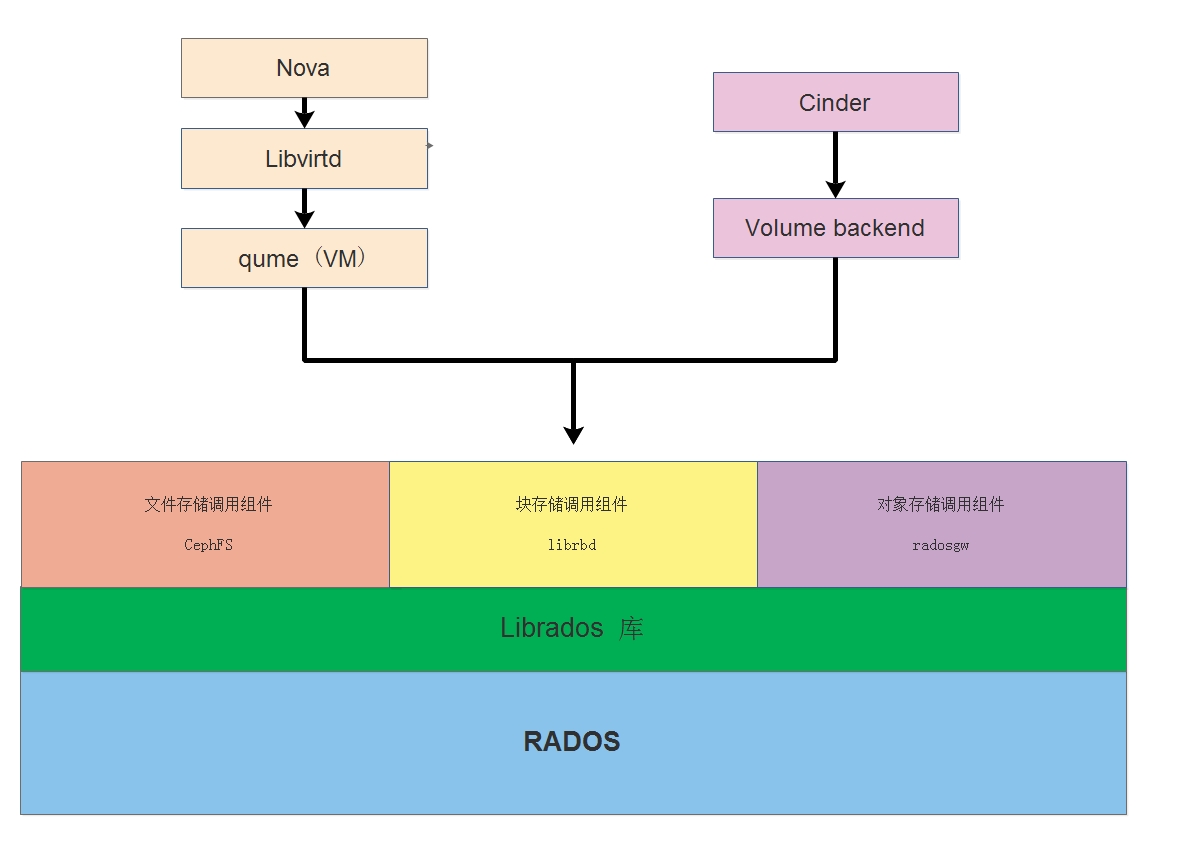
这里有一个很重要的点,要明白 在 OpenStack 私有云环境中 是谁来使用这个块存储? 谁创建的?
本质上,是由 Nova 通过 libirtd 调用 qemu(硬件仿真,实现对CPU和内存很好的隔离) 驱动来创建一台 云主机(vm),
之后 Cinder 通过 volume backend 调用 ceph集群的 librbd 驱动实现在 RADOS 中划分一个空间出来,就完成了磁盘创建,
然后把创建的磁盘挂载到 云主机(vm) 中,此时在vm中对该磁盘存储数据,都是通过 qemu 向ceph集群的 librbd 发送一系列的请求。
那么可以大概行程下面的流程:
首先创建磁盘: cinder --> volumebackend --> librbd --> librados --> RADOS
创建云主机实现挂在动作流程: nova --> libvirtd --> qemu(vm) --> librbd --> librados --> RADOS
这里大概讲述下ceph 的存储过程以及大致原理,细致的原理后续文章更新
OSD 守护进程( Ceph OSD )的功能是存储数据,处理数据的
复制、恢复、回填、再均衡,并通过检查其他OSD 守护进程的心跳来向 Ceph Monitors 提供一些监控信息。
当 Ceph 存储集群设定为有3个副本时,至少需要3个 OSD 守护进程,集群才能达到 active+clean 状态( Ceph 默认有3个副本,可以调整副本数)。
其实 OSD daemon 本质上就是一个管理进程,需要注意,一个OSD daemon对应一块磁盘,也就是说一个OSD 守护进程只负责管理一块磁盘,这里不建议使用建立 Raid 后,再使用 OSD daemon 来管理,功能重叠;
建议每个OSD daemon 直接管理裸盘,
PG (
Placement Group) 是组的概念,是一个acting set有序列表,官方管它叫归置组,用于管理OSD daemon,当 Ceph 存储集群设定为有3个副本时,那么每个 PG组中,会管理三个OSD daemon。
这里假设的副本数意思表示,一份数据在 Ceph 集群中,会保存三份,这样在一个PG 中,同时坏掉两块磁盘,数据也不会丢失。
在PG 组中,是一个有序列表,队列中的第一个位置,是组长,用于负责本组内的 读写工作,而剩下的两个 OSD 负责备份数据。
注意: PG 跟 OSD 的关系是多对多的关系,如下图:
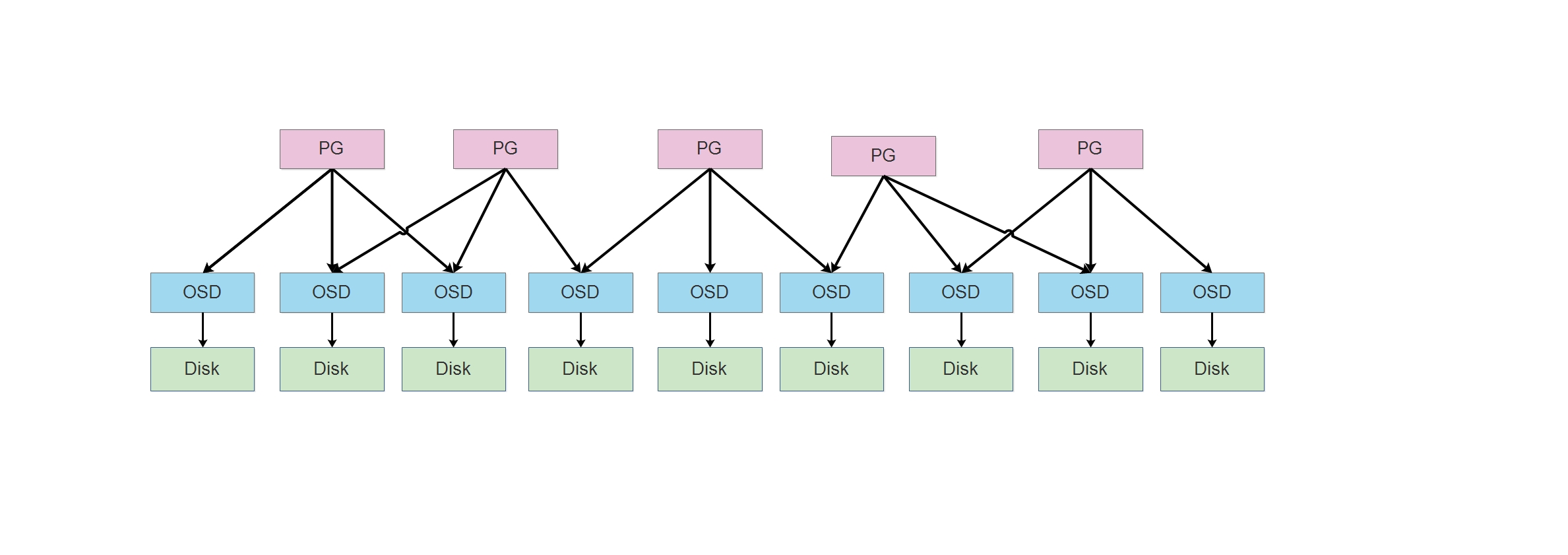
一个PG可以对应多个 OSD,同样一个OSD也可以对应多个PG。
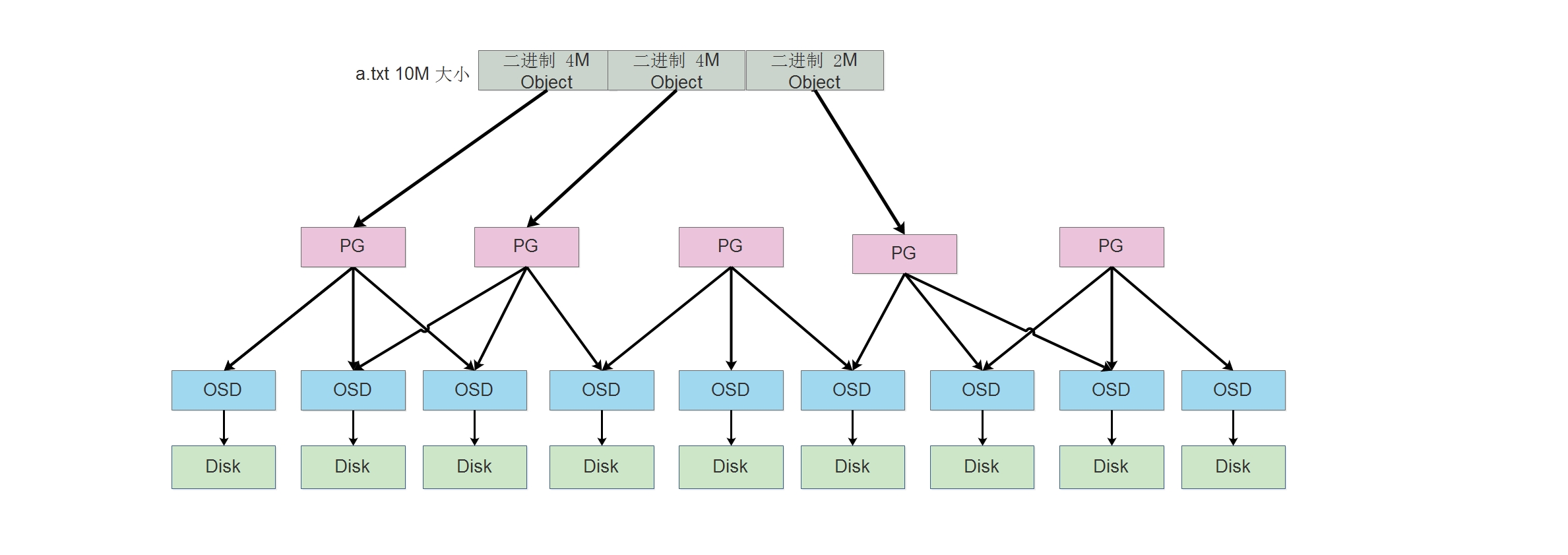
Ceph 存储的数据对象,这个
Object其实就是数据源中的 Object,只是经过Librbd这样组件进行处理后,给每个Object增加了一个Object_id的标识符。
在如 Ceph 块存储的 Librbd 中,如果有数据要写入时,该数据会被切割,可配置,最小为
4M的大小。如 要写入一个10M大小的a.txt文件,则会被切割为 如 X、Y、Z 三个Object,分别是 4M 4M 2M 的Object,然后会被写入到 PG 中,由 PG中的 组长OSD 进行写入数据。至于 X、Y、Z 这三个Object会被写入到哪一个PG中,则是由 CRUSH 决定,有可能会被写入到 同一个 PG 中,也有可能写入到不同的三个 PG 中。
小总结: 由上面的写入方式可以得出
下面两个图中,分别表示数据的写入。
标签:rdo 访问 ora 方式 ref 概述 monitor 不同 content
原文地址:https://www.cnblogs.com/winstom/p/12493348.html