标签:背英语单词 导致 input 孙悟空 span 学习 传递 神经元 部分
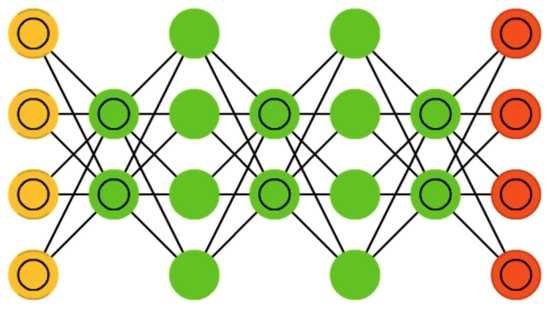
2006年,“神经网络之父”Geoffrey Hinton祭出神器深度信念网络,一举解决了深层神经网络的训练问题,推动了深度学习的快速发展。
深度信念网络(Deep Belief Nets),是一种概率生成模型,能够建立输入数据和输出类别的联合概率分布。
深度信念网络通过采用逐层训练的方式,解决了深层次神经网络的优化问题,通过逐层训练为整个网络赋予了较好的初始权值,使得网络只要经过微调就可以达到最优解。
深度信念网络的每个隐藏层都扮演着双重角色:它既作为之前神经元的隐藏层,也作为之后神经元的可见层。
在逐层训练的时候起到最重要作用的是“受限玻尔兹曼机”
结构上看,深度信念网络可以看成受限玻尔兹曼机组成的整体
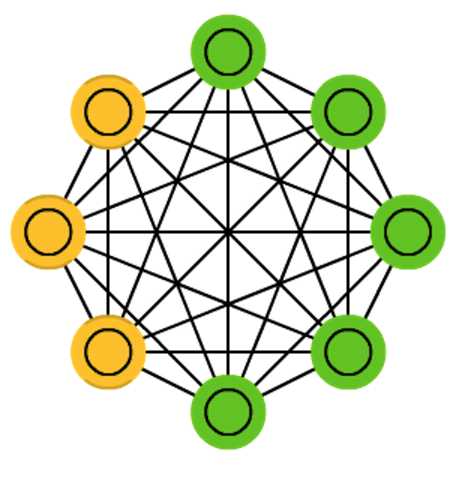
玻尔兹曼机,(Boltzmann Machines,简称BM),1986年由大神Hinton提出,是一种根植于统计力学的随机神经网络,这种网络中神经元只有两种状态(未激活、激活),用二进制0、1表示,状态的取值根据概率统计法则决定。
由于这种概率统计法则的表达形式与著名统计力学家L.E.Boltzmann提出的玻尔兹曼分布类似,故将这种网络取名为“玻尔兹曼机”。
在物理学上,玻尔兹曼分布是描述理想气体在受保守外力的作用时,处于热平衡态下的气体分子按能量的分布规律。
在统计学习中,如果我们将需要学习的模型看成高温物体,将学习的过程看成一个降温达到热平衡的过程。能量收敛到最小后,热平衡趋于稳定,也就是说,在能量最少的时候,网络最稳定,此时网络最优。
玻尔兹曼机(BM)可以用在监督学习和无监督学习中。
在无监督学习中,隐变量可以看做是可见变量的内部特征表示,能够学习数据中复杂的规则。玻尔兹曼机代价是训练时间很长很长很长。
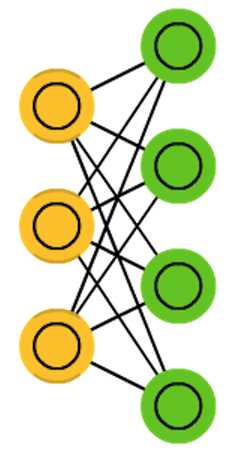
受限玻尔兹曼机(Restricted Boltzmann Machines,简称RBM)
将“玻尔兹曼机”(BM)的层内连接去掉,对连接进行限制,就变成了“受限玻尔兹曼机”(RBM)
一个两层的神经网络,一个可见层和一个隐藏层。
可见层接收数据,隐藏层处理数据,两层以全连接的方式相连,同层之前不相连。
受限玻尔兹曼机需要将输出结果反馈给可见层,通过让重构误差在可见层和隐藏层之间循环往复地传播,从而重构出误差最小化的一组权重系数。
传统的反向传播方法应用于深度结构在原则上是可行的,可实际操作中却无法解决梯度弥散的问题
梯度弥散(gradient vanishing),当误差反向传播时,传播的距离越远,梯度值就变得越小,参数更新的也就越慢。
这会导致在输出层附近,隐藏层的参数已经收敛;而在输入层附近,隐藏层的参数几乎没有变化,还是随机选择的初始值。
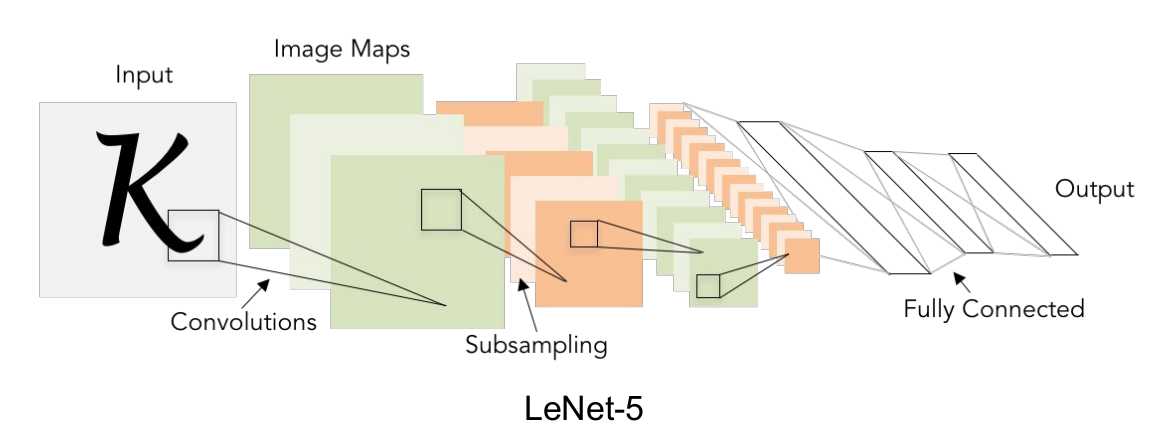
卷积神经网络(convolutional neural network)指至少某一导中用了卷积运算(convolution)来代替矩阵乘法的神经网络。
卷积是对两个函数进行的一种数学运算,我们称\((f*g)(n)\)为f,g的卷积
我们令\(x=τ\),\(y=n-τ\),那么\(x+y=n\),相当于下面的直线
如果遍历这些直线,就像毛巾卷起来一样,顾名思义“卷积”

在卷积网络中,卷积本质就是以核函数g作为权重系数,对输入函数f进行加权求和的过程。
其实把二元函数\(U(x,y) = f(x)g(y)\)卷成一元函数\(V(t)\),俗称降维打击
\(V(t)=\int_{x+y=t}U(x,y)d_x\),函数 f 和 g 应该地位平等,或者说变量 x 和 y 应该地位平等,一种可取的办法就是沿直线 x+y = t 卷起来;

求两枚骰子点数加起来为4的概率,这正是卷积的应用场景。
两枚骰子加起来为4的概率为:\(f(1)g(3)+f(2)g(2)+f(3)g(1)\)
标准形式是:\((f*g)(4)=\sum_{m=1}^3f(4-m)g(m)\)

机器不断的生产馒头,假设馒头生产速度是f(t),
那么一天生产出来的馒头总量为
\(\int_{0 }^{24}f(t)dt\)
生产出来后会逐渐腐败,腐败函数为g(t),比如10个馒头,24小时会腐败
\(10*g(t)\)
一天生产出来的馒头就是
\(\int_{0 }^{24}f(t)g(24-t)dt\)

卷积看做做菜,输入函数是原料,核函数是菜谱,对于同一输入函数鲤鱼来说
假设一幅图有噪点,要将它进行平滑处理,可以把图像转为一个矩阵
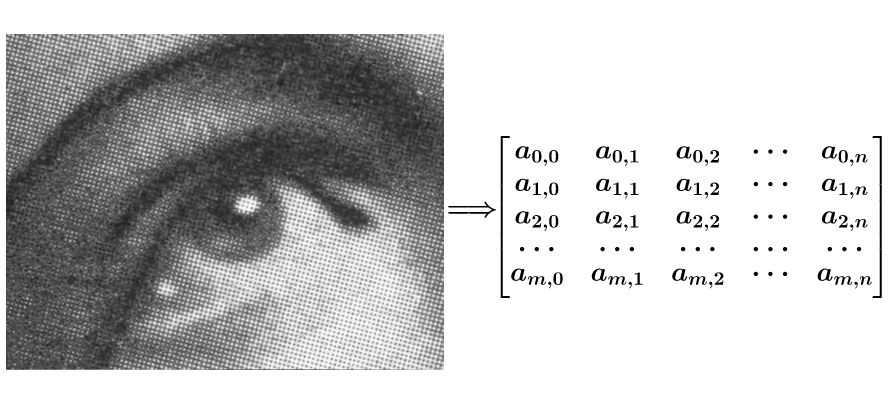
如果要平滑\(a_{1,1}\)点,就把\(a_{1,1}\)点附近的组成矩阵\(f\),和\(g\)进行卷积运算,再填充回去
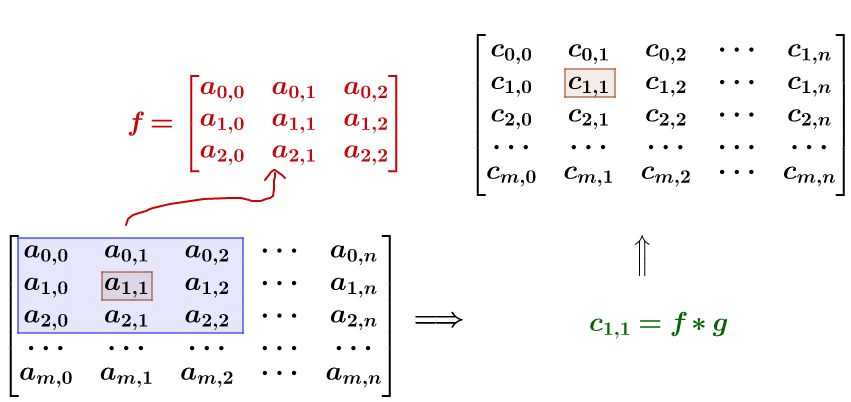
\(f\)和\(g\)的计算如下,其实就是以相反的方向进行计算,像卷毛巾一样

计算\(c_{1,1}\)写成公式为\((f*g)(1,1)=\sum_{k=0}^2\sum_{h=0}^2f(h,k)g(1-h,1-k)\)
具体参考 :
卷积运算的特性决定了神经网络适用于处理具有网络状结构的数据。
典型的网络型数据就是数字图像,无论是灰度还是彩色图像,都是定义在二维像素网络上的一组标题或向量。
卷积神经网络广泛地应用于图像与文本识别之中,并逐渐扩展到自然语言处理等其他领域。
当输入图像被送入卷积神经网络后,先后要循环通过卷积层、激活层和池化层,最后从全连接层输出分类结果。
在卷积神经网络的训练里,待训练的参数是卷积核。
卷积核:也就是用来做卷积的核函数。
卷积神经网络的作用是逐层提取输入对象的特征,训练采用的也是反向传播的方法,参数的不断更新能够提升图像特征提取的精度
GAN(Generative Adversarial Network)是由Goodfellow等人于2014年设计的生成模型,受博弈论中的零和博弈启发,将生成问题视作生成器和判别器这两个网络的对抗和博弈。
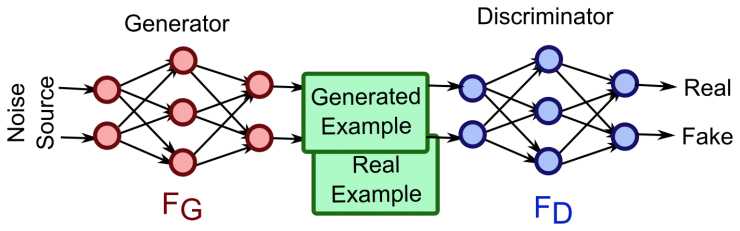
该方法由是由Goodfellow等人于2014年提出,生成对抗网络由一个生成器与一个判别器组成,
生成网器从潜在空间中随机取样作为输入,其输出结果需要尽量模仿训练集中的真实样本。
判别器的输入为真实样本或生成器的输出,其目的是将生成器的输出从真实样本中尽可能分辨出来。
GAN主要优点是超越了传统神经网络分类和特征提取的功能,能够按照真实数据的特点生成新的数据。
两个网络在对抗中进步,在进步后继续对抗,由生成式网络得的数据也就越来越完美,逼近真实数据,从而可以生成想要得到的数据(图片、序列、视频等)。
生成器从给定噪声中(一般是指均匀分布或者正态分布)产生合成数据。试图产生更接近真实的数据。
生成器像是白骨精,想方设法从随机噪声中模拟真实数据样本的潜在分布,以生成以假乱真的数据样本

判别器分辨生成器的的输出和真实数据。试图更完美地分辨真实数据与生成数据。
判别器是孙悟空,用火眼金睛来判断是人畜无害的真实数据还是生成器假扮的伪装者

生成对抗网络*可以看成是深度学习的一次突破
生成器和判别器都可以采用深度神经网络实现,建立数据的生成模型,使生成器尽可能精确你有没出数据样本的分布,从学习方式上对抗性学习属于无监督学习,
网络训练可以等效为目录函数的极大-极小问题
传统生成模型定义了模型的分布,进而求解参数。比如在已知数据满足正态分布的前提下,生成模型会通过极大似然估计等方法根据样本来求解正态的均值和方差。
生成对抗网络摆脱了对模型分布的依赖,也不限制生成的维度,大大拓宽了生成数据样本的范围,还能融合不同的损失函数,增加了设计的自由度。
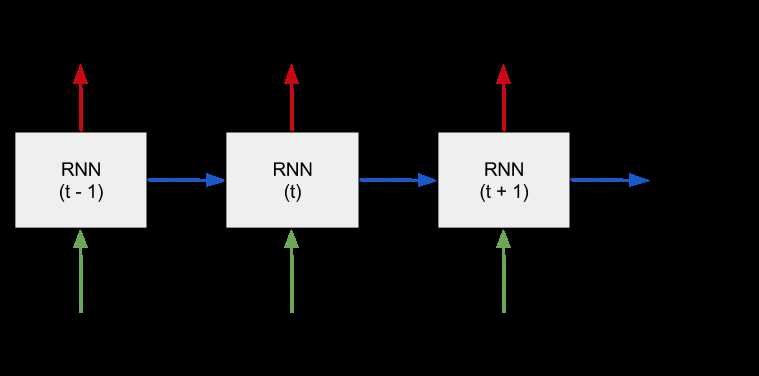
循环神经网络(Recurrent Neural Network),也可以表示递归神经网络(Recursive Neural Network)。循环神经网络可以看成是递归神经网络的特例,递归神经网络可以看成是循环神经网络的推广。
卷积神经网络具有空间上的参数共享的特性,可以让同样的核函数应用在图像的不同区域。
把参数共享调整到时间维度上,让神经网络使用相同权重系数来处理具有先后顺序的数据,得到的就是循环神经网络。
时间
循环神经网络引入了”时间“的维度,适用于处理时间序列类型的数据。
循环神经网络就是将长度不定的输入分割为等长的小块,再使用相同的权重系统进行处理,从而实现对变长输入的计算与处理。
比方说妈妈在厨房里突然喊你:“菜炒好了,赶紧来......”,即使后面的话没有听清楚,也能猜到十有八九是让你赶紧吃饭。
记忆
循环神经网络t时刻的输出取决于当前时刻的输入,也取决于网络前一时刻t-1甚至更早的输出。
从这个意义上来讲,循环神经网络引入引入了反馈机制,因而具有了记忆功能。记忆功能使循环神经网络能够提取来自序列自身的信息,
输入序列的内部信息存储在神经网络的隐藏层中,并随着时间的推移在隐藏层中流转。循环网络的记忆特性可以用公式表示为
\(h_t=f(Wx_t+Uh_{t-1})\)
解释:将时刻的输入\(x_t\)的加权结果和时刻\(t-1\)的隐藏层状态\(h_{t-1}\)的加权结果共同作为传递函数
的输入,得到的是隐藏层在时刻\(t\)的输出\(h_t\)。
\(W\)表示从输入到状态的权重矩阵,\(U\)表示从状态到状态的转移矩阵。
对循环神经网络的训练就是根据输出结果和真实结果之间的误差不断调整参数\(W\)和\(U\),直到达到预设要求的过程,训练方法也是基于梯度的反向传播算法。
前馈神经网络某种程序上也具有记忆特性,只要神经网络参数经过最优化,优化的参数就会包含以往数据的踪迹,但是优化的记忆只局限于训练数据集上,当训练的醋应用到新的测试数据集上时,其参数并不会根据测试数据的表现做出进一步调整。
比如有一部电视剧,在第三集的时候才出现的人物,现在让预测一下在第三集中出现的人物名字,你用前面两集的内容是预测不出来的,所以你需要用到第四,第五集的内容来预测第三集的内容,这就是双向RNN的想法
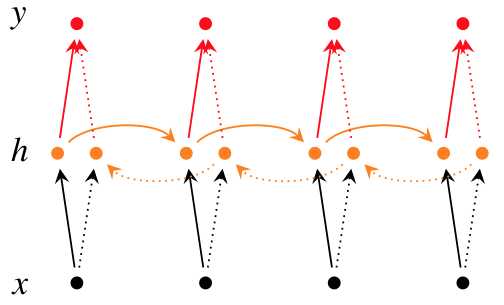
如果想让循环神经网络利用来自未来的信息,就要让当前的状态和以后时刻的状态建立直联系,就是双向循环神经网络。
双向循环网络包括正向计算和反向计算两个环节
将深度结构引入循环神经网络就可以得到深度循环网络。
比如你学习英语的时候,背英语单词一定不会就看一次就记住了所有要考的单词,一般是带着先前几次背过的单词,然后选择那些背过但不熟的内容或者没背过的单词来背
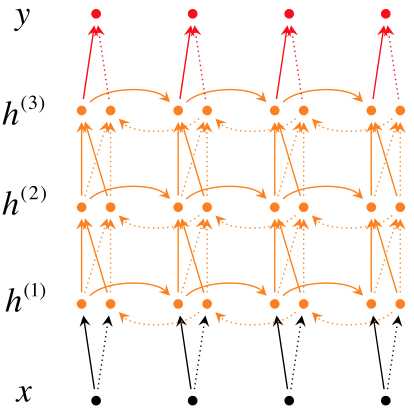
深层双向RNN 与双向RNN相比,多了几个隐藏层,因为他的想法是很多信息记一次记不下来,
深层双向RNN就是基于这么一个想法,每个隐藏层状态\(h_t^i\)既取决于同一时刻前一隐藏层的状态\(h_t^{i-1}\),也取决于同一隐藏层的状态h_{t-1}^{i}$
深度结构的作用在于建立更清晰的表示。用“完形填空”来说,需要根据上下文,来选择合适的词语。有些填空只需要根据它所在的句子便可以推断出来,这对应着单个隐藏层在时间维度上的依赖性;有些填空则可能要通读整段或全文才能确定,这对应了时间维度和空间维度共有的依赖性。
递归神经网络能够处理具有层次化结构的数据,可以看成循环网络的推广
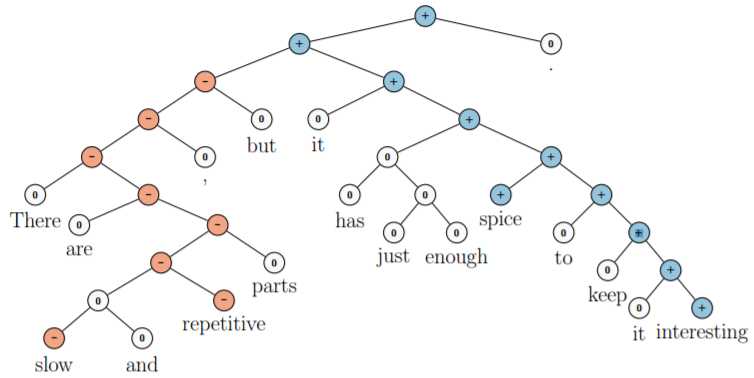
循环神经网络特点是在时间维度上共享参数,从而展开处理序列,如果展开成树状态结构,用到的就是递归神经网络。递归神经网络首先将输入数据转化为某种拓扑结构,再在相同的结构上递归使用相同的权重系数,通过遍历方式得到结构化的预测。
例如,“两个大学的老师”有歧义,如果单纯拆分为词序列无法消除歧义。
递归神经网络通过树状结构将一个完整的句子打散为若干分量的组合,生成的向量不是树结构的根节点。

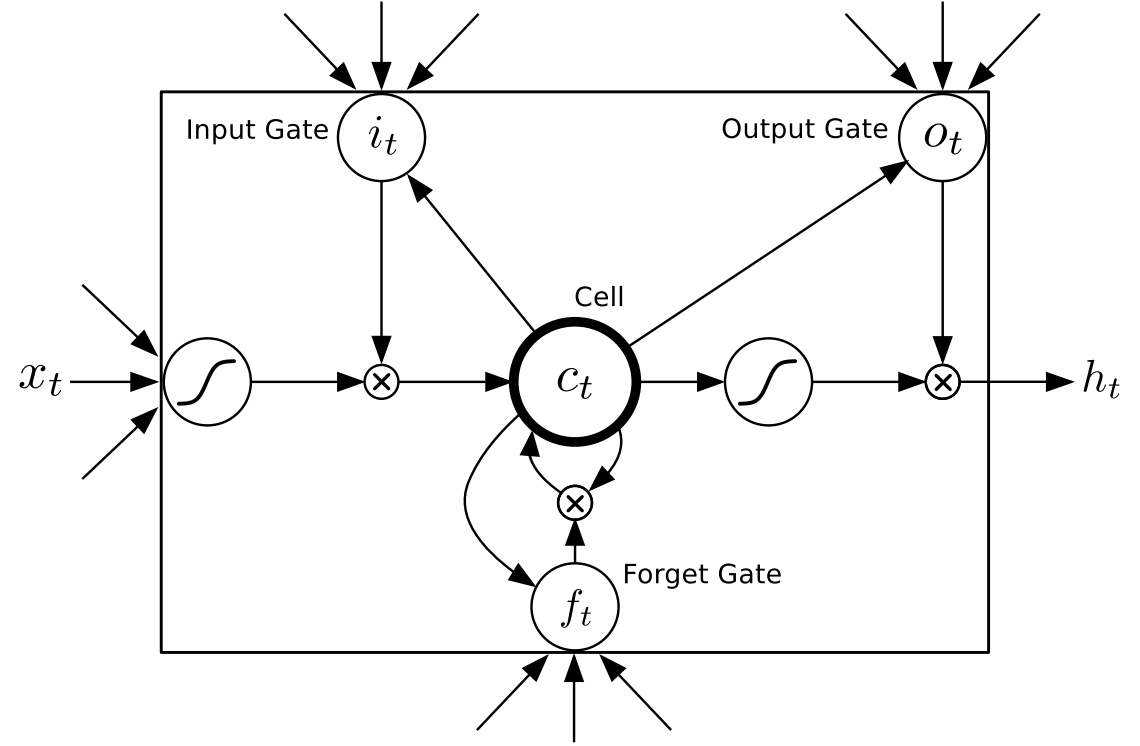
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,论文首次发表于1997年。由于独特的设计结构,LSTM适合于处理和预测时间序列中间隔和延迟非常长的重要事件。
RNN通过在时间共享参数引入了记特性,从而可以将先前的信息应用在当前的任务上,可是这种记忆通常只有有限的深度。
例如龙珠超或者火影每周更新一集,即使经历了一周的空档期,我们还是能将前一集的内容和新一集的情节无缝衔接起来。但是RNN的记忆就没有这么强的延续性,别说一个星期,5分钟估计都已经歇菜了。
LSTM可以像人的记忆中选择性地记住一些时间间隔更久远的信息,它会根据组成元素的特性,来判断不同信息是被遗忘或被记住继续传递下去。
LSTM就是实现长期记忆用的,实现任意长度的记忆。要求模型具备对信息价值的判断能力,结合自身确定哪些信息应该保存,哪些信息该舍弃,元还要能决定哪一部分记忆需要立刻使用。
LSTM通常由下面4个模块组成
标签:背英语单词 导致 input 孙悟空 span 学习 传递 神经元 部分
原文地址:https://www.cnblogs.com/chenqionghe/p/12688780.html