标签:system ESS count() less extend containe class private 接口
依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
yml配置
spring: data: elasticsearch: cluster-name: elasticsearch cluster-nodes: 192.168.56.101:9300
实体类
public class Item { Long id; String title; //标题 String category;// 分类 String brand; // 品牌 Double price; // 价格 String images; // 图片地址 }
映射
Spring Data通过注解来声明字段的映射属性,有下面的三个注解:
@Document 作用在类,标记实体类为文档对象,一般有四个属性
indexName:对应索引库名称
type:对应在索引库中的类型
shards:分片数量,默认5
replicas:副本数量,默认1
@Id 作用在成员变量,标记一个字段作为id主键
@Field 作用在成员变量,标记为文档的字段,并指定字段映射属性:
type:字段类型,取值是枚举:FieldType
index:是否索引,布尔类型,默认是true
store:是否存储,布尔类型,默认是false
analyzer:分词器名称:ik_max_word
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0) public class Item { @Id private Long id; @Field(type = FieldType.Text, analyzer = "ik_max_word") private String title; //标题 @Field(type = FieldType.Keyword) private String category;// 分类 @Field(type = FieldType.Keyword) private String brand; // 品牌 @Field(type = FieldType.Double) private Double price; // 价格 @Field(index = false, type = FieldType.Keyword) private String images; // 图片地址 }
@RunWith(SpringRunner.class) @SpringBootTest(classes = ItcastElasticsearchApplication.class) public class IndexTest { @Autowired private ElasticsearchTemplate elasticsearchTemplate; @Test public void testCreate(){ // 创建索引,会根据Item类的@Document注解信息来创建 elasticsearchTemplate.createIndex(Item.class); // 配置映射,会根据Item类中的id、Field等字段来自动完成映射 elasticsearchTemplate.putMapping(Item.class); } }
结果
GET /item { "item": { "aliases": {}, "mappings": { "docs": { "properties": { "brand": { "type": "keyword" }, "category": { "type": "keyword" }, "images": { "type": "keyword", "index": false }, "price": { "type": "double" }, "title": { "type": "text", "analyzer": "ik_max_word" } } } }, "settings": { "index": { "refresh_interval": "1s", "number_of_shards": "1", "provided_name": "item", "creation_date": "1525405022589", "store": { "type": "fs" }, "number_of_replicas": "0", "uuid": "4sE9SAw3Sqq1aAPz5F6OEg", "version": { "created": "6020499" } } } } }
@Test public void deleteIndex() { elasticsearchTemplate.deleteIndex("item"); }
Spring Data 的强大之处,就在于你不用写任何DAO处理,自动根据方法名或类的信息进行CRUD操作。只要你定义一个接口,然后继承Repository提供的一些子接口,就能具备各种基本的CRUD功能。
我们只需要定义接口,然后继承它就OK了。
public interface ItemRepository extends ElasticsearchRepository<Item,Long> { }
来看下Repository的继承关系:
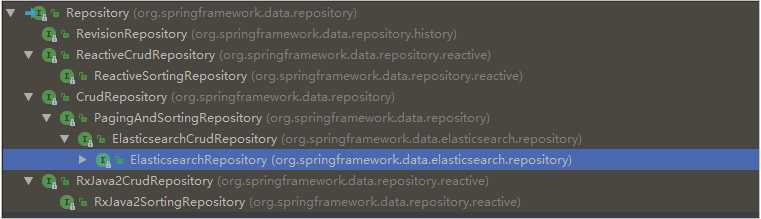
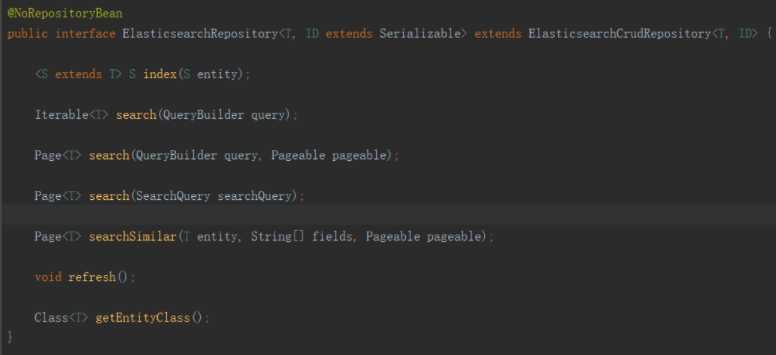
我们看到有一个ElasticsearchRepository接口:
@Autowired private ItemRepository itemRepository; @Test public void index() { Item item = new Item(1L, "小米手机7", " 手机", "小米", 3499.00, "http://image.leyou.com/13123.jpg"); itemRepository.save(item); }
@Test public void indexList() { List<Item> list = new ArrayList<>(); list.add(new Item(2L, "坚果手机R1", " 手机", "锤子", 3699.00, "http://image.leyou.com/123.jpg")); list.add(new Item(3L, "华为META10", " 手机", "华为", 4499.00, "http://image.leyou.com/3.jpg")); // 接收对象集合,实现批量新增 itemRepository.saveAll(list); }
@Test public void testQuery(){ Optional<Item> optional = this.itemRepository.findById(1l); System.out.println(optional.get()); } @Test public void testFind(){ // 查询全部,并按照价格降序排序 Iterable<Item> items = this.itemRepository.findAll(Sort.by(Sort.Direction.DESC, "price")); items.forEach(item-> System.out.println(item)); }
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
当然,方法名称要符合一定的约定:
| Keyword | Sample | Elasticsearch Query String |
| --------------------- | ------------------------------------------ | ------------------------------------------------------------ |
| `And` | `findByNameAndPrice` | `{"bool" : {"must" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}}` |
| `Or` | `findByNameOrPrice` | `{"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"price" : "?"}} ]}}` |
| `Is` | `findByName` | `{"bool" : {"must" : {"field" : {"name" : "?"}}}}` |
| `Not` | `findByNameNot` | `{"bool" : {"must_not" : {"field" : {"name" : "?"}}}}` |
| `Between` | `findByPriceBetween` | `{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : ?,"include_lower" : true,"include_upper" : true}}}}}` |
| `LessThanEqual` | `findByPriceLessThan` | `{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}}` |
| `GreaterThanEqual` | `findByPriceGreaterThan` | `{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}}` |
| `Before` | `findByPriceBefore` | `{"bool" : {"must" : {"range" : {"price" : {"from" : null,"to" : ?,"include_lower" : true,"include_upper" : true}}}}}` |
| `After` | `findByPriceAfter` | `{"bool" : {"must" : {"range" : {"price" : {"from" : ?,"to" : null,"include_lower" : true,"include_upper" : true}}}}}` |
| `Like` | `findByNameLike` | `{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}}` |
| `StartingWith` | `findByNameStartingWith` | `{"bool" : {"must" : {"field" : {"name" : {"query" : "?*","analyze_wildcard" : true}}}}}` |
| `EndingWith` | `findByNameEndingWith` | `{"bool" : {"must" : {"field" : {"name" : {"query" : "*?","analyze_wildcard" : true}}}}}` |
| `Contains/Containing` | `findByNameContaining` | `{"bool" : {"must" : {"field" : {"name" : {"query" : "**?**","analyze_wildcard" : true}}}}}` |
| `In` | `findByNameIn(Collection<String>names)` | `{"bool" : {"must" : {"bool" : {"should" : [ {"field" : {"name" : "?"}}, {"field" : {"name" : "?"}} ]}}}}` |
| `NotIn` | `findByNameNotIn(Collection<String>names)` | `{"bool" : {"must_not" : {"bool" : {"should" : {"field" : {"name" : "?"}}}}}}` |
| `Near` | `findByStoreNear` | `Not Supported Yet !` |
| `True` | `findByAvailableTrue` | `{"bool" : {"must" : {"field" : {"available" : true}}}}` |
| `False` | `findByAvailableFalse` | `{"bool" : {"must" : {"field" : {"available" : false}}}}` |
| `OrderBy` | `findByAvailableTrueOrderByNameDesc` | `{"sort" : [{ "name" : {"order" : "desc"} }],"bool" : {"must" : {"field" : {"available" : true}}}}` |
我们来按照价格区间查询,定义这样的一个方法:
public interface ItemRepository extends ElasticsearchRepository<Item,Long> { /** * 根据价格区间查询 * @param price1 * @param price2 * @return */ List<Item> findByPriceBetween(double price1, double price2); }
@Test public void queryByPriceBetween(){ List<Item> list = this.itemRepository.findByPriceBetween(2000.00, 3500.00); for (Item item : list) { System.out.println("item = " + item); } }
虽然基本查询和自定义方法已经很强大了,但是如果是复杂查询(模糊、通配符、词条查询等)就显得力不从心了。此时,我们只能使用原生查询。
@Test public void testQuery(){ // 词条查询 MatchQueryBuilder queryBuilder = QueryBuilders.matchQuery("title", "小米"); // 执行查询 Iterable<Item> items = this.itemRepository.search(queryBuilder); items.forEach(System.out::println); }
Repository的search方法需要QueryBuilder参数,elasticSearch为我们提供了一个对象QueryBuilders:
QueryBuilders提供了大量的静态方法,用于生成各种不同类型的查询对象,例如:词条、模糊、通配符等QueryBuilder对象
先来看最基本的match query:
@Test public void testNativeQuery(){ // 构建查询条件 NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 添加基本的分词查询 queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米")); // 执行搜索,获取结果 Page<Item> items = this.itemRepository.search(queryBuilder.build()); // 打印总条数 System.out.println(items.getTotalElements()); // 打印总页数 System.out.println(items.getTotalPages()); items.forEach(System.out::println); }
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
Page<item>:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
totalElements:总条数
totalPages:总页数
Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
其它属性:
@Test public void testNativeQuery(){ // 构建查询条件 NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 添加基本的分词查询 queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机")); // 初始化分页参数 int page = 0; int size = 3; // 设置分页参数 queryBuilder.withPageable(PageRequest.of(page, size)); // 执行搜索,获取结果 Page<Item> items = this.itemRepository.search(queryBuilder.build()); // 打印总条数 System.out.println(items.getTotalElements()); // 打印总页数 System.out.println(items.getTotalPages()); // 每页大小 System.out.println(items.getSize()); // 当前页 System.out.println(items.getNumber()); items.forEach(System.out::println); }
@Test public void testSort(){ // 构建查询条件 NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 添加基本的分词查询 queryBuilder.withQuery(QueryBuilders.termQuery("category", "手机")); // 排序 queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC)); // 执行搜索,获取结果 Page<Item> items = this.itemRepository.search(queryBuilder.build()); // 打印总条数 System.out.println(items.getTotalElements()); items.forEach(System.out::println); }
@Test public void testAgg(){ NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 不查询任何结果 queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); // 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand queryBuilder.addAggregation( AggregationBuilders.terms("brands").field("brand")); // 2、查询,需要把结果强转为AggregatedPage类型 AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build()); // 3、解析 // 3.1、从结果中取出名为brands的那个聚合, // 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型 StringTerms agg = (StringTerms) aggPage.getAggregation("brands"); // 3.2、获取桶 List<StringTerms.Bucket> buckets = agg.getBuckets(); // 3.3、遍历 for (StringTerms.Bucket bucket : buckets) { // 3.4、获取桶中的key,即品牌名称 System.out.println(bucket.getKeyAsString()); // 3.5、获取桶中的文档数量 System.out.println(bucket.getDocCount()); } }
结果

关键API:
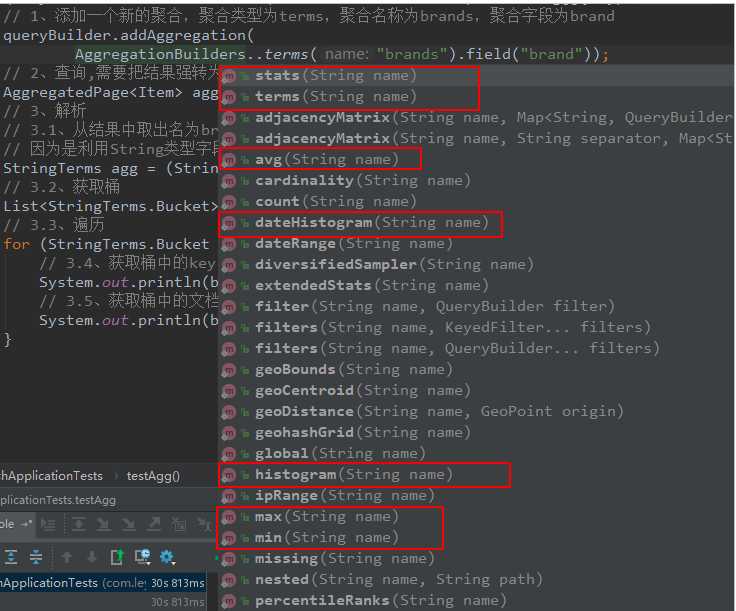
AggregationBuilders:聚合的构建工厂类。所有聚合都由这个类来构建,看看他的静态方法:
AggregatedPage
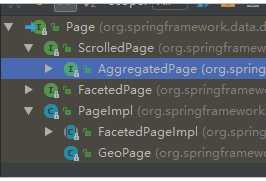
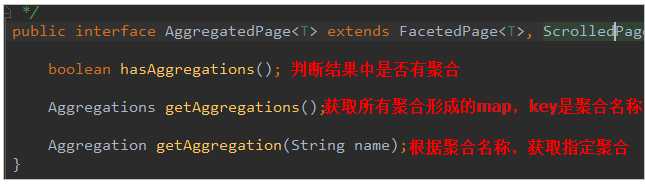
而返回的结果都是Aggregation类型对象,不过根据字段类型不同,又有不同的子类表示
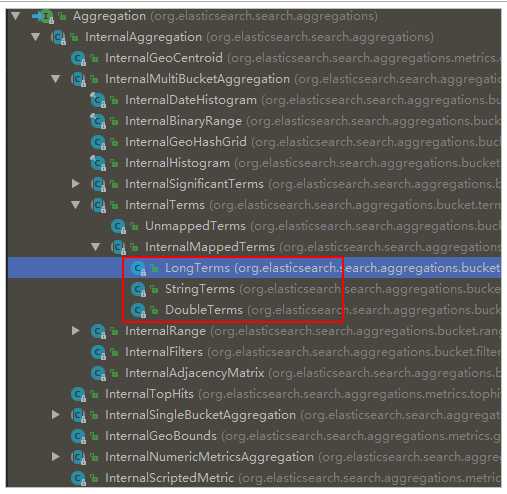
我们看下页面的查询的JSON结果与Java类的对照关系:
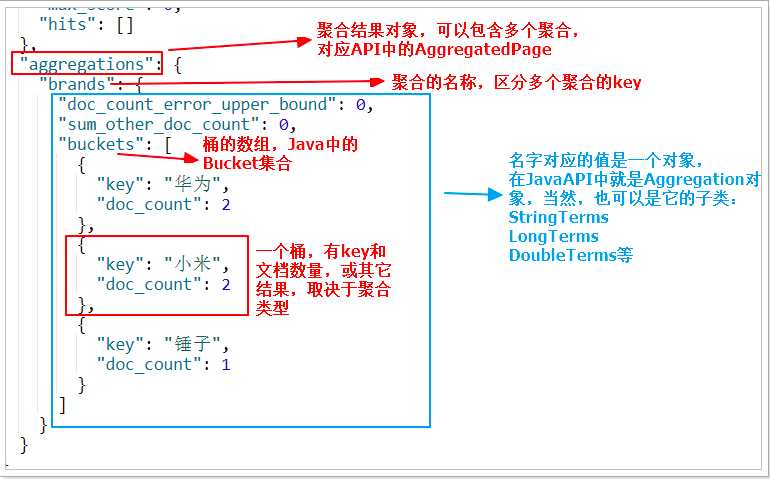
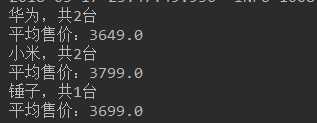
@Test public void testSubAgg(){ NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder(); // 不查询任何结果 queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{""}, null)); // 1、添加一个新的聚合,聚合类型为terms,聚合名称为brands,聚合字段为brand queryBuilder.addAggregation( AggregationBuilders.terms("brands").field("brand") .subAggregation(AggregationBuilders.avg("priceAvg").field("price")) // 在品牌聚合桶内进行嵌套聚合,求平均值 ); // 2、查询,需要把结果强转为AggregatedPage类型 AggregatedPage<Item> aggPage = (AggregatedPage<Item>) this.itemRepository.search(queryBuilder.build()); // 3、解析 // 3.1、从结果中取出名为brands的那个聚合, // 因为是利用String类型字段来进行的term聚合,所以结果要强转为StringTerm类型 StringTerms agg = (StringTerms) aggPage.getAggregation("brands"); // 3.2、获取桶 List<StringTerms.Bucket> buckets = agg.getBuckets(); // 3.3、遍历 for (StringTerms.Bucket bucket : buckets) { // 3.4、获取桶中的key,即品牌名称 3.5、获取桶中的文档数量 System.out.println(bucket.getKeyAsString() + ",共" + bucket.getDocCount() + "台"); // 3.6.获取子聚合结果: InternalAvg avg = (InternalAvg) bucket.getAggregations().asMap().get("priceAvg"); System.out.println("平均售价:" + avg.getValue()); } }
结果
标签:system ESS count() less extend containe class private 接口
原文地址:https://www.cnblogs.com/qin1993/p/12649974.html