标签:系统 python 特性 release 次数 元素 isa 时间段 rac
一、介绍
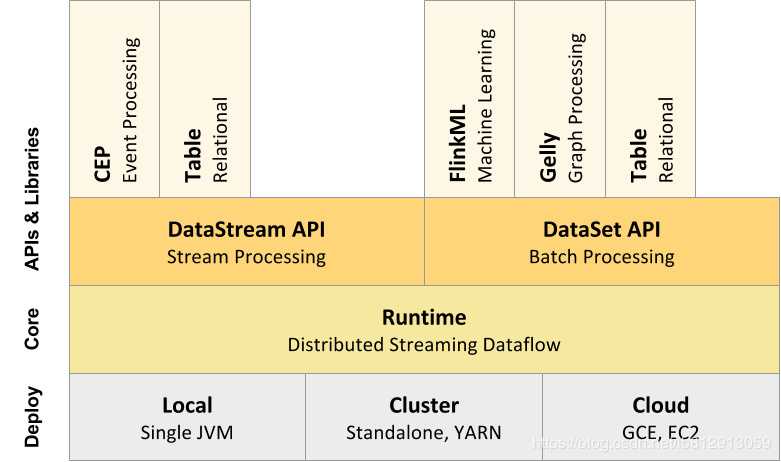
API支持
Libraries支持
整合支持
该层主要涉及了Flink的部署模式,Flink支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone部署模式与Spark类似,这里,我们看一下Flink on YARN的部署模式,如下图所示:
了解YARN的话,对上图的原理非常熟悉,实际Flink也实现了满足在YARN集群上运行的各个组件:Flink YARN Client负责与YARN RM通信协商资源请求,Flink JobManager和Flink TaskManager分别申请到Container去运行各自的进程。通过上图可以看到,YARN AM与Flink JobManager在同一个Container中,这样AM可以知道Flink JobManager的地址,从而AM可以申请Container去启动Flink TaskManager。待Flink成功运行在YARN集群上,Flink YARN Client就可以提交Flink Job到Flink JobManager,并进行后续的映射、调度和计算处理。
Runtime层提供了支持Flink计算的全部核心实现,比如:支持分布式Stream处理、JobGraph到ExecutionGraph的映射、调度等等,为上层API层提供基础服务。
API层主要实现了面向无界Stream的流处理和面向Batch的批处理API,其中面向流处理对应DataStream API,面向批处理对应DataSet API。
该层也可以称为Flink应用框架层,根据API层的划分,在API层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于SQL-like的操作(基于Table的关系操作);面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
DataStream和DataSet
DataStream 表示无解数据集,用于流处理应用程序,DataSet 表示有界数据集,用于批处理程序。
它们都是不可变的数据集,不可以像操纵集合那样增加或删除DataStream和DataSet中的元素,也不可以通过诸如下标等方式访问某个元素。
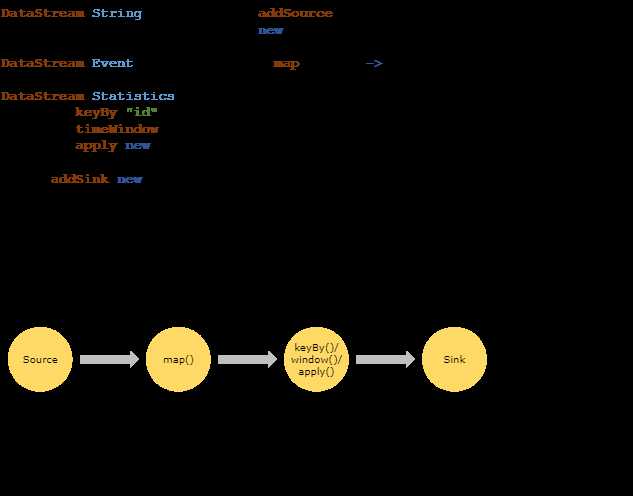
Flink编写应用程序的5个步骤:
1.获取运行时
流处理
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
批处理
val environment: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
上述方法根据当前环境自动选择本地或集群运行时环境。
2.添加外部数据源
通过source创建DataStream和DataSet对象
3.定义算子转换函数
通过转换操作产生新的DataStream和DataSet对象
4.定义Sink
Flink 预定义 Sinks
基于文件的:如 writeAsText() 、 writeAsCsv() 、 writeUsingOutputFormat 、 FileOutputFormat 。
写到socket: writeToSocket 。
用于显示的: print 、 printToErr 。
自定义Sink: addSink 。
对于 write* 来说,主要用于测试程序,Flink 没有实现这些方法的检查点机制,也就没有 exactly-once 支持。所以,为了保证 exactly-once ,需要使用 flink-connector-filesystem ,同时,自定义的 addSink 也可以支持。
Connectors
connectors 用于给接入第三方数据提供接口,现在支持的connectors 包括:
Apache Kafka
Apache Cassandra
Elasticsearch
Hadoop FileSystem
RabbitMQ
Apache NiFi
另外,通过 Apache Bahir ,可以支持Apache ActiveMQ、Apache Flume、 Redis 、Akka之类的Sink。
5.启动程序
调用运行时的execute()方法
env.execute("word count")
实现统计socket当中的单词数量
1.创建maven工程
新建flink_warehouse项目,jdk1.8,去掉src目录
项目下新建modole,也选择jdk1.8
src下新建scala目录,设为sources root
pom文件
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>flink_warehouse</artifactId> <groupId>com.aidata.flink</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>flink_study</artifactId> <dependencies> <!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-scala --> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-streaming-scala_2.11</artifactId> <version>1.8.1</version> </dependency> <dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-scala_2.11</artifactId> <version>1.8.1</version> </dependency> </dependencies> <build> <plugins> <!-- 限制jdk版本插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.0</version> <configuration> <source>1.8</source> <target>1.8</target> <encoding>UTF-8</encoding> </configuration> </plugin> <!-- 编译scala需要用到的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> </plugin> <!-- 项目打包用到的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>3.1.0</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> <archive> <manifest> <mainClass></mainClass> </manifest> </archive> </configuration> <executions> <execution> <id>make-assembly</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
2.开发flink代码
统计socket当中的单词数量
开发flink代码实现接受socket单词数据,然后对数据进行统计
package com.aidata.flinkstream import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.api.windowing.time.Time object StreamSocket { def main(args: Array[String]): Unit = { //获取程序入口类 val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //从socket当中获取数据 val result: DataStream[String] = environment.socketTextStream("node01",9000) //导入隐式转换的包,否则时间不能使用 import org.apache.flink.api.scala._ //将数据进行切割,封装到样例类当中,然后进行统计 val resultValue: DataStream[(String, Int)] = result .flatMap(x => x.split(" ")) .map(x => (x,1)) .keyBy(0) // .timeWindow(Time.seconds(1),Time.milliseconds(1)) 按照每秒钟时间窗口,以及每秒钟滑动间隔来进行数据统计 .sum(1) //打印最终输出结果 resultValue.print().setParallelism(1) //启动服务 environment.execute() } }
3.打包上传到服务器运行
将我们的程序打包,然后上传到服务器进行运行,将我们打包好的程序上传到node01服务器,然后体验在各种模式下进行运行我们的程序
安装nc命令
# Manually downloads the working package from the Official Repository wget http://vault.centos.org/6.6/os/x86_64/Packages/nc-1.84-22.el6.x86_64.rpm # Installs the package rpm -iUv nc-1.84-22.el6.x86_64.rpm
向端口发送信息
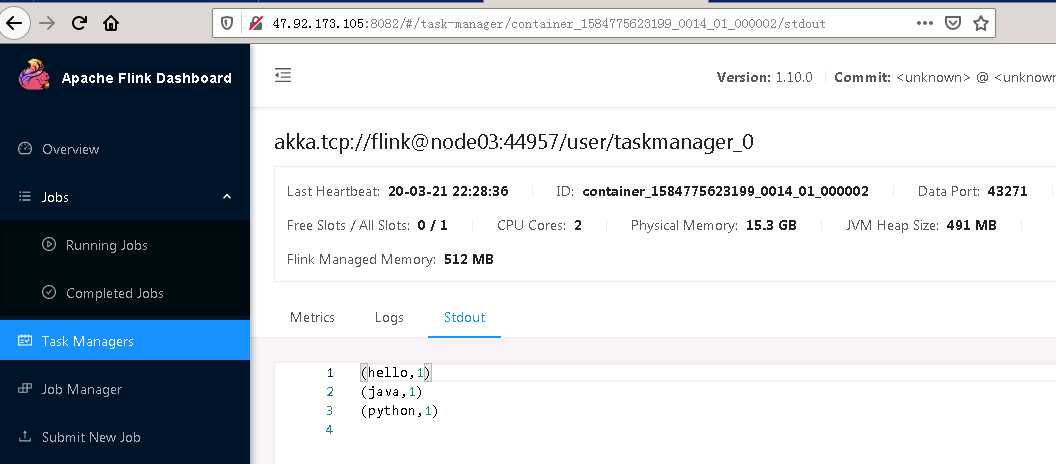
[root@node01 ~]# nc -lk 9002 hello java python
在集群提交作业
[root@node01 flink-1.10.0]# bin/flink run -m yarn-cluster --class com.aidata.flink stream.StreamSocket /bigdata/flink_study-1.0-SNAPSHOT.jar 2020-03-21 22:09:10,759 WARN org.apache.hadoop.conf.Configuration - /etc/hadoop/conf/core-site.xml:an attempt to override final parameter: hadoop.ssl.require.client.cert; Ignoring. 2020-03-21 22:09:10,759 WARN org.apache.hadoop.conf.Configuration - /etc/hadoop/conf/core-site.xml:an attempt to override final parameter: hadoop.ssl.keystores.factory.class; Ignoring. 2020-03-21 22:09:10,760 WARN org.apache.hadoop.conf.Configuration - /etc/hadoop/conf/core-site.xml:an attempt to override final parameter: hadoop.ssl.server.conf; Ignoring. 2020-03-21 22:09:10,760 WARN org.apache.hadoop.conf.Configuration - /etc/hadoop/conf/core-site.xml:an attempt to override final parameter: hadoop.ssl.client.conf; Ignoring. 2020-03-21 22:09:10,813 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory (‘/bigdata/flink-1.10.0/conf‘) already con tains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file. 2020-03-21 22:09:10,813 WARN org.apache.flink.yarn.cli.FlinkYarnSessionCli - The configuration directory (‘/bigdata/flink-1.10.0/conf‘) already con tains a LOG4J config file.If you want to use logback, then please delete or rename the log configuration file. flink hahahhahahhaorg.apache.flink.streaming.api.scala.DataStream@33aa93c 2020-03-21 22:09:13,015 INFO org.apache.hadoop.yarn.client.RMProxy - Connecting to ResourceManager at node03/172.26.106.82:8032 2020-03-21 22:09:13,197 INFO org.apache.flink.yarn.YarnClusterDescriptor - No path for the flink jar passed. Using the location of class org.apac he.flink.yarn.YarnClusterDescriptor to locate the jar 2020-03-21 22:09:13,407 INFO org.apache.flink.yarn.YarnClusterDescriptor - Cluster specification: ClusterSpecification{masterMemoryMB=1024, taskM anagerMemoryMB=1568, slotsPerTaskManager=1} 2020-03-21 22:09:15,706 INFO org.apache.flink.yarn.YarnClusterDescriptor - Submitting application master application_1584775623199_0014 2020-03-21 22:09:15,726 INFO org.apache.hadoop.yarn.client.api.impl.YarnClientImp l - Submitted application application_1584775623199_0014 2020-03-21 22:09:15,726 INFO org.apache.flink.yarn.YarnClusterDescriptor - Waiting for the cluster to be allocated 2020-03-21 22:09:15,728 INFO org.apache.flink.yarn.YarnClusterDescriptor - Deploying cluster, current state ACCEPTED 2020-03-21 22:09:24,093 INFO org.apache.flink.yarn.YarnClusterDescriptor - YARN application has been deployed successfully. 2020-03-21 22:09:24,094 INFO org.apache.flink.yarn.YarnClusterDescriptor - Found Web Interface node01:8082 of application ‘application_1584775623199_0014‘. Job has been submitted with JobID f414e51483a07806d6cde348e6dbaf6f
查看输出
为了方便开发调试,Flink支持通过shell命令行的方式开发,类似于Spark的shell命令行对代码的调试是一样的,可以方便的对我们的代码执行结果进行跟踪调试,查验代码的问题所在Flink shell方式支持流处理和批处理。当启动shell命令行之后,两个不同的Execution Environments会被自动创建。使用senv(Stream)和benv(Batch)分别去处理流处理和批处理程序。(类似于spark-shell中sc变量)
bin/start-scala-shell.sh local
注意:
Flink built on Scala 2.12 version Doesn‘t support Flink Scala shell yet. So you should use the Flink binary built based on Scala 2.11 if you want to use Flink Scala shell. A message from Chesnay Schepler, Committer of Flink project:
This is intended. Increasing the Scala version basically broke the scala-shell and we haven‘t had the time to fix it. It is thus only available with Scala 2.11. I agree that the error message could be better though.
Flink API 可分为两类:
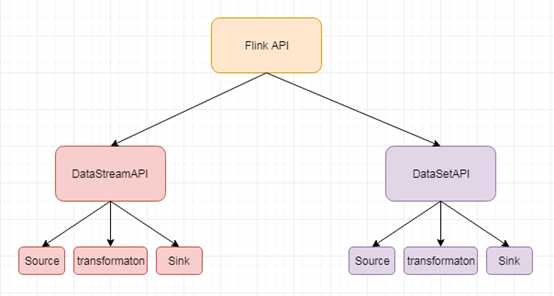
基于文件
// 基于文件的source(File-based-source)
//0.创建运行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
// 1.读取本地文件
val text1 = env.readTextFile("data2.csv")
text1.print()
// 2.读取hdfs文件
val text2 = env.readTextFile("hdfs://hadoop01:9000/input/flink/README.txt")
text2.print()
env.execute()
基于网络套接字
val source = env.socketTextStream("IP", PORT)
基于kafka
//1指定kafka数据流的相关信息
val zkCluster = "hadoop01,hadoop02,hadoop03:2181"
val kafkaCluster = "hadoop01:9092,hadoop02:9092,hadoop03:9092"
val kafkaTopicName = "test"
//2.创建流处理环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//3.创建kafka数据流
val properties = new Properties()
properties.setProperty("bootstrap.servers", kafkaCluster)
properties.setProperty("zookeeper.connect", zkCluster)
properties.setProperty("group.id", kafkaTopicName)
val kafka09 = new FlinkKafkaConsumer09[String](kafkaTopicName,
new SimpleStringSchema(), properties)
//4.添加数据源addSource(kafka09)
val text = env.addSource(kafka09).setParallelism(4)
由应用创建DataStream或DataSet,常用于测试环境
//0.用element创建DataStream(fromElements)
val ds0: DataStream[String] = senv.fromElements("spark", "flink")
ds0.print()
//1.用Tuple创建DataStream(fromElements)
val ds1: DataStream[(Int, String)] = senv.fromElements((1, "spark"), (2, "flink"))
ds1.print()
//2.用Array创建DataStream
val ds2: DataStream[String] = senv.fromCollection(Array("spark", "flink"))
ds2.print()
//3.用ArrayBuffer创建DataStream
val ds3: DataStream[String] = senv.fromCollection(ArrayBuffer("spark", "flink"))
ds3.print()
//4.用List创建DataStream
val ds4: DataStream[String] = senv.fromCollection(List("spark", "flink"))
ds4.print()
//5.用List创建DataStream
val ds5: DataStream[String] = senv.fromCollection(ListBuffer("spark", "flink"))
ds5.print()
//6.用Vector创建DataStream
val ds6: DataStream[String] = senv.fromCollection(Vector("spark", "flink"))
ds6.print()
//7.用Queue创建DataStream
val ds7: DataStream[String] = senv.fromCollection(Queue("spark", "flink"))
ds7.print()
//8.用Stack创建DataStream
val ds8: DataStream[String] = senv.fromCollection(Stack("spark", "flink"))
ds8.print()
//9.用Stream创建DataStream(Stream相当于lazy List,避免在中间过程中生成不必要的集合)
val ds9: DataStream[String] = senv.fromCollection(Stream("spark", "flink"))
ds9.print()
//10.用Seq创建DataStream
val ds10: DataStream[String] = senv.fromCollection(Seq("spark", "flink"))
ds10.print()
//11.用Set创建DataStream(不支持)
//val ds11: DataStream[String] = senv.fromCollection(Set("spark", "flink"))
//ds11.print()
//12.用Iterable创建DataStream(不支持)
//val ds12: DataStream[String] = senv.fromCollection(Iterable("spark", "flink"))
//ds12.print()
//13.用ArraySeq创建DataStream
val ds13: DataStream[String] = senv.fromCollection(mutable.ArraySeq("spark", "flink"))
ds13.print()
//14.用ArrayStack创建DataStream
val ds14: DataStream[String] = senv.fromCollection(mutable.ArrayStack("spark", "flink"))
ds14.print()
//15.用Map创建DataStream(不支持)
//val ds15: DataStream[(Int, String)] = senv.fromCollection(Map(1 -> "spark", 2 -> "flink"))
//ds15.print()
//16.用Range创建DataStream
val ds16: DataStream[Int] = senv.fromCollection(Range(1, 9))
ds16.print()
//17.用fromElements创建DataStream
val ds17: DataStream[Long] = senv.generateSequence(1, 9)
ds17.print()
map可以理解为映射,对每个元素进行一定的变换后,映射为另一个元素。
举例:
package operators;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
//这个例子是监听9000 socket端口,对于发送来的数据,以\n为分隔符分割后进行处理,
//将分割后的每个元素,添加上一个字符串后,打印出来。
public class MapDemo {
private static int index = 1;
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.map操作。
DataStream<String> result = textStream.map(s -> (index++) + ".您输入的是:" + s);
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
flatmap可以理解为将元素摊平,每个元素可以变为0个、1个、或者多个元素。
举例:
package operators;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
//这个例子是用Flink监听9000端口,将接受的字符串用\n分割为一个个的元素
//然后将每个元素拆为一个个的字符,并打印出来
public class FlatMapDemo {
private static int index1 = 1;
private static int index2 = 1;
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.flatMap操作,对每一行字符串进行分割
DataStream<String> result = textStream.flatMap((String s, Collector<String> collector) -> {
for (String str : s.split("")) {
collector.collect(str);
}
})
//这个地方要注意,在flatMap这种参数里有泛型算子中。
//如果用lambda表达式,必须将参数的类型显式地定义出来。
//并且要有returns,指定返回的类型
//详情可以参考Flink官方文档:https://ci.apache.org/projects/flink/flink-docs-release-1.6/dev/java_lambdas.html
.returns(Types.STRING);
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
filter是进行筛选。
举例:
package operators;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FilterDemo {
private static int index = 1;
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.filter操作,筛选非空行。
DataStream<String> result = textStream.filter(line->!line.trim().equals(""));
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
逻辑上将Stream根据指定的Key进行分区,是根据key的散列值进行分区的。
举例:
package operators;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.concurrent.TimeUnit;
//这个例子是每行输入一个单词,以单词为key进行计数
//每10秒统计一次每个单词的个数
public class KeyByDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.
DataStream<Tuple2<String, Integer>> result = textStream
//map是将每一行单词变为一个tuple2
.map(line -> Tuple2.of(line.trim(), 1))
//如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。
.returns(Types.TUPLE(Types.STRING, Types.INT))
//keyBy进行分区,按照第一列,也就是按照单词进行分区
.keyBy(0)
//指定窗口,每10秒个计算一次
.timeWindow(Time.of(10, TimeUnit.SECONDS))
//计算个数,计算第1列
.sum(1);
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
reduce是归并操作,它可以将KeyedStream 转变为 DataStream。
package operators;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.concurrent.TimeUnit;
//这个例子是对流进行分组,分组后进归并操作。
//是wordcount的另外一种实现方法
public class ReduceDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.
DataStream<Tuple2<String, Integer>> result = textStream
//map是将每一行单词变为一个tuple2
.map(line -> Tuple2.of(line.trim(), 1))
//如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。
.returns(Types.TUPLE(Types.STRING, Types.INT))
//keyBy进行分区,按照第一列,也就是按照单词进行分区
.keyBy(0)
//指定窗口,每10秒个计算一次
.timeWindow(Time.of(10, TimeUnit.SECONDS))
//对每一组内的元素进行归并操作,即第一个和第二个归并,结果再与第三个归并...
.reduce((Tuple2<String, Integer> t1, Tuple2<String, Integer> t2) -> new Tuple2(t1.f0, t1.f1 + t2.f1));
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
给定一个初始值,将各个元素逐个归并计算。它将KeyedStream转变为DataStream。
举例:
package operators;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import java.util.concurrent.TimeUnit;
public class FoldDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.
DataStream<String> result = textStream
//map是将每一行单词变为一个tuple2
.map(line -> Tuple2.of(line.trim(), 1))
//如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。
.returns(Types.TUPLE(Types.STRING, Types.INT))
//keyBy进行分区,按照第一列,也就是按照单词进行分区
.keyBy(0)
//指定窗口,每10秒个计算一次
.timeWindow(Time.of(10, TimeUnit.SECONDS))
//指定一个开始的值,对每一组内的元素进行归并操作,即第一个和第二个归并,结果再与第三个归并...
.fold("结果:",(String current, Tuple2<String, Integer> t2) -> current+t2.f0+",");
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
union可以将多个流合并到一个流中,以便对合并的流进行统一处理。是对多个流的水平拼接。
参与合并的流必须是同一种类型。
举例:
package operators;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
//这个例子是将三个socket端口发送来的数据合并到一个流中
//可以对这三个流发送来的数据,集中处理。
public class UnionDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n");
DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n");
DataStream<String> textStream9002 = env.socketTextStream("localhost", 9002, "\n");
DataStream<String> mapStream9000=textStream9000.map(s->"来自9000端口:"+s);
DataStream<String> mapStream9001=textStream9001.map(s->"来自9001端口:"+s);
DataStream<String> mapStream9002=textStream9002.map(s->"来自9002端口:"+s);
//3.union用来合并两个或者多个流的数据,统一到一个流中
DataStream<String> result = mapStream9000.union(mapStream9001,mapStream9002);
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
根据指定的Key将两个流进行关联。
举例:
package operators;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class WindowJoinDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n");
DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n");
//将输入处理一下,变为tuple2
DataStream<Tuple2<String,String>> mapStream9000=textStream9000
.map(new MapFunction<String, Tuple2<String,String>>() {
@Override
public Tuple2<String, String> map(String s) throws Exception {
return Tuple2.of(s,"来自9000端口:"+s);
}
});
DataStream<Tuple2<String,String>> mapStream9001=textStream9001
.map(new MapFunction<String, Tuple2<String,String>>() {
@Override
public Tuple2<String, String> map(String s) throws Exception {
return Tuple2.of(s,"来自9001端口:"+s);
}
});
//3.两个流进行join操作,是inner join,关联上的才能保留下来
DataStream<String> result = mapStream9000.join(mapStream9001)
//关联条件,以第0列关联(两个source输入的字符串)
.where(t1->t1.getField(0)).equalTo(t2->t2.getField(0))
//以处理时间,每10秒一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
//关联后输出
.apply((t1,t2)->t1.getField(1)+"|"+t2.getField(1))
;
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
关联两个流,关联不上的也保留下来。
举例:
package operators;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class CoGroupDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n");
DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n");
//将输入处理一下,变为tuple2
DataStream<Tuple2<String, String>> mapStream9000 = textStream9000
.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String s) throws Exception {
return Tuple2.of(s, "来自9000端口:" + s);
}
});
DataStream<Tuple2<String, String>> mapStream9001 = textStream9001
.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String s) throws Exception {
return Tuple2.of(s, "来自9001端口:" + s);
}
});
//3.两个流进行coGroup操作,没有关联上的也保留下来,功能更强大
DataStream<String> result = mapStream9000.coGroup(mapStream9001)
//关联条件,以第0列关联(两个source输入的字符串)
.where(t1 -> t1.getField(0)).equalTo(t2 -> t2.getField(0))
//以处理时间,每10秒一个滚动窗口
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
//关联后输出
.apply(new CoGroupFunction<Tuple2<String, String>, Tuple2<String, String>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, String>> iterable, Iterable<Tuple2<String, String>> iterable1, Collector<String> collector) throws Exception {
StringBuffer stringBuffer = new StringBuffer();
stringBuffer.append("来自9000的stream:");
for (Tuple2<String, String> item : iterable) {
stringBuffer.append(item.f1 + ",");
}
stringBuffer.append("来自9001的stream:");
for (Tuple2<String, String> item : iterable1) {
stringBuffer.append(item.f1 + ",");
}
collector.collect(stringBuffer.toString());
}
});
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
}
参考:https://www.jianshu.com/p/5b0574d466f8
将两个流纵向地连接起来。DataStream的connect操作创建的是ConnectedStreams或BroadcastConnectedStream,它用了两个泛型,即不要求两个dataStream的element是同一类型。
举例:
package operators;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoMapFunction;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class ConnectDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream9000 = env.socketTextStream("localhost", 9000, "\n");
DataStream<String> textStream9001 = env.socketTextStream("localhost", 9001, "\n");
//转为Integer类型流
DataStream<Integer> intStream = textStream9000.filter(s -> isNumeric(s)).map(s -> Integer.valueOf(s));
//连接起来,分别处理,返回同样的一种类型。
SingleOutputStreamOperator result = intStream.connect(textStream9001)
.map(new CoMapFunction<Integer, String, Tuple2<Integer, String>>() {
@Override
public Tuple2<Integer, String> map1(Integer value) throws Exception {
return Tuple2.of(value, "");
}
@Override
public Tuple2<Integer, String> map2(String value) throws Exception {
return Tuple2.of(null, value);
}
});
//4.打印输出sink
result.print();
//5.开始执行
env.execute();
}
private static boolean isNumeric(String str) {
Pattern pattern = Pattern.compile("[0-9]*");
Matcher isNum = pattern.matcher(str);
if (!isNum.matches()) {
return false;
}
return true;
}
}
参考:https://cloud.tencent.com/developer/article/1382892
将一个流拆分为多个流。
package operators;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.SplitStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class SplitDemo {
public static void main(String[] args) throws Exception {
//1.获取执行环境配置信息
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.定义加载或创建数据源(source),监听9000端口的socket消息
DataStream<String> textStream = env.socketTextStream("localhost", 9000, "\n");
//3.
SplitStream<Tuple2<String, Integer>> result = textStream
//map是将每一行单词变为一个tuple2
.map(line -> Tuple2.of(line.trim(), 1))
//如果要用Lambda表示是,Tuple2是泛型,那就得用returns指定类型。
.returns(Types.TUPLE(Types.STRING, Types.INT))
.split(t -> {
List<String> list = new ArrayList<>();
//根据逻辑拆分,并定义outputName
if (isNumeric(t.f0)) {
list.add("num");
} else {
list.add("str");
}
return list;
});
//选择指定名称的流
DataStream<Tuple2<String, Integer>> strSplitStream = result.select("str")
.map(t -> Tuple2.of("字符串:" + t.f0, t.f1))
.returns(Types.TUPLE(Types.STRING,Types.INT));
//选择指定名称的流
DataStream<Tuple2<String, Integer>> intSplitStream = result.select("num")
.map(t -> Tuple2.of("数字:" + t.f0, t.f1))
.returns(Types.TUPLE(Types.STRING,Types.INT));
//4.打印输出sink
strSplitStream.print();
intSplitStream.print();
//5.开始执行
env.execute();
}
private static boolean isNumeric(String str) {
Pattern pattern = Pattern.compile("[0-9]*");
Matcher isNum = pattern.matcher(str);
if (!isNum.matches()) {
return false;
}
return true;
}
}
对于流式处理,如果我们需要求取总和,平均值,或者最大值,最小值等,是做不到的,因为数据一直在源源不断的产生,即数据是没有边界的,所以没法求最大值,最小值,平均值等,所以为了一些数值统计的功能,我们必须指定时间段,对某一段时间的数据求取一些数据值是可以做到的。或者对某一些数据求取数据值也是可以做到的
所以,流上的聚合需要由 window 来划定范围,比如 “计算过去的5分钟” ,或者 “最后100个元素的和” 。
window是一种可以把无限数据切割为有限数据块的手段
窗口可以是 时间驱动的 【Time Window】(比如:每30秒)或者 数据驱动的【Count Window】 (比如:每100个元素)。
窗口类型汇总:
窗口通常被区分为不同的类型:
l tumbling windows:滚动窗口 【没有重叠】
l sliding windows:滑动窗口 【有重叠】
l session windows:会话窗口 ,一般没人用
tumbling windows类型:没有重叠的窗口
sliding windows:滑动窗口 【有重叠】
Time Window窗口的应用
time window又分为滚动窗口和滑动窗口,这两种窗口调用方法都是一样的,都是调用timeWindow这个方法,如果传入一个参数就是滚动窗口,如果传入两个参数就是滑动窗口
Count Windos窗口的应用
与timeWindow类型,CountWinodw也可以分为滚动窗口和滑动窗口,这两个窗口调用方法一样,都是调用countWindow,如果传入一个参数就是滚动窗口,如果传入两个参数就是滑动窗口
自定义window的应用
如果time window和 countWindow还不够用的话,我们还可以使用自定义window来实现数据的统计等功能。
对于某一个window内的数值统计,我们可以增量的聚合统计或者全量的聚合统计
增量聚合统计:
窗口当中每加入一条数据,就进行一次统计
需求:通过接收socket当中输入的数据,统计每5秒钟数据的累计的值
代码实现:
import org.apache.flink.api.common.functions.ReduceFunction import org.apache.flink.streaming.api.datastream.DataStreamSink import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.api.windowing.time.Time object FlinkTimeCount { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ val socketStream: DataStream[String] = environment.socketTextStream("node01",9000) val print: DataStreamSink[(Int, Int)] = socketStream .map(x => (1, x.toInt)) .keyBy(0) .timeWindow(Time.seconds(5)) .reduce(new ReduceFunction[(Int, Int)] { override def reduce(t: (Int, Int), t1: (Int, Int)): (Int, Int) = { (t._1, t._2 + t1._2) } }).print() environment.execute("startRunning") } }
全量聚合统计:
等到窗口截止,或者窗口内的数据全部到齐,然后再进行统计,可以用于求窗口内的数据的最大值,或者最小值,平均值等
等属于窗口的数据到齐,才开始进行聚合计算【可以实现对窗口内的数据进行排序等需求】
apply(windowFunction)
process(processWindowFunction)
processWindowFunction比windowFunction提供了更多的上下文信息。
需求:通过全量聚合统计,求取每3条数据的平均值
import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.datastream.DataStreamSink import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, WindowedStream} import org.apache.flink.streaming.api.windowing.windows.{GlobalWindow, TimeWindow} import org.apache.flink.util.Collector object FlinkCountWindowAvg { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ val socketStream: DataStream[String] = environment.socketTextStream("node01",9000) //统计一个窗口内的数据的平均值 val socketDatas: DataStreamSink[Double] = socketStream.map(x => (1, x.toInt)) .keyBy(0) //.timeWindow(Time.seconds(10)) .countWindow(3) //通过process方法来统计窗口的平均值 .process(new MyProcessWindowFunctionclass).print() //必须调用execute方法,否则程序不会执行 environment.execute("count avg") } } /**ProcessWindowFunction 需要跟四个参数 * 输入参数类型,输出参数类型,聚合的key的类型,window的下界 * */ class MyProcessWindowFunctionclass extends ProcessWindowFunction[(Int , Int) , Double , Tuple , GlobalWindow]{ override def process(key: Tuple, context: Context, elements: Iterable[(Int, Int)], out: Collector[Double]): Unit = { var totalNum = 0; var countNum = 0; for(data <- elements){ totalNum +=1 countNum += data._2 } out.collect(countNum/totalNum) } }
前面我们已经介绍过我们可以通过window窗口来统计每一段时间或者每多少条数据的一些数值统计,但是也存在另外一个问题,就是如果数据有延迟该如何解决,例如一个窗口定义的是每隔五分钟统计一次,我们应该在上午九点至九点零五分这段时间统计一次数据的结果值,但是由于某一条数据由于网络延迟,数据产生时间是在九点零三分,数据到达我们的flink框架已经是在十点零三分了,这种问题怎么解决??
再例如:
原始日志如下:
日志自带时间
2018-10-10 10:00:01,134 INFO executor.Executor: Finished task in state 0.0
数据进入flink框架时间:
这条数据进入Flink的时间是2018-10-10 20:00:00,102
数据被window窗口处理时间:
到达window处理的时间为2018-10-10 20:00:01,100
为了解决这个问题,flink在实时处理当中,对数据当中的时间规划为以下三个类型
针对stream数据中的时间,可以分为以下三种
l Event Time:事件产生的时间,它通常由事件中的时间戳描述。
l Ingestion time:事件进入Flink的时间
l Processing Time:事件被处理时当前系统的时间
EventTime详解
EventTime
1.事件生成时的时间,在进入Flink之前就已经存在,可以从event的字段中抽取。
2.必须指定watermarks(水位线)的生成方式。
3.优势:确定性,乱序、延时、或者数据重放等情况,都能给出正确的结果
4.弱点:处理无序事件时性能和延迟受到影响
IngestTime
1.事件进入flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间。
2.不需要指定watermarks的生成方式(自动生成)
3.弱点:不能处理无序事件和延迟数据
ProcessingTime
1.执行操作的机器的当前系统时间(每个算子都不一样)
2.不需要流和机器之间的协调
3.优势:最佳的性能和最低的延迟
4.弱点:不确定性 ,容易受到各种因素影像(event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
三种时间的综合比较
性能: ProcessingTime> IngestTime> EventTime
延迟: ProcessingTime< IngestTime< EventTime
确定性: EventTime> IngestTime> ProcessingTime
如何设置time类型
在我们创建StreamExecutionEnvironment的时候可以设置time类型,不设置time类型,默认是processingTime,如果设置time类型为eventTime,那么必须要在我们的source之后明确指定Timestamp Assigner & Watermark Generator
// 设置时间特性
val environment: StreamExecutionEnvironment =
StreamExecutionEnvironment.getExecutionEnvironment
// 不设置Time 类型,默认是processingTime。
// 如果使用EventTime则需要在source之后明确指定Timestamp
Assigner & Watermark Generator
environment.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)
watermark的作用
watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。
但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
watermark解决迟到的数据
out-of-order/late element
实时系统中,由于各种原因造成的延时,造成某些消息发到flink的时间延时于事件产生的时间。如果基于event time构建window,但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。
Watermarks(水位线)就是来处理这种问题的机制
1.参考google的DataFlow。
2.是event time处理进度的标志。
3.表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据 )。
4.基于watermark来进行窗口触发计算的判断。
有序的数据流watermark:
在某些情况下,基于Event Time的数据流是有续的(相对event time)。在有序流中,watermark就是一个简单的周期性标记。
无序的数据流watermark:
在更多场景下,基于Event Time的数据流是无续的(相对event time)。
在无序流中,watermark至关重要,她告诉operator比watermark更早(更老/时间戳更小)的事件已经到达, operator可以将内部事件时间提前到watermark的时间戳(可以触发window计算啦)
并行流当中的watermark:
通常情况下, watermark在source函数中生成,但是也可以在source后任何阶段,如果指定多次 watermark,后面指定的 watermarker会覆盖前面的值。 source的每个sub task独立生成水印。
watermark通过operator时会推进operators处的当前event time,同时operators会为下游生成一个新的watermark。
多输入operator(union、 keyBy、 partition)的当前event time是其输入流event time的最小值。
注意:多并行度的情况下,watermark对齐会取所有channel最小的watermark
watermark介绍参考链接:
https://blog.csdn.net/xorxos/article/details/80715113
watermark如何生成
通常,在接收到source的数据后,应该立刻生成watermark;但是,也可以在source后,应用简单的map或者filter操作,然后再生成watermark。
生成watermark的方式主要有2大类:
1. (1):With Periodic Watermarks
2. (2):With Punctuated Watermarks
第一种可以定义一个最大允许乱序的时间,这种情况应用较多。
我们主要来围绕Periodic Watermarks来说明,下面是生成periodic watermark的方法:
watermark处理顺序数据
需求:定义一个窗口为10s,通过数据的event time时间结合watermark实现延迟10s的数据也能够正确统计
我们通过数据的eventTime来向前推10s,得到数据的watermark,
代码实现:
import java.text.SimpleDateFormat import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.functions.{AssignerWithPeriodicWatermarks, AssignerWithPunctuatedWatermarks} import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment} import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import scala.collection.mutable.ArrayBuffer import scala.util.Sorting object FlinkWaterMark2 { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ //设置flink的数据处理时间为eventTime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) env.setParallelism(1) val tupleStream: DataStream[(String, Long)] = env.socketTextStream("node01", 9000).map(x => { val strings: Array[String] = x.split(" ") (strings(0), strings(1).toLong) }) //注册我们的水印 val waterMarkStream: DataStream[(String, Long)] = tupleStream.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks[(String, Long)] { var currentTimemillis: Long = 0L var timeDiff: Long = 10000L val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); /* //获取当前数据的waterMark override def getNext: Watermark = { }*/ override def getCurrentWatermark: Watermark = { val watermark = new Watermark(currentTimemillis - timeDiff) watermark } //抽取数据的eventTime override def extractTimestamp(element: (String, Long), l: Long): Long = { val enventTime = element._2 currentTimemillis = Math.max(enventTime, currentTimemillis) val id = Thread.currentThread().getId println("currentThreadId:" + id + ",key:" + element._1 + ",eventtime:[" + element._2 + "|" + sdf.format(element._2) + "],currentMaxTimestamp:[" + currentTimemillis + "|" + sdf.format(currentTimemillis) + "],watermark:[" + this.getCurrentWatermark.getTimestamp + "|" + sdf.format(this.getCurrentWatermark.getTimestamp) + "]") enventTime } }) waterMarkStream.keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(10))) .apply(new MyWindowFunction2).print() env.execute() } } class MyWindowFunction2 extends WindowFunction[(String,Long),String,Tuple,TimeWindow]{ override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = { val keyStr = key.toString val arrBuf = ArrayBuffer[Long]() val ite = input.iterator while (ite.hasNext){ val tup2 = ite.next() arrBuf.append(tup2._2) } val arr = arrBuf.toArray Sorting.quickSort(arr) //对数据进行排序,按照eventTime进行排序 val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); val result = "聚合数据的key为:"+keyStr + "," + "窗口当中数据的条数为:"+arr.length + "," + "窗口当中第一条数据为:"+sdf.format(arr.head) + "," +"窗口当中最后一条数据为:"+ sdf.format(arr.last)+ "," + "窗口起始时间为:"+sdf.format(window.getStart) + "," + "窗口结束时间为:"+sdf.format(window.getEnd) + "!!!!!看到这个结果,就证明窗口已经运行了" out.collect(result) } }
输入测验数据
注意:如果需要触发flink的窗口调用,必须满足两个条件
1:waterMarkTime > eventTime
2:窗口内有数据
数据输入测验:
按照十秒钟统计一次,我们程序会将时间划分成为以下时间间隔段
2019-10-01 10:11:00 到 2019-10-01 10:11:10
2019-10-01 10:11:10 到 2019-10-01 10:11:20
2019-10-01 10:11:20 到 2019-10-01 10:11:30
2019-10-01 10:11:30 到 2019-10-01 10:11:40
2019-10-01 10:11:40 到 2019-10-01 10:11:50
2019-10-01 10:11:50 到 2019-10-01 10:12:00
顺序计算:
触发数据计算的条件依据为两个
第一个waterMark时间大于数据的eventTime时间,第二个窗口之内有数据
我们这里的waterMark直接使用eventTime的最大值减去10秒钟
0001 1569895882000 数据eventTime为:2019-10-01 10:11:22 数据waterMark为 2019-10-01 10:11:12
0001 1569895885000 数据eventTime为:2019-10-01 10:11:25 数据waterMark为 2019-10-01 10:11:15
0001 1569895888000 数据eventTime为:2019-10-01 10:11:28 数据waterMark为 2019-10-01 10:11:18
0001 1569895890000 数据eventTime为:2019-10-01 10:11:30 数据waterMark为 2019-10-01 10:11:20
0001 1569895891000 数据eventTime为:2019-10-01 10:11:31 数据waterMark为 2019-10-01 10:11:21
0001 1569895895000 数据eventTime为:2019-10-01 10:11:35 数据waterMark为 2019-10-01 10:11:25
0001 1569895898000 数据eventTime为:2019-10-01 10:11:38 数据waterMark为 2019-10-01 10:11:28
0001 1569895900000 数据eventTime为:2019-10-01 10:11:40 数据waterMark为 2019-10-01 10:11:30 触发第一条到第三条数据计算,数据包前不包后,不会计算2019-10-01 10:11:30 这条数据
0001 1569895911000 数据eventTime为:2019-10-01 10:11:51 数据waterMark为 2019-10-01 10:11:41 触发2019-10-01 10:11:20到2019-10-01 10:11:28时间段的额数据计算,数据包前不包后,不会触发2019-10-01 10:11:30这条数据的计算
watermark处理乱序数据
输入测验数据
接着继续输入以下乱序数据,验证flink乱序数据的问题是否能够解决
乱序数据
0001 1569895948000 数据eventTime为:2019-10-01 10:12:28 数据waterMark为 2019-10-01 10:12:18
0001 1569895945000 数据eventTime为:2019-10-01 10:12:25 数据waterMark为 2019-10-01 10:12:18
0001 1569895947000 数据eventTime为:2019-10-01 10:12:27 数据waterMark为 2019-10-01 10:12:18
0001 1569895950000 数据eventTime为:2019-10-01 10:12:30 数据waterMark为 2019-10-01 10:12:20
0001 1569895960000 数据eventTime为:2019-10-01 10:12:40 数据waterMark为 2019-10-01 10:12:30 触发计算 waterMark > eventTime 并且窗口内有数据,触发 2019-10-01 10:12:28到2019-10-01 10:12:27 这三条数据的计算,数据包前不包后,不会触发2019-10-01 10:12:30 这条数据的计算
0001 1569895949000 数据eventTime为:2019-10-01 10:12:29 数据waterMark为 2019-10-01 10:12:30 迟到太多的数据,flink直接丢弃,可以设置flink将这些迟到太多的数据保存起来,便于排查问题
比watermark更晚的数据如何解决
如果我们设置数据的watermark为每条数据的eventtime往后一定的时间,例如数据的eventtime为2019-08-20 15:30:30,程序的window窗口为10s,然后我们设置的watermark为2019-08-20 15:30:40,
那么如果某一条数据eventtime为2019-08-20 15:30:32,到达flink程序的时间为2019-08-20 15:30:45 该怎么办,这条数据比窗口的watermark时间还要晚了5S钟该怎么办??对于这种比watermark还要晚的数据,flink有三种处理方式
1、直接丢弃
我们输入一个乱序很多的(其实只要 Event Time < watermark 时间)数据来测试下: 输入:【输入两条内容】
late element
0001 1569895948000 数据eventTime为:2019-10-01 10:12:28 数据直接丢弃
0001 1569895945000 数据eventTime为:2019-10-01 10:12:25 数据直接丢弃
注意:此时并没有触发 window。因为输入的数据所在的窗口已经执行过了,flink 默认对这 些迟到的数据的处理方案就是丢弃。
2、allowedLateness 指定允许数据延迟的时间
在某些情况下,我们希望对迟到的数据再提供一个宽容的时间。
Flink 提供了 allowedLateness 方法可以实现对迟到的数据设置一个延迟时间,在指定延迟时间内到达的数据还是可以触发 window 执行的。
修改代码:
waterMarkStream .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(3))) .allowedLateness(Time.seconds(2))//允许数据迟到2S //function: (K, W, Iterable[T], Collector[R]) => Unit .apply(new MyWindowFunction).print()
验证数据迟到性:
输入数据:
更改代码之后重启我们的程序,然后从新输入之前的数据
0001 1569895882000
0001 1569895885000
0001 1569895888000
0001 1569895890000
0001 1569895891000
0001 1569895895000
0001 1569895898000
0001 1569895900000
0001 1569895911000
0001 1569895948000
0001 1569895945000
0001 1569895947000
0001 1569895950000
0001 1569895960000
0001 1569895949000
验证数据的延迟性:定义数据仅仅延迟2S的数据重新接收,重新计算
0001 1569895948000 数据eventTime为:2019-10-01 10:12:28 触发数据计算 数据waterMark为 2019-10-01 10:12:30
0001 1569895945000 数据eventTime为:2019-10-01 10:12:25 触发数据计算 数据waterMark为 2019-10-01 10:12:30
0001 1569895958000 数据eventTime为:2019-10-01 10:12:38 不会触发数据计算 数据waterMark为 2019-10-01 10:12:30 waterMarkTime < eventTime,所以不会触发计算
将数据的waterMark调整为41秒就可以触发上面这条数据的计算了
0001 1569895971000 数据eventTime为:2019-10-01 10:12:51 数据waterMark为 2019-10-01 10:12:41
又会继续触发0001 1569895958000 这条数据的计算了
3、sideOutputLateData 收集迟到的数据
通过 sideOutputLateData 可以把迟到的数据统一收集,统一存储,方便后期排查问题。 需要先调整代码:
import java.text.SimpleDateFormat import org.apache.flink.api.java.tuple.Tuple import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.datastream.DataStreamSink import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks import org.apache.flink.streaming.api.scala.function.WindowFunction import org.apache.flink.streaming.api.scala.{DataStream, OutputTag, StreamExecutionEnvironment} import org.apache.flink.streaming.api.watermark.Watermark import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector import scala.collection.mutable.ArrayBuffer import scala.util.Sorting object FlinkWaterMark { def main(args: Array[String]): Unit = { val env = StreamExecutionEnvironment.getExecutionEnvironment import org.apache.flink.api.scala._ //设置time类型为eventtime env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //暂时定义并行度为1 env.setParallelism(1) val text = env.socketTextStream("node01",9000) val inputMap: DataStream[(String, Long)] = text.map(line => { val arr = line.split(" ") (arr(0), arr(1).toLong) }) //给我们的数据注册waterMark val waterMarkStream: DataStream[(String, Long)] = inputMap .assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks[(String, Long)] { var currentMaxTimestamp = 0L //watermark基于eventTime向后推迟10秒钟,允许消息最大乱序时间为10s val waterMarkDiff: Long = 10000L val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); //获取下一个水印 override def checkAndGetNextWatermark(t: (String, Long), l: Long): Watermark = { val watermark = new Watermark(currentMaxTimestamp - waterMarkDiff) watermark } //抽取当前数据的时间作为eventTime override def extractTimestamp(element: (String, Long), l: Long): Long = { val eventTime = element._2 currentMaxTimestamp = Math.max(eventTime, currentMaxTimestamp) val id = Thread.currentThread().getId println("currentThreadId:"+id+",key:"+element._1+",eventtime:["+element._2+"|"+sdf.format(element._2)+"],currentMaxTimestamp:["+currentMaxTimestamp+"|"+ sdf.format(currentMaxTimestamp)+"],watermark:["+this.checkAndGetNextWatermark(element,l).getTimestamp+"|"+sdf.format(this.checkAndGetNextWatermark(element,l).getTimestamp)+"]") eventTime } }) val outputTag: OutputTag[(String, Long)] = new OutputTag[(String,Long)]("late_data") val outputWindow: DataStream[String] = waterMarkStream .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(3))) // .allowedLateness(Time.seconds(2))//允许数据迟到2S .sideOutputLateData(outputTag) //function: (K, W, Iterable[T], Collector[R]) => Unit .apply(new MyWindowFunction) val sideOuptut: DataStream[(String, Long)] = outputWindow.getSideOutput(outputTag) sideOuptut.print() outputWindow.print() //执行程序 env.execute() } } class MyWindowFunction extends WindowFunction[(String,Long),String,Tuple,TimeWindow]{ override def apply(key: Tuple, window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = { val keyStr = key.toString val arrBuf = ArrayBuffer[Long]() val ite = input.iterator while (ite.hasNext){ val tup2 = ite.next() arrBuf.append(tup2._2) } val arr = arrBuf.toArray Sorting.quickSort(arr) val sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss.SSS"); val result = keyStr + "," + arr.length + "," + sdf.format(arr.head) + "," + sdf.format(arr.last)+ "," + sdf.format(window.getStart) + "," + sdf.format(window.getEnd) out.collect(result) } }
我们来输入一些数据验证一下 输入:
0001 1569895882000
0001 1569895885000
0001 1569895888000
0001 1569895890000
0001 1569895891000
0001 1569895895000
0001 1569895898000
0001 1569895900000
0001 1569895911000
0001 1569895948000
0001 1569895945000
0001 1569895947000
0001 1569895950000
0001 1569895960000
0001 1569895949000
输入两条迟到的数据,会被收集起来
0001 1569895948000
0001 1569895945000
此时,针对这几条迟到的数据,都通过 sideOutputLateData 保存到了 outputTag 中。
7、多并行度的watermark机制
前面代码中设置了并行度为 1
env.setParallelism(1);
如果这里不设置的话,代码在运行的时候会默认读取本机 CPU 数量设置并行度。 把代码的并行度代码注释掉
//env.setParallelism(1)
然后在输出内容前面加上线程 id
会出现如下数据: 输入如下几行内容:
输出:
会发现 window 没有被触发。
因为此时,这 7 条数据都是被不同的线程处理的。每个线程都有一个 watermark。
因为在多并行度的情况下,watermark 对齐会取所有 channel 最小的 watermark 但是我们现在默认有 8 个并行度,这 7 条数据都被不同的线程所处理,到现在还没获取到最 小的 watermark,所以 window 无法被触发执行。
下面我们来验证一下,把代码中的并行度调整为 2.
env.setParallelism(2)
输入如下内容:
0001 1569895890000
0001 1569895903000
0001 1569895908000
输出:
此时会发现,当第三条数据输入完以后,[10:11:30,10:11:33)这个 window 被触发了。 前两条数据输入之后,获取到的最小 watermark 是 10:11:20,这个时候对应的 window 中没 有数据。
第三条数据输入之后,获取到的最小 watermark 是 10:11:33,这个时候对应的窗口就是 [10:11:30,10:11:33)。所以就触发了。
我们前面写的word count的例子,没有包含状态管理。如果一个task在处理过程中挂掉了,那么它在内存中的状态都会丢失,所有的数据都需要重新计算。从容错和消息处理的语义上(at least once, exactly once),Flink引入了state和checkpoint。
首先区分一下两个概念
state一般指一个具体的task/operator的状态【state数据默认保存在java的堆内存中】
而checkpoint【可以理解为checkpoint是把state数据持久化存储了】,则表示了一个Flink Job在一个特定时刻的一份全局状态快照,即包含了所有task/operator的状态
注意:task是Flink中执行的基本单位。operator指算子(transformation)。
State可以被记录,在失败的情况下数据还可以恢复
Flink中有两种基本类型的State
Keyed State
Operator State
针对两种state,每种state都有两种方式存在
托管状态是由Flink框架管理的状态
而原始状态,由用户自行管理状态具体的数据结构,框架在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知。
通常在DataStream上的状态推荐使用托管的状态,当实现一个用户自定义的operator时,会使用到原始状态
flink官网关于state的介绍
1、keyed state的托管状态
顾名思义,就是基于KeyedStream上的状态。这个状态是跟特定的key绑定的,对KeyedStream流上的每一个key,都对应一个state。stream.keyBy(…)
保存state的数据结构
ValueState<T>:即类型为T的单值状态。这个状态与对应的key绑定,是最简单的状态了。它可以通过update方法更新状态值,通过value()方法获取状态值
ListState<T>:即key上的状态值为一个列表。可以通过add方法往列表中附加值;也可以通过get()方法返回一个Iterable<T>来遍历状态值
ReducingState<T>:这种状态通过用户传入的reduceFunction,每次调用add方法添加值的时候,会调用reduceFunction,最后合并到一个单一的状态值
MapState<UK, UV>:即状态值为一个map。用户通过put或putAll方法添加元素
需要注意的是,以上所述的State对象,仅仅用于与状态进行交互(更新、删除、清空等),而真正的状态值,有可能是存在内存、磁盘、或者其他分布式存储系统中。相当于我们只是持有了这个状态的句柄
2、operator state托管状态
对于与key无关的dataStream可以进行状态托管,与算子进行绑定,对我们的数据进行处理
与Key无关的State,与Operator绑定的state,整个operator只对应一个state保存state的数据结构一般使用ListState<T>
举例来说,Flink中的Kafka Connector,就使用了operator state。它会在每个connector实例中,保存该实例中消费topic的所有(partition, offset)映射
3、Flink的checkPoint保存数据
checkPoint的基本概念
为了保证state的容错性,Flink需要对state进行checkpoint。
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些快照进行恢复,从而修正因为故障带来的程序数据异常
checkPoint的前提
Flink的checkpoint机制可以与(stream和state)的持久化存储交互的前提:
1、持久化的source,它需要支持在一定时间内重放事件。这种sources的典型例子是持久化的消息队列(比如Apache Kafka,RabbitMQ等)或文件系统(比如HDFS,S3,GFS等)
2、用于state的持久化存储,例如分布式文件系统(比如HDFS,S3,GFS等)
Flink进行checkpoint需要的步骤
如上所述,这里才需要“暂停输入+排干on-the-fly数据”的操作,这样才能拿到同一时刻下所有subtask的state
配置checkPoint
默认checkpoint功能是disabled的,想要使用的时候需要先启用
checkpoint开启之后,默认的checkPointMode是Exactly-once
checkpoint的checkPointMode有两种,Exactly-once和At-least-once
Exactly-once对于大多数应用来说是最合适的。At-least-once可能用在某些延迟超低的应用程序(始终延迟为几毫秒)
//默认checkpoint功能是disabled的,想要使用的时候需要先启用
// 每隔1000 ms进行启动一个检查点【设置checkpoint的周期】
environment.enableCheckpointing(1000);
// 高级选项:
// 设置模式为exactly-once (这是默认值)
environment.getCheckpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确保检查点之间有至少500 ms的间隔【checkpoint最小间隔】
environment.getCheckpointConfig.setMinPauseBetweenCheckpoints(500);
// 检查点必须在一分钟内完成,或者被丢弃【checkpoint的超时时间】
environment.getCheckpointConfig.setCheckpointTimeout(60000);
// 同一时间只允许进行一个检查点
environment.getCheckpointConfig.setMaxConcurrentCheckpoints(1);
// 表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint【详细解释见备注】
/**
*
ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:表示一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint
*
ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION: 表示一旦Flink处理程序被cancel后,会删除Checkpoint数据,只有job执行失败的时候才会保存checkpoint
*/
environment.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
Flink的checkPoint状态管理之State Backend
默认情况下,state会保存在taskmanager的内存中,checkpoint会存储在JobManager的内存中。
state 的store和checkpoint的位置取决于State Backend的配置
env.setStateBackend(…)
一共有三种State Backend
MemoryStateBackend # 内存存储
FsStateBackend # 文件系统存储
RocksDBStateBackend # rocksDB是一个数据库
1、MemoryStateBackend
将数据持久化状态存储到内存当中,state数据保存在java堆内存中,执行checkpoint的时候,会把state的快照数据保存到jobmanager的内存中。基于内存的state backend在生产环境下不建议使用
代码配置:
// environment.setStateBackend(new MemoryStateBackend())
2、FsStateBackend
state数据保存在taskmanager的内存中,执行checkpoint的时候,会把state的快照数据保存到配置的文件系统中。可以使用hdfs等分布式文件系统
代码配置:
//environment.setStateBackend(new FsStateBackend("hdfs://node01:8020"))
3、RocksDBStateBackend
RocksDB介绍:RocksDB使用一套日志结构的数据库引擎,为了更好的性能,这套引擎是用C++编写的。 Key和value是任意大小的字节流。RocksDB跟上面的都略有不同,它会在本地文件系统中维护状态,state会直接写入本地rocksdb中。同时它需要配置一个远端的filesystem uri(一般是HDFS),在做checkpoint的时候,会把本地的数据直接复制到filesystem中。fail over的时候从filesystem中恢复到本地RocksDB克服了state受内存限制的缺点,同时又能够持久化到远端文件系统中,比较适合在生产中使用
代码配置:导入jar包然后配置代码
<dependency> <groupId>org.apache.flink</groupId> <artifactId>flink-statebackend-rocksdb_2.11</artifactId> <version>1.8.1</version> </dependency>
配置代码
environment.setStateBackend(new RocksDBStateBackend("hdfs://node01:8020/flink/checkDir",true))
4、修改state-backend的两种方式
修改State Backend的两种方式
第一种:单任务调整
修改当前任务代码
env.setStateBackend(new FsStateBackend("hdfs://node01:8020/flink/checkpoints"));
或者new MemoryStateBackend()
或者new RocksDBStateBackend(filebackend, true);【需要添加第三方依赖】
第二种:全局调整
修改flink-conf.yaml
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:9000/flink/checkpoints
注意:state.backend的值可以是下面几种:
jobmanager(MemoryStateBackend),
filesystem(FsStateBackend),
rocksdb(RocksDBStateBackend)
从checkPoint恢复数据以及checkPoint保存多个
保存多个历史版本
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前
Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数
state.checkpoints.num-retained: 20
这样设置以后就查看对应的Checkpoint在HDFS上存储的文件目录
hdfs dfs -ls hdfs://node01:8020/flink/checkpoints
如果希望回退到某个Checkpoint点,只需要指定对应的某个Checkpoint路径即可实现
如果Flink程序异常失败,或者最近一段时间内数据处理错误,我们可以将程序从某一个Checkpoint点进行恢复
bin/flink run -s hdfs://node01:8020/flink/checkpoints/467e17d2cc343e6c56255d222bae3421/chk-56/_metadata flink-job.jar
程序正常运行后,还会按照Checkpoint配置进行运行,继续生成Checkpoint数据
4、Flink的savePoint保存数据
savePoint的介绍
Flink通过Savepoint功能可以做到程序升级后,继续从升级前的那个点开始执行计算,保证数据不中断。
全局,一致性快照。可以保存数据源offset,operator操作状态等信息,可以从应用在过去任意做了savepoint的时刻开始继续消费
用户手动执行,是指向Checkpoint的指针,不会过期
在程序升级的情况下使用
注意:为了能够在作业的不同版本之间以及 Flink 的不同版本之间顺利升级,强烈推荐程序员通过 uid(String) 方法手动的给算子赋予 ID,这些 ID 将用于确定每一个算子的状态范围。如果不手动给各算子指定 ID,则会由 Flink 自动给每个算子生成一个 ID。只要这些 ID 没有改变就能从保存点(savepoint)将程序恢复回来。而这些自动生成的 ID 依赖于程序的结构,并且对代码的更改是很敏感的。因此,强烈建议用户手动的设置 ID。
savePoint的使用
1:在flink-conf.yaml中配置Savepoint存储位置
不是必须设置,但是设置后,后面创建指定Job的Savepoint时,可以不用在手动执行命令时指定Savepoint的位置
state.savepoints.dir: hdfs://node01:8020/flink/savepoints
2:触发一个savepoint【直接触发或者在cancel的时候触发】
bin/flink savepoint jobId [targetDirectory] [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
bin/flink cancel -s [targetDirectory] jobId [-yid yarnAppId]【针对on yarn模式需要指定-yid参数】
3:从指定的savepoint启动job
bin/flink run -s savepointPath [runArgs]
标签:系统 python 特性 release 次数 元素 isa 时间段 rac
原文地址:https://www.cnblogs.com/aidata/p/12542307.html