标签:segment false 音乐 detail dir out 外网 相关 卷积层
现在网上基本都没有对应的基于神经网络声音分类识别的较简单的教程,所以我打算通过我自己的思路,编写出一个实现男女声音识别的一个深度学习的模型。
因为没有验证过该想法是否正确,所以想通过该博客来记录实验的结果,无论最终是否能成功识别男女声音,我都想将此次的实验记录下来。
首先从网站http://festvox.org/cmu_arctic/dbs_bdl.html,爬取相关的男人和女人的声音文件。
爬取过程的代码如下,省略,以下直接用到我的代码仓库中的爬取代码:(将在最后提供爬取的男女声音文件集合,A表示男人声音,B表示女人声音)
漫长的等待结果,由于是外网,虽然声音文件都很小,但是每个都要下载很久,这里不管了,先让他慢慢爬取,接着通过博客:
https://segmentfault.com/a/1190000020905581?utm_source=tag-newest
得到对应声音的波形图绘制方法。
思路就是通过声音所生成的波形图,然后将图片代入神经网络中,让其自己分析出特征,看能否实现声音的识别。
这时候,声音还没有爬取完成,我们接着等待,可以先去吃个苹果。
爬取完成之后,选取了qq音乐中的一首歌然后试试看能不能生成:
结果出现了,错误:RuntimeWarning: Couldn‘t find ffprobe or avprobe - defaulting to ffprobe, but may not work
warn("Couldn‘t find ffprobe or avprobe - defaulting to ffprobe, but may not work", RuntimeWarning)
通过这篇博客https://blog.csdn.net/qq_40152706/article/details/89058480得知,要下载对应ffprobe的包,所以这里先下载:
设置环境变量,解压后设置环境变量。
根据上述的博客,我们可以编写出以下的生成波形图的通用函数:
def sound_to_image(filename, out): # 读取生成波形图 samplerate, data = wavfile.read(filename) times = np.arange(len(data)) / float(samplerate) # print(len(data), samplerate, times) # 可以以寸为单位自定义宽高 frameon=False 为关闭边框 fig = plt.figure(figsize=(20, 5), facecolor="White") # plt.tick_params(top=‘off‘, bottom=‘off‘, left=‘off‘, right=‘off‘, labelleft=‘off‘, labelbottom=‘on‘) ax = fig.add_axes([0, 0, 1, 1]) ax.axis(‘off‘) plt.fill_between(times, data, linewidth=‘1‘, color=‘green‘) plt.xticks([]) plt.yticks([]) plt.savefig(out, dpi=100, transparent=False, bbox_inches=‘tight‘, edgecolor=‘w‘) # plt.show() # image_dirchange_to(r‘C:\Users\Halo\Desktop\1.6项目开发过程‘,‘.jpg‘,r‘C:\Users\Halo\Desktop\1.6项目开发过程\test‘,‘.bmp‘,20,20)
将图片转化成声波图的效果如下:

将图片转化成160*40的大小之后,经过不断的学习
构建卷积神经网络模型:
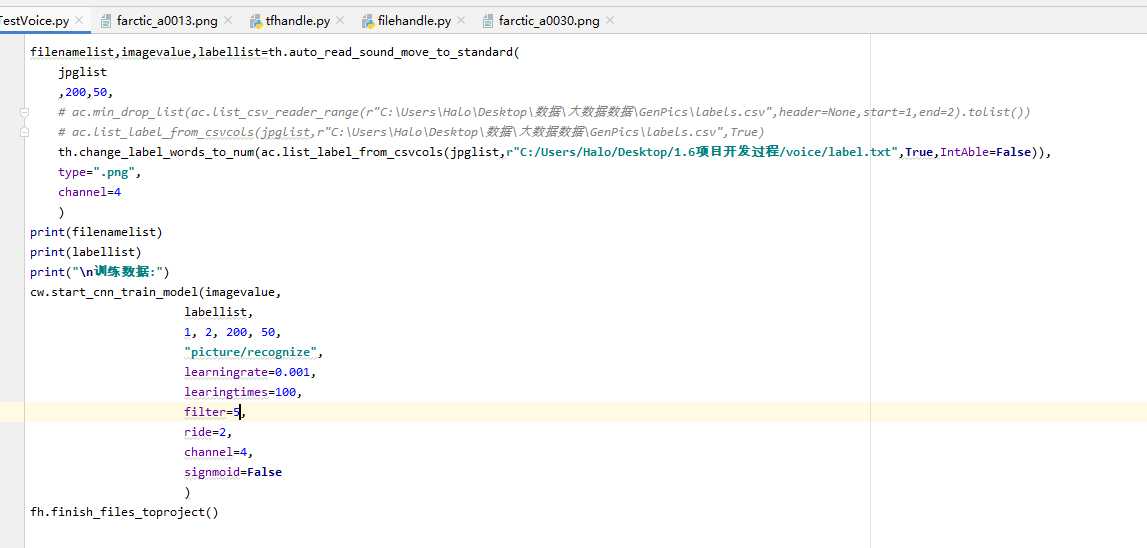
将对应的数据经过,参数的不断调试,测试得第一个卷积层大小为2,步长为1时有较好的识别效果。100次迭代之后,如下:

接下来抽取从网上下载的另外的声音文件进行识别:
去下载了几个声音来进行识别:
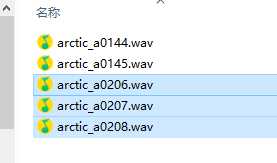
选中的是男人的声音标记为A,未选中的是女人的声音。
接下来构建卷积神经网络模型。用softmax函数进行识别,由于是二分类问题,构建的模型参数如下:
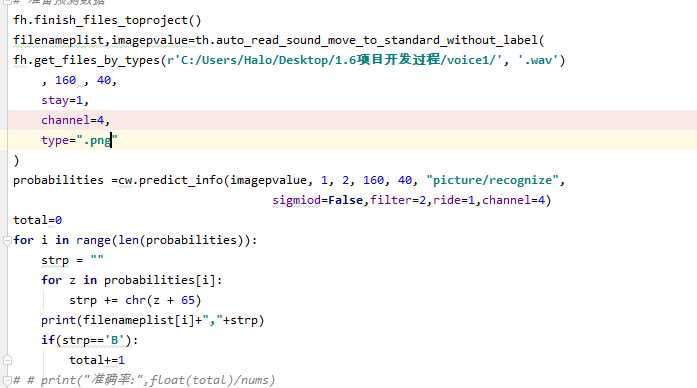
识别结果
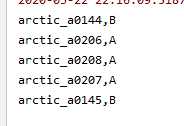
其中arctic_a02开头的是男人声音,arctic_a01开头是女人的声音,由此,声音识别的卷积神经网络搭建完成,能够分辨出男人女人的声音。
5个样本识别正确率100%。
Tensorflow--基于卷积神经网络实现男女声音分类识别
标签:segment false 音乐 detail dir out 外网 相关 卷积层
原文地址:https://www.cnblogs.com/halone/p/12548024.html