标签:nbsp 数据集 pil random 方法 ali alt compile span
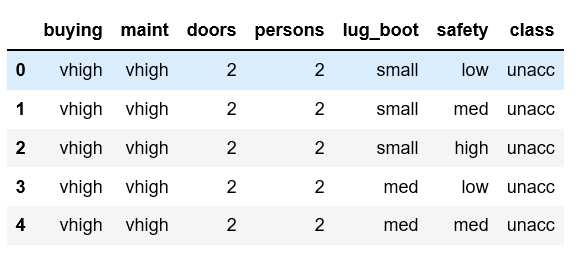
import pandas as pd # 加载数据集 df = pd.read_csv( "http://labfile.oss.aliyuncs.com/courses/1211/car.data", header=None) # 设置列名 df.columns = [‘buying‘, ‘maint‘, ‘doors‘, ‘persons‘, ‘lug_boot‘, ‘safety‘, ‘class‘]
from sklearn.model_selection import train_test_split X = df.iloc[:, :-1] # 特征 y = df[‘class‘] # 目标 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1)
#数据处理,利用one-hot编码
X_train = pd.get_dummies(X_train).values X_test = pd.get_dummies(X_test).values y_train = pd.get_dummies(y_train).values y_test = pd.get_dummies(y_test).values
import tensorflow as tf model = tf.keras.Sequential() # 建立顺序模型 model.add(tf.keras.layers.Dense(units=30, input_dim=21, activation=‘relu‘)) # 隐含层 1 model.add(tf.keras.layers.Dense(units=15, activation=‘relu‘)) # 隐含层 2 model.add(tf.keras.layers.Dense(units=4, activation=‘softmax‘)) # 输出层 #通俗来说,input_length就是输入数据的长度,Input_dim就是数据的维度。比如一条数据内容是: “人人车” , one hot编码后是 [[1 0] [1 0] [0 1]]表示 ,则 batch_size = 3, input_dim = 2. model.summary() # 查看模型结构
# 编译模型,添加优化器,损失函数和评估方法。tf.optimizers.Adam作为优化器,tf.losses.categorical_crossentropy多分类交叉熵 model.compile(optimizer=‘adam‘, loss=‘categorical_crossentropy‘, metrics=[‘accuracy‘]) # 训练模型 model.fit(X_train, y_train, batch_size=64, epochs=20, validation_data=(X_test, y_test))
标签:nbsp 数据集 pil random 方法 ali alt compile span
原文地址:https://www.cnblogs.com/dieyingmanwu/p/12594120.html