标签:修改编码 import 返回 format print 运行 列表 time request
import requests from bs4 import BeautifulSoup import bs4 ulist=[]#定义一个空列表 def getHTMLText(url): try: headers = { ‘User-Agent‘: ‘5498‘} r = requests.get(url, timeout=30, headers=headers)#输入获取的url信息,输出是url的内容 r.raise_for_status() #用raise_for_status产生异常信息 r.encoding = r.apparent_encoding # 修改编码 return r.text #将网页的内容返回给程序的其他部分 except: return "" #出现错误,则返回空字符串 def fillList(ulist, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find(‘tbody‘).children: #for语句查找tbody标签,并且将孩子children遍历 #isinstance对函数进行判断,检测tr标签的类型,如果tr不是bs4定义的Tag类型, #将过滤掉(并且为了代码可以运行需要引入一个新的类型bs4) if isinstance(tr, bs4.element.Tag): tds = tr(‘td‘) #将所有的td 标签存为一个列表类型 ulist.append([tds[1].string, tds[2].string]) def printList(ulist, num): #将ulist信息打印出来 print("{:^6}\t{:^10}".format(" 标题", " 点击量")) #下面实现对其他信息的打印 for i in range(num): u = ulist[i] print("{:^6}\t{:^10}".format(u[0], u[1])) def main(): # 新闻信息放到列表中 uinfo = [] url = "https://tophub.today/n/G2me35rvwj" # 将url转换成html html = getHTMLText(url) fillList(uinfo, html) printList(uinfo, 10) main()
main()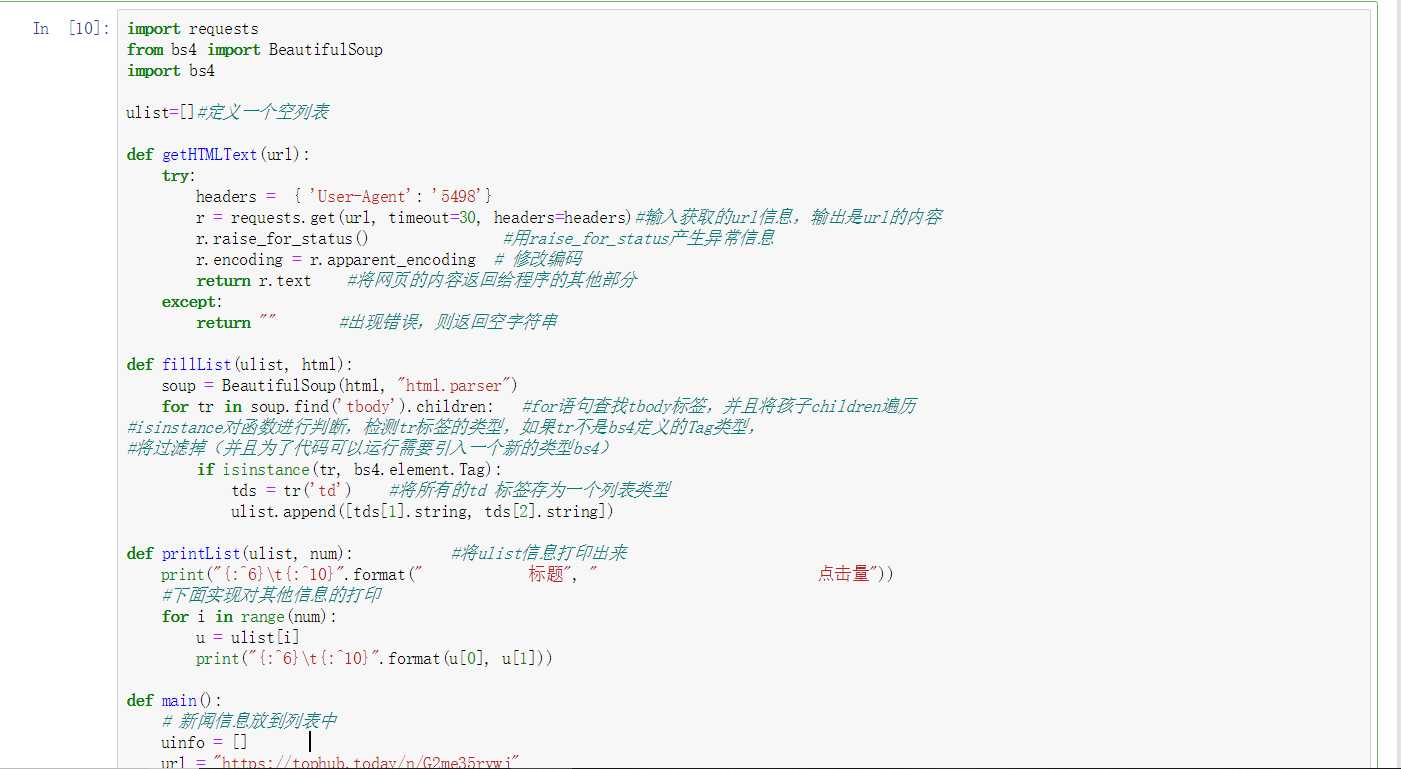
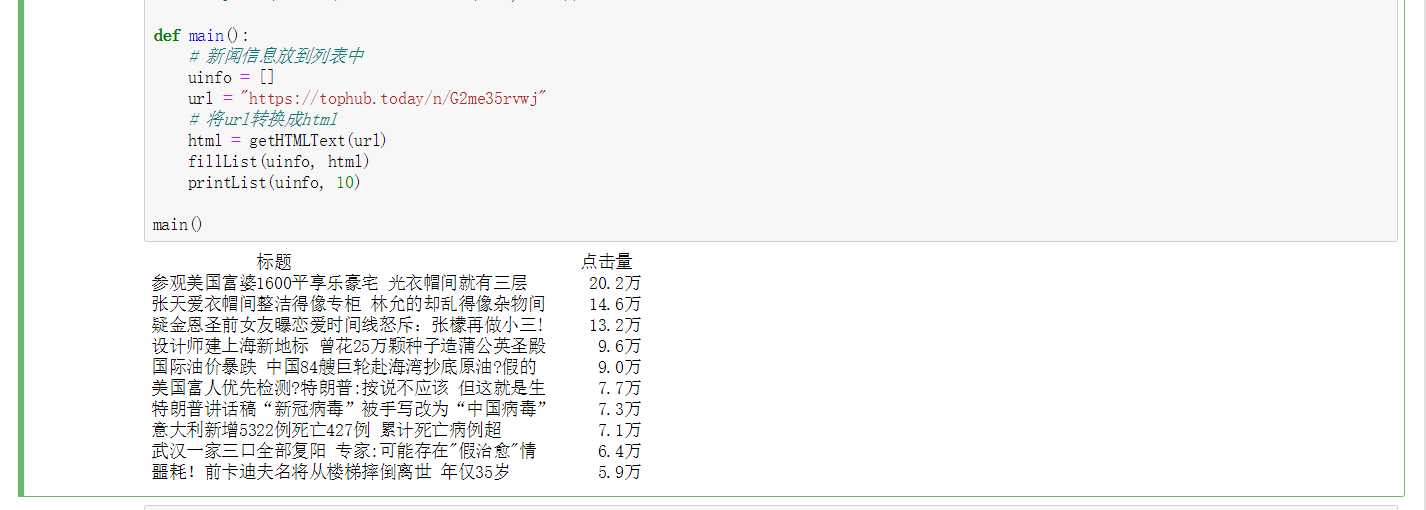

标签:修改编码 import 返回 format print 运行 列表 time request
原文地址:https://www.cnblogs.com/L787979852/p/12539115.html