标签:selector store 文章 wing exists buffer people 测试 load
最近(以及预感接下来的一年)会读很多很多的paper......不如开个帖子记录一下读paper心得
这是HPCA2006的文章,但里面的方法论放到现在也很有借鉴意义。
本文通过分析Bioinformatic workload在Last Level Cache上的性能,发现这种workload中很多cacheline其实都是shared by multiple cores,那么一些对于其他workload适用的策略(比如partitioning LLC into multiple private caches)就不行了。
前面介绍了一下他们的workload(这个就不看了)和simulator(是基于Pin开发的一个插件叫做SimCMPcache,但很可惜没有开源)。
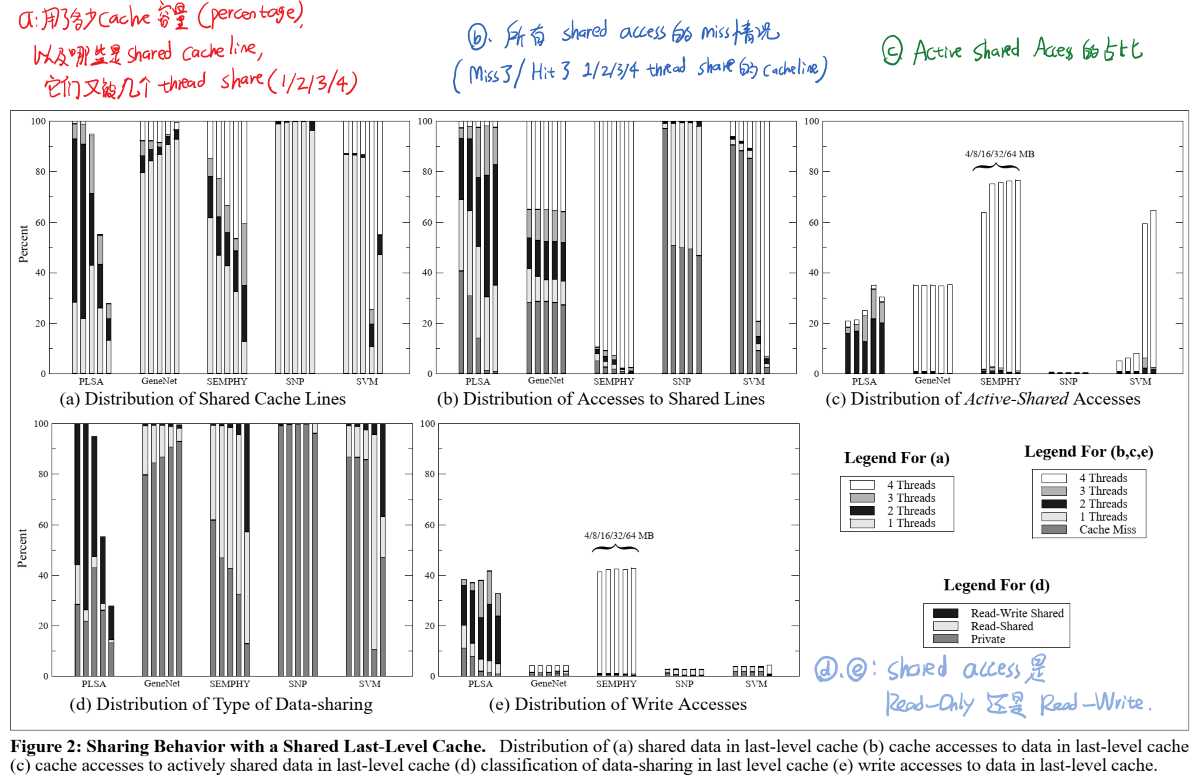
为了分析LLC的使用情况(sharing behavior of parallel workloads),本文定义了如下三种metrics:
接下来就是展示实验结果了。我们先来看Fig2的结果(每个case中的五个柱表示测试了5种cache容量:4M/8M/16M/32M/64M LLC):
When integrating GPU and CPU on the same die of chip, they could share the same Last Level Cache(LLC). Due to much higher number of threads in GPU, GPU may dominate the access to the shared LLC. However, in many scenarios, CPU applications are more sensitive to LLC than GPU applications, while GPU applications can often tolerate relatively higher memory access latency (not really sensiable to LLC). It is because for CPU cores, changes in cache miss rate are a direct indicator of cache sensitivity. While in the GPU core, an increase in cache miss rate does not necessarily result in performance degradation, because the GPU kernel can tolerate memory access latency by context switching between a large number of concurrent active threads. So a new cache replacement policy, called HeLM, is proposed to solve this issue.
Under the HeLM policy, GPU LLC accesses are limited by allowing memory accesses to selectively bypass the LLC, so the cache sensitive CPU application is able to utilize a larger portion of the cache. It is achieved by allowing the GPU memory traffic to selectively bypass the LLC when the GPU cores exhibit sufficient TLP to tolerate memory access latency, or when the GPU application is not sensitive to LLC performance.
The author implemented 3 technologies: 1). Measure the sensitivity of GPU LLC and CPU LLC. 2). Determining Effective TLP Threshold. 3). Using Threshold Selection Algorithm(TSA) to monitors the workload characteristics continuously and re-evaluates the TLP threshold at the end of every sampling period. Then enforce this threshold on all GPU cores.
The author evaluated the performance of HeLM by comparing with DRRIP, MAT, SDBP, and TAP-RRIP, all normalized to LRU. HeLM outperforms all these mechanisms in overall system performance.
The traditional cache LRU mechanism replaces the item at MRU position with the new coming line, which could lead to thrashing problem when a memory-intensive workload whose size is greater than the available cache size. The authors of this paper introduce new mechanism: Dynamic Insertion Policy that can protect cache from thrashing with trial overhead, and improve the average cache hit performance.
1. The authors propose LRU Insertion Policy (LIP), which inserts all incoming lines to the LRU position because of the fact that a long-enough fraction of a workload can lead to a cache hit even though the workload’s size exceeds the available size.
2. Based on LIP, the authors propose the Bimodal Insertion Policy (BIP), which is basically LIP but also implement traditional LRU. It has a parameter e: bimodal throttle parameter that is a very small number, which controls the percentage of incoming lines that be inserted to MRU position.
3. They design experiment to explore how the reduction in L2 MPKI performs with LIP and BIP with e = 1/64, 1/32, 1/16 on 16 different benchmarks. In general, BIP outperforms LIP and the value of e doesn’t affect much of the result. LIP and BIP reduce MPKI by 10% or more for nine benchmarks. The other benchmarks are either LRU-friendly or have knee of MPKI curve is less than cache size.
4. The authors further propose Dynamic Insertion Policy (DIP) which can dynamically make choices from BIP and LRU, which incurs the fewest misses. It introduces MTD be the main tag directory of the cache, ADT-LRU as traditional LRU tag, and ATD-BIP as the BIP tag. PSEL is Policy Selector which is a saturating counter. Using PSEL count for each set needs more hardware resources thus Dynamic Set Sampling (DSS) come to use.
The key idea of DSS is that the cache behavior can be estimated with high probability by sampling. It introduces Set Dueling, which only keeps the MTD and eliminate the need to store separate ATD entries. They use complement-select policy that identify a set as a dedicated for competing or a follower.
5. The experiments show that DIP can reduce MPKI of a 1MB 16-way L2 cache by 21% in average.
The bandwidth of DRAM cache is not only used for data transferring. Some of its bandwidth are consumed by some secondary operations, like cache miss detection, fill on cache miss, and writeback lookup and content update on dirt evictions from the last-level on-chip cache. In order to decrease the bandwidth consumed by these secondary operations, the previous work, Alloy Cache, still consumes 3.8x bandwidth compared to an idealized DRAM cache that does not consume any bandwidth for secondary operations. In this work, the author proposed Bandwidth Efficient Architecture (BEAR), which include 3 components to reduce the bandwidth consumed by miss detection, miss fill, and writeback probes respectively.
The author found that DRAM cache bandwidth bloat is attributed to six di?erent cache operations: Hit Probe, Miss Probe, Miss Fill, Writeback Probe, Writeback Update, and Writeback Fill. And only the Hit Probe leads useful bandwidth to service the LLC miss request. So the author concentrated on 3 sources of bandwidth bloat:
Finally, the author integrated these components together, and proposed BEAR. The experiments show that BEAR improved performance over the Alloy Cache by 10.1%, and reduced the bandwidth consumption of DRAM cache by 32%.
Tiered Memory System includes the following 2 components: 3D-DRAM with high bandwidth, and commodity-DRAM with high capacity. The previous works try to maximize the usage of 3D-DRAM bandwidth, but actually, the bandwidth of commodity-DRAM is the significant fraction of the overall system bandwidth. So they inefficiently utilized the total bandwidth of the tiered system.
For a tiered-memory system in which the Far Memory (DDR-based DRAM) accounts for a significant fraction of the overall bandwidth, distributing memory accesses to both memories has great ability to improve performance. In order to solve this issue, the author proposed Bandwidth-Aware Tiered-Memory Management (BATMAN), a runtime mechanism that manages the memory accesses distribution in proportion to the bandwidth ratio of the Near Memory and the Far Memory. It could explicitly control the data management. The main idea of BATMAN is that when 3D-DRAM memory access is greater than a threshold, it will move data from 3D-DRAM to commodity-DRAM.
The evaluation shows that BATMAN could improve performance by 10% and energy-delay product by 13%. Also, it incurs only an eight-byte hardware overhead and requires negligible software modification.
Paper Reading_Computer Architecture
标签:selector store 文章 wing exists buffer people 测试 load
原文地址:https://www.cnblogs.com/pdev/p/11656179.html