标签:引入 互斥 朴素贝叶斯 aliyun 数据 tail 概率论 有监督 big
(1)联合概率
(2)条件概率
在B事件发生的条件下,A事件发生的概率称为条件概率,记为:$ p(A|B)$
(3)全概率公式
对于事件组
则称\(B_1,B_2,...,B_n\)是样本空间\(\Omega\)的一个划分
A为任意事件,则:
(1)先验概率
(2)条件概率
指当已知类别为\(ω_i\)的条件下,看到结果为样本特征为X的概率
\(p(X|\omega_i) =\frac{p(\omega_i,X)}{p(\omega_i)}\)
(3)后验概率
后验概率就是发生结果之后,即知道样本特征X,推测其类别是\(ω_i\)的概率:
\(p(\omega_i|X) =\frac{p(X|\omega_i)p(\omega_i)}{p(X)}\)
(4)贝叶斯公式
当某一特征向量X只为某一类物体所特有时:
\(p(\omega_k|X)=\begin{cases} 1 , k = i\0 , k \not= i \end{cases}\)
当某一特征向量X为不同类物体所特有时,即几种类别中均有可能出现该特征,时会有分错情况
(1) 后验概率
若:\(p(\omega_i|X)=\max_{j=1,2}p(\omega_j|X)\),则:\(X\in \omega_i\)


(2)比较分子
(3)似然比
(4)将似然比转换成负对数形式
(1)证明步骤
当采用最大后验概率分类器时,分类错误的概率为:
\(p(e)=\int_{-\infty}^{+\infty}p(error,x)dx=\int_{-\infty}^{+\infty}p(error|x)p(x)dx\)
而在已知特征X的情况下,出现错误推测分类的概率为:
\(p(error|x)=\sum_{i=1}^cp(\omega_i|x)-\max_{1\leq j \leq c }p(\omega_j|x)\)
当p(w2|x)>p(w1|x)时决策为w2,对观测值x有 p(w1|x)概率的错误率:
\(p(e|x)=\begin{cases} p(x|\omega_1),当p(x|\omega_1)<p(x|\omega_2)\p(x|\omega_2),当p(x|\omega_2)<p(x|\omega_1) \end{cases}\)
设:
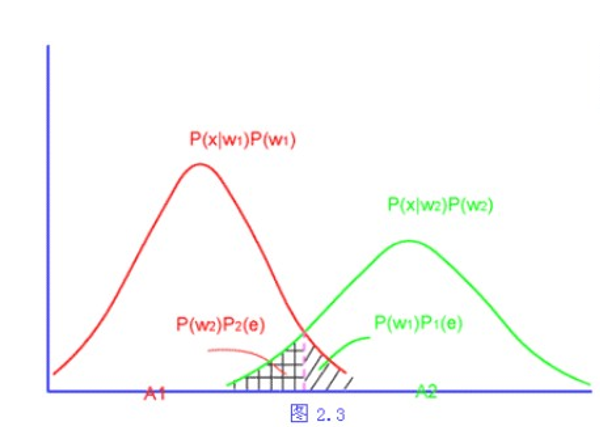
因此平均错误率p(e)可表示成:
\(p(e)=\int_{R_1} p(\omega_2|x)p(x)dx+\int_{R_2}p(\omega_1|x)p(x)dx\)
(1)分类决策边界
分类决策边界:$p(ω_i|x) = p(ω_j|x) $,即出现X特征,使得将该事务分类到两方的概率相同
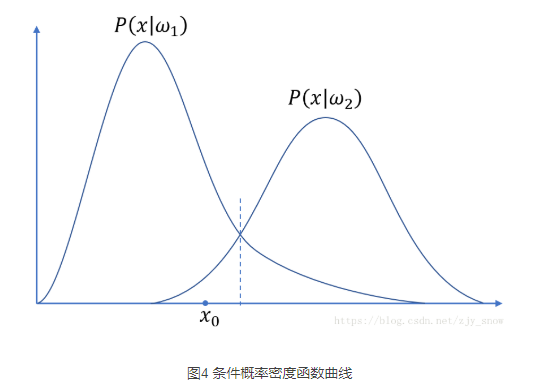
分类决策边界不一定是线性的,也不一定是连续的
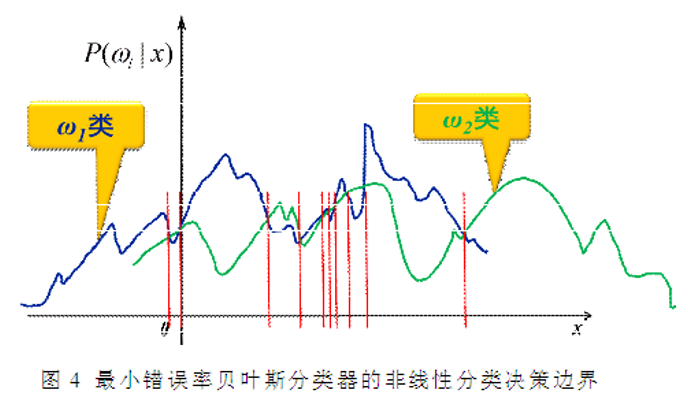
(2)错误率
(1)自然状态
指待识别对象的类别
\(A=\{a_1,a_2,...,a_k\}\)
(2)状态空间
由所有自然状态所组成的空间
\(\Omega=\{\omega_1,\omega_2,...,\omega_c\}\)
(3)决策与决策空间
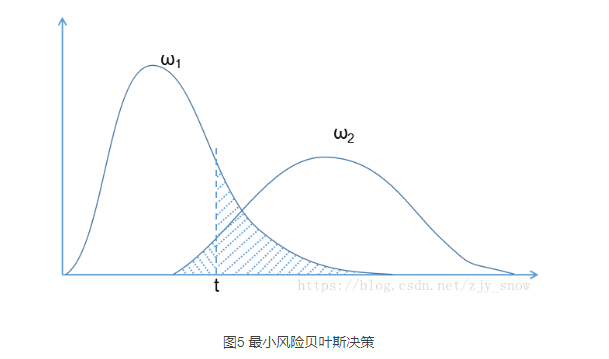
(4)决策风险函数λ(α,ω)
指对于实际状态为\(wj\)的向量\(x\)采取决策\(a_i\)所带来的损失\(\lambda(a_i,\omega_j),i=1,...,k,j=1,...,c\)
也写作:\(\lambda(a_i|\omega_j)\)
(5)期望损失(风险)
在N种可能的标记种,\(λ_{ij}\)是指将\(ω_j\)误分为\(ω_i\)时所产生的损失。基于后验概率:\(P(ω_i|x)\)得到误分为\(C_i\)时所产生的期望损失,这个损失也叫做”风险“,当我们制定一个准则\(h\)使得对于每一个样本\(x\)风险最小时(此时整个样本的总体风险\(R(h*)\)(贝叶斯风险)也达到最小),称h为贝叶斯最优分类器
\(R_i(X)=R(\omega_i|X)=\sum_{j=1}^c\lambda_j^{i}p(\omega_j|X)\)
利用贝叶斯公式计算后验概率:
\(p(\omega_i|X) =\frac{p(\omega_i)p(X|\omega_i)}{p(X)}=\frac{p(\omega_i)p(X|\omega_i)}{\sum_{i=1}^cp(\omega_i)p(X|\omega_i)}\)
利用决策表,计算条件风险:
\(R_i(X)=R(\omega_i|X)=\sum_{j=1}^c\lambda(a_i,\omega_j))p(\omega_j|X)\)
决策:选择风险最小的决策,即:
\(a=\arg\min_{i=1,...,k}R(a_i|X)\)
标签:引入 互斥 朴素贝叶斯 aliyun 数据 tail 概率论 有监督 big
原文地址:https://www.cnblogs.com/nishoushun/p/12600413.html