标签:strong 最简 遇到 不提交 传递 job 简单 rod style
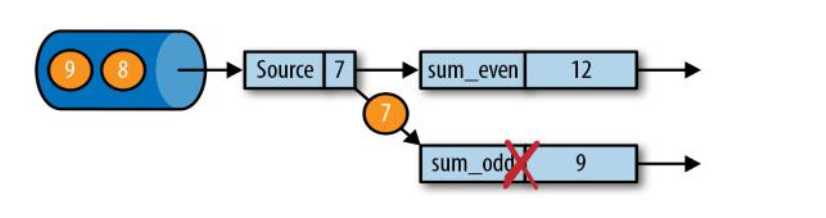
有状态的流处理,内部每个算子任务都可以有自己的状态;
对于流处理器内部(没有接入sink)来说,所谓的状态一致性,其实就是我们所说的计算结果要保证准确;
一条数据不应该丢失,也不应该重复计算;
在遇到故障时可以恢复状态,恢复以后的重新计算,结果应该也是完全正常的;
状态一致性分类:
AT_MOST_ONCE(最多一次),当任务故障时最简单做法是什么都不干,既不恢复丢失状态,也不重播丢失数据。At-most-once语义的含义是最多处理一次事件。
AT_LEAST_ONCE(至少一次),在大多数真实应用场景,我们希望不丢失数据。这种类型的保障称为at-least-once,意思是所有的事件都得到了处理,而一些事件还可能被处理多次。
EXACTLY_ONCE(精确一次),恰好处理一次是最严格的的保证,也是最难实现的。恰好处理一次语义不仅仅意味着没有事件丢失,还意味着针对每一个数据,内部状态仅仅更新一次。
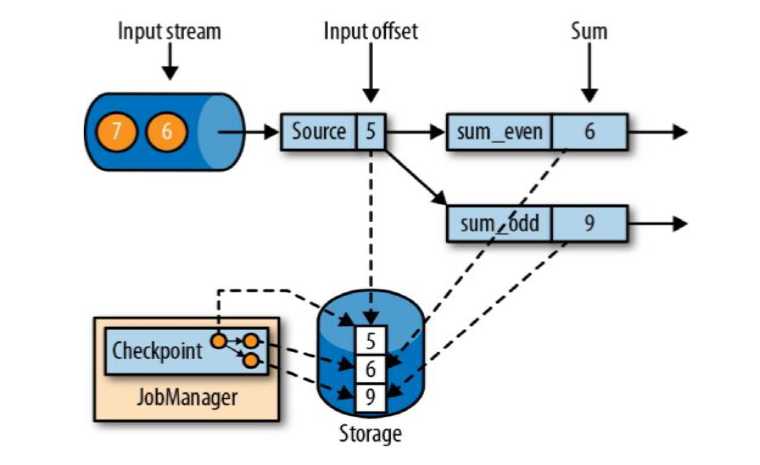
一致性检查点(Checkpoints)
Flink使用了一种轻量级快照机制 --- 检查点(Checkpoint)来保证exactly-one语义;
有状态流应用的一致检查点,其实就是:所有任务的状态,在某个时间点的一份拷贝(一份快照)。而这个时间点,应该是所有任务都恰好处理完一个相同的输入数据的时候。
应用状态的一致性检查点,是Flink故障恢复机制的核心。
目前我们看到的一致性保证都是由流处理器实现的,也就是说都是在Flink流处理内部保证的;而在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如kafka)和输出到持久化系统;
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终,每个组件都保证了它自己的一致性;
整个端到端的一致性级别取决于所有组件中一致性最弱的组件;
内部保证 --- checkpoint
source端 --- 可重设数据的读取位置;可重新读取偏移量
sink端 -- 从故障恢复时,数据不会重复写入外部系统:幂等写入和事务写入;
幂等写入(Idempotent Writes):
幂等操作即一个操作可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了;
它的原理不是不重复写入而是重复写完之后结果还是一样;它的瑕疵是不能做到完全意义上exactly-once(在故障恢复时,突然把外部系统写入操作跳到之前的某个状态然后继续往里边写,故障之前发生的那一段的状态变化又重演了直到最后发生故障那一刻追上就正常了;假如中间这段又被读取了就可能会有些问题);
事务写入(Transactional Writes):
事务Transactional Writes
实现思想:构建的事务对应着checkpoint,等到checkpoint真正完成的时候,才把所有对应的结果写入sink系统中。
实现方式:预习日志和两阶段提交
预习日志(Write-Ahead-Log,WAL)
把结果数据先当成状态保存,然后在收到checkpoint完成的通知时,一次性写入sink系统;
简单易于实现,由于数据提前在状态后端中做了缓存,所以无论什么sink系统,都能用这种方式一批搞定;
DataStream API提供了一个模板类:GenericWriteAheadSink,来实现这种事务性sink;
瑕疵:A. sink系统没说它支持事务,有可能出现一部分写进去了一部分没写进去(如果算失败,再写一次就写了两次了);
B. checkpoint做完了sink才去真正写入(但其实得等sink都写完checkpoint才能生效,所以WAL这个机制jobmanager确定它写完还不算真正写完,还得有一个外部系统已经确认完成的checkpoint)
两阶段提交(Two--Phase--Commit,2PC)-- 真正能够实现exactly-once
对于每个checkpoint,sink任务会启动一个事务,并将接下来所有接收的数据添加到事务里;
然后将这些数据写入外部sink系统,但不提交他们 -- 这时只是预提交;
当它收到checkpoint完成时的通知,它才正式提交事务,实现结果的真正写入;
这种方式真正实现了exactly-once,它需要一个提供事务支持的外部sink系统,Flink提供了TwoPhaseCommitSinkFunction接口。
2PC对外部sink的要求
外部sink系统必须事务支持,或者sink任务必须能够模拟外部系统上的事务;
在checkpoint的间隔期间里,必须能够开启一个事务,并接受数据写入;
在收到checkpoint完成的通知之前,事务必须是“等待提交”的状态,在故障恢复的情况下,这可能需要一些时间。如果这个时候sink系统关闭事务(例如超时了),那么未提交的数据就会丢失;
sink任务必须能够在进程失败后恢复事务;
提交事务必须是幂等操作;
不同Source和sink的一致性保证:
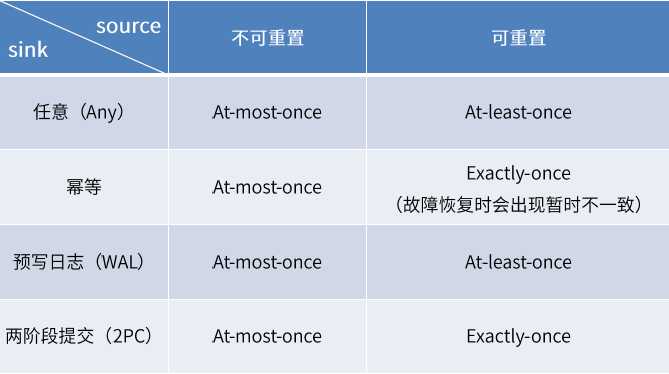
Flink和kafka天生就是一对,用kafka做为source,用kafka做完sink <===> 实现端到端的一致性
内部 -- 利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性;
source -- kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性;
sink -- kafka producer作为sink,采用两阶段提交sink,需要实现一个TwoPhaseCommitSinkFunction


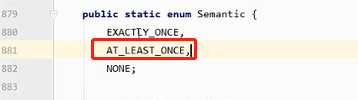
默认是AT_LEAST_ONCE
Exactly-once两阶段提交
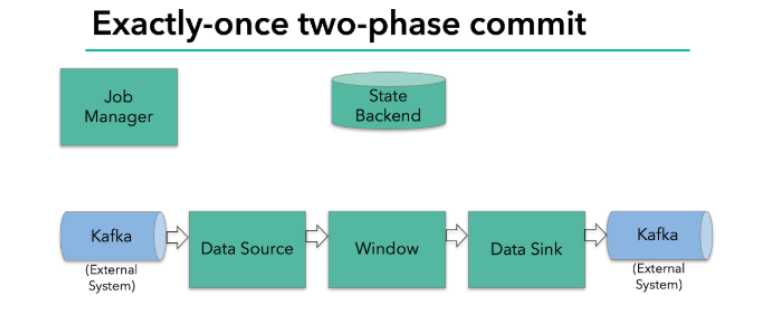
JobManager协调各个TaskManager进行checkpoint存储;
checkpoint保存在StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存;
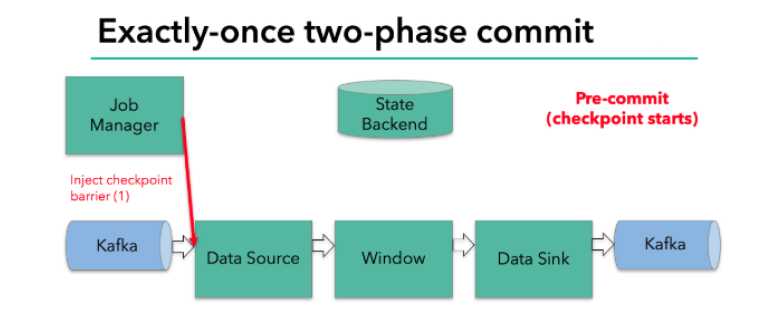
当checkpoint启动时,JobManager会将检查点分界线(barrier)注入数据流;
barrier会在算子间传递下去;
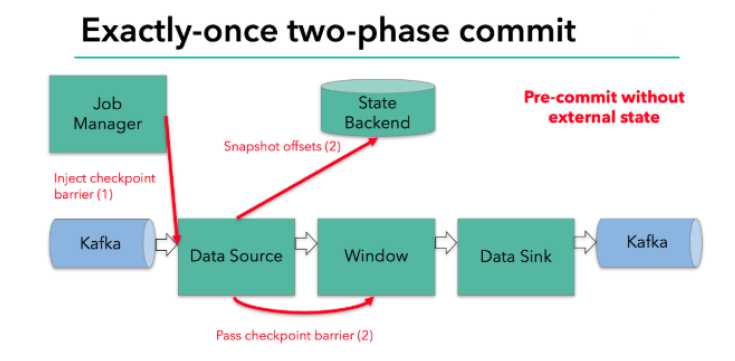
每个算子会对当前的状态做个快照,保存到状态后端;
checkpoint机制可以保证内部的状态一致性;
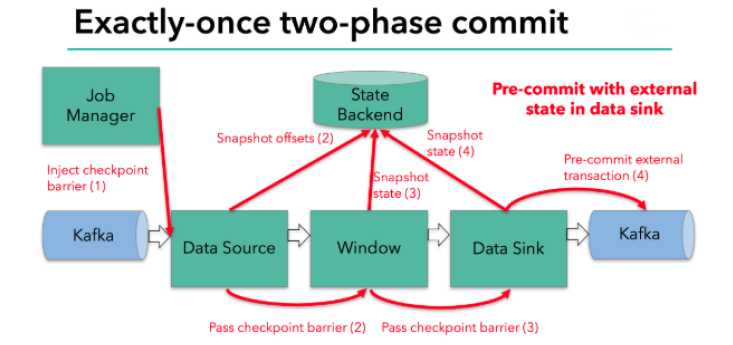
每个内部的transform任务遇到barrier时,都会把状态存到checkpoint里;
sink任务首先把数据写入外部kafka,这些数据都属于预提交的事务;遇到barrier时,把状态保存到状态后端,并开启新的预提交事务(以barrier为界之前的数据属于上一个事务,之后的数据属于下一个新的事务);
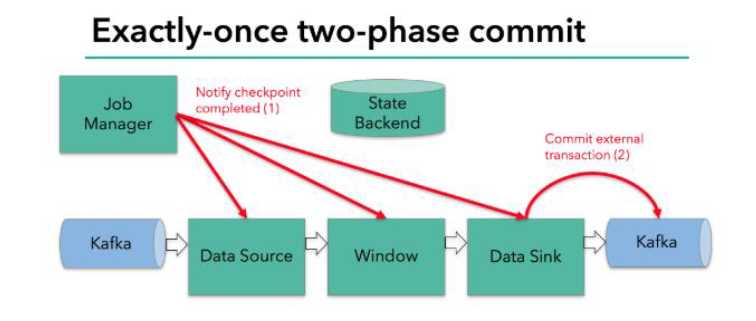
当所有算子任务的快照完成,也就是这次的checkpoint完成时,JobManager会向所有任务发通知,确认这次checkpoint完成;
sink任务收到确认通知,正式提交之前的事务,kafka中未确认数据改完“已确认”;
Exactly-once两阶段提交步骤:
第一条数据来在之后,开启一个kafka的事务(transaction),正常写入kafka分区日志但标记为未提交,这就是“预提交”;
JobManagere触发checkpoint操作,barrier从source开始向下传递,遇到barrier的算子将状态存入状态后端,并通知JobManagere;
sink连接器接收到barrier,保存当前状态,存入checkpoint,通知JobManager并开启下一阶段的事务,用于提交下个检查点的数据;
JobManager收到所有任务的通知,发出确认信息,表示checkpoint完成;
sink任务收到JobManager的确认信息,正式提交这段时间的数据;
外部kafka关闭事务,提交的数据可以正常消费了。
在代码中真正实现flink和kafak的端到端exactly-once语义:
A. 这里需要配置下,因为它默认的是AT_LEAST_ONCE;
B. 对于外部kafka读取的消费者的隔离级别,默认是read_on_commited,如果默认是可以读未提交的数据,就相当于整个一致性还没得到保证(未提交的数据没有最终确认那边就可以读了,相当于那边已经消费数据了,事务就是假的了) 所以需要修改kafka的隔离级别;
C. timeout超时问题,flink和kafka 默认sink是超时1h,而kafak集群中配置的tranctraction事务的默认超时时间是15min,flink-kafak这边的连接器的时间长,这边还在等着做操作 ,kafak那边等checkpoint等的时间太长直接关闭了。所以两边的超时时间最起码前边要比后边的小。
标签:strong 最简 遇到 不提交 传递 job 简单 rod style
原文地址:https://www.cnblogs.com/shengyang17/p/12562269.html