标签:对象 logs 检测 hadoop 建立 ima 通知 内容 nod
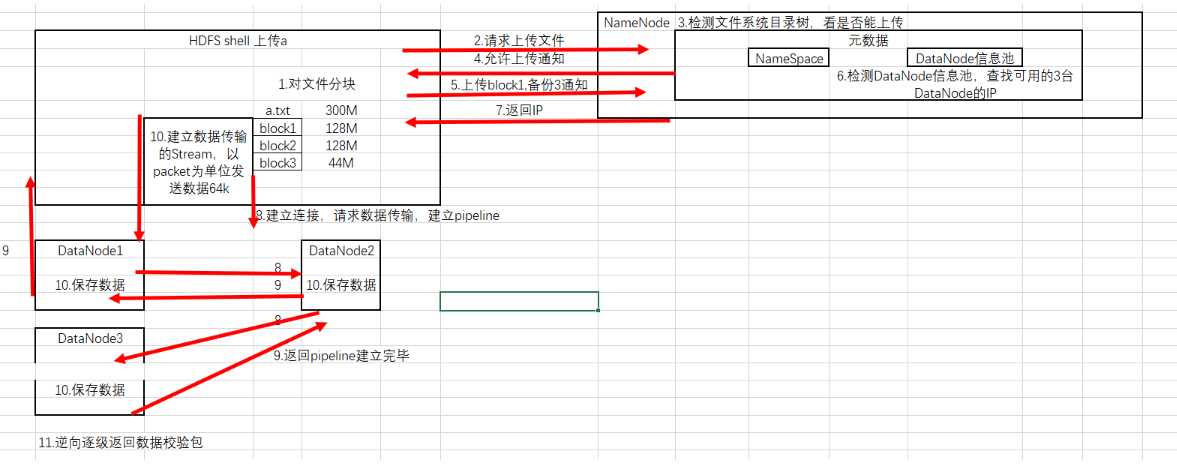
HDFS shell上传文件a.txt,300M
shell向NameNode发送上传文件请求
NameNode检测文件系统目录树,看能否上传
NameNode向shell发送允许上传通知
shell向NameNode发送上传block1,备份为3的通知。
NameNode检测DataNode信息池,查找的3台DataNode的IP,查找的IP有以下机制:
网络拓扑距离最近(经历交换机最少)
如果shell本身就是一个DataNode,本地会备份一份。
相同机架备份一份(关于机架检测,见后文)
不同机架备份一份
NameNode把检测到的IP返回给shell
shell检测最近的IP,比如DataNode1,建立连接请求数据传输,建立pipeline
pipeline是Hadoop用来传输数据的对象,类似流水线的传递。
DataNode1向DataNode2建立pipeline
DataNode2向DataNode3建立pipeline
DataNode3向DataNode2返回pipeline建立成功通知,再逐级返回2-1,1-shell。
shell通过OutputStream,以packet(64K)为单位,向DataNode1发送数据,并逐级下发。
各级DataNode接收到后,存储数据到本地。
DataNode保存数据后,会逆向逐级发送数据校验包,用于验证数据是否传输完成。
传输完成,关闭pipeline,重复5-11。
以下内容是根据该网址内容整理:
https://blog.csdn.net/w182368851/article/details/53729790
https://www.cnblogs.com/zwgblog/p/7096875.html
机架检测的原理其实就是core-site.xml配置文件中配置一个选项:
<property> <name>topology.script.file.name</name> <value>/home/bigdata/apps/hadoop-talkyun/etc/hadoop/topology.sh</value> </property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本.
该脚本接受一个参数,输出一个值。
参数通常为某台DataNode机器的ip地址,而输出的值通常为该ip地址对应的DataNode所在的Rack(机架)。
流程:
NameNode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置。
此时NameNode会根据配置寻找该脚本。
接收到任何DataNode的心跳(heartbeat)时,将该DataNode的ip地址作为参数传给脚本,就能得到每个DataNode的Rack,保存到内存的一个map中,此使就能知道每台机器是否在同一个机架上了。
配置文件简单示例:
#!/usr/bin/python #-*-coding:UTF-8 -*- import sys rack = {"NN01":"rack2", "NN02":"rack3", "DN01":"rack4", "DN02":"rack4", "DN03":"rack1", "DN04":"rack3", "DN05":"rack1", "DN06":"rack4", "DN07":"rack1", "DN08":"rack2", "DN09":"rack1", "DN10":"rack2", "172.16.145.32":"rack2", "172.16.145.33":"rack3", "172.16.145.34":"rack4", "172.16.145.35":"rack4", "172.16.145.36":"rack1", "172.16.145.37":"rack3", "172.16.145.38":"rack1", "172.16.145.39":"rack4", "172.16.145.40":"rack1", "172.16.145.41":"rack2", "172.16.145.42":"rack1", "172.16.145.43":"rack2", } if __name__=="__main__": print "/" + rack.get(sys.argv[1],"rack0")
标签:对象 logs 检测 hadoop 建立 ima 通知 内容 nod
原文地址:https://www.cnblogs.com/renzhongpei/p/12590328.html