标签:sea 调整 输入 部署 als 一个 ota sha 多少
ES 为什么要集群
Cluster 集群
Node 节点
Node节点组合
分片
每个索引有一个或多个分片,每个分片存储不同的数据。分片可分为主分片(primary shard)和复制分片(replica shard)。复制分片是主分片的拷贝。默认每个主分片有一个复制分片,一个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个节点上。
搭建步骤
第一个 yml 文件

#集群名称 cluster.name: my-application #节点名称 node.name: node-1 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9200 #内部节点之间沟通端口 transport.tcp.port: 9300 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
第二个 yml 文件
#集群名称 cluster.name: my-application #节点名称 node.name: node-2 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9201 #内部节点之间沟通端口 transport.tcp.port: 9400 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
第三个 yml 文件
#集群名称 cluster.name: my-application #节点名称 node.name: node-3 #是不是有资格主节点 node.master: true #是否存储数据 node.data: true #最大集群节点数 node.max_local_storage_nodes: 3 #网关地址 network.host: 0.0.0.0 #端口 http.port: 9202 #内部节点之间沟通端口 transport.tcp.port: 9500 #es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服务后可以被选为主节点 discovery.seed_hosts: ["localhost:9300","localhost:9400","localhost:9500"] #es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选举master cluster.initial_master_nodes: ["node-1", "node-2","node-3"] #数据和存储路径 #path.data: /Users/louis.chen/Documents/study/search/storage/a/data #path.logs: /Users/louis.chen/Documents/study/search/storage/a/logs
kibana

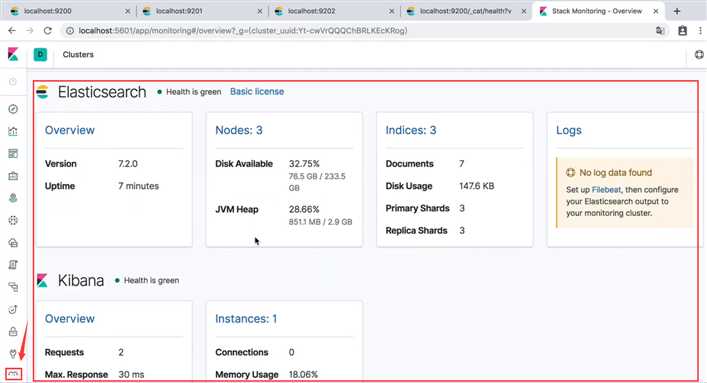
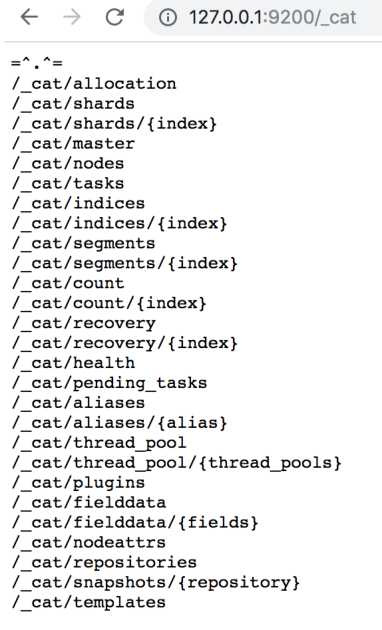
http://127.0.0.1:9200/_cat/health?v

http://127.0.0.1:9200/_cat/indices?v

http://127.0.0.1:9200/_cat/allocation?v

http://127.0.0.1:9200/_cat/nodes?v

标签:sea 调整 输入 部署 als 一个 ota sha 多少
原文地址:https://www.cnblogs.com/jwen1994/p/12649682.html
