标签:inf api 课程 org 根据 一个 print lock 课堂
本文的所有代码都在GitHub上托管,想要代码的同学请点击这里??
序:由于自己想要实现一个课程推荐系统,需要在各大视频网站上爬取所有视频课程,从而为后续的推荐工作提供大量数据,在此篇博客中我分别爬取了MOOC、网易云课堂、腾讯课堂、学堂在线共约15万条数据。
运行环境:
mysqlclient~=1.4.6
requests~=2.22.0
bs4~=0.0.1
beautifulsoup4~=4.8.2
首先进入网站,在这里我们分析他的API设计,先要找到他是从哪一个API获得相应课程的,经过分析之后我们发现是https://www.icourse163.org/web/j/courseBean.getCoursePanelListByFrontCategory.rpc这个API,其返回内容如下:

然后我们随意点击页面上的一个课程,找到其课程url的规律,打开沟通心理学这门课程,其URL是https://www.icourse163.org/course/HIT-1001515007,而沟通心理学这门课程返回的信息是:
// 在这里我只保留了我需要的一些数据
{
name: "沟通心理学",
id: 1001515007,
schoolPanel: {id: 9005, name: "哈尔滨工业大学", shortName: "HIT"}
}
我们可以发现课程的URL就是学校的简称-id,这样就可以组成课程URL,现在我们得知课程URL如何得知,那么这些课程数据需要传什么参数呢,如下:
{
categoryId: -1, // 类别id,因为我这里选的全部,所以是-1
type: 30,
orderBy: 0,
pageIndex: 1, // 第几页
pageSize: 20 // 每页多少条数据
}
到这里就新产生了一个问题,categoryId是怎么来的,我们继续看网页请求的api列表,找到这样一个APIhttps://www.icourse163.org/web/j/mocCourseCategoryBean.getCategByType.rpc,其返回结果如下:

数据结构大致如下:
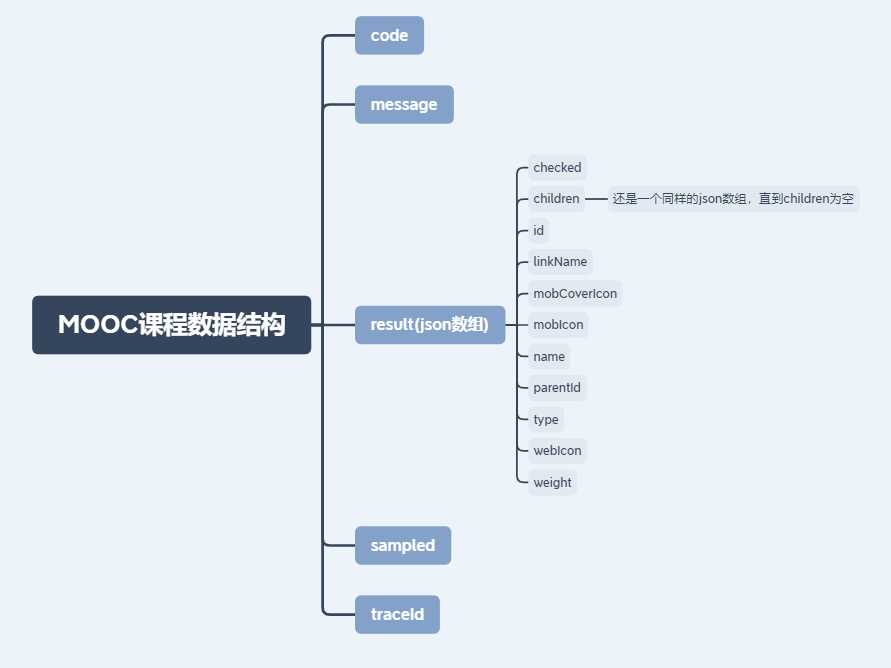
我们想要得到的课程分类特别细致的话就需要一直向下找json的children,直到children为空,算法的话就采用递归算法就可以。
到现在为止我们已经知道了如何获取类别id,如果由类别id获得课程数据,接下来我们就需要把获取到的数据存储到数据库中,我的数据库包含类别、课程名称、课程图片URL、课程URL、课程来源这四个字段,存储代码如下:
# 存储到数据库
def save_to_mysql(data, category_name):
sql = "insert into webCourses (category, name, site, imgUrl, resource) values (‘{0}‘, ‘{1}‘, ‘{2}‘, ‘{3}‘, ‘{4}‘)".format(
category_name, data["name"],
‘https://www.icourse163.org/course/‘ + str(data["schoolPanel"]["shortName"]) + "-" + str(data["id"]),
data["imgUrl"], "慕课")
print(sql)
execute(sql)
要注意这里的execute函数是我封装的一个函数,具体的作用就是运行sql语句,全部代码请到我的GitHub查看。
其实如果你看过了上面MOOC的获取所有课程的API设计,其他课程网站的API设计也是大致相同的,首先我们要获得类别id,然后再根据类别id去请求数据,与mooc不同的是腾讯课堂请求课程数据是通过beautifulsoup4解析html内容实现的。下面就来简单说一下:
获取课程类别的API:https://ke.qq.com/cgi-bin/get_cat_info
根据类别id获得数据的网页url: https://ke.qq.com/course/list?mt=1001&st=2001&tt=3001&page=2,这里的mt、st、tt分别是三个类别,st是mt的一个子类,tt是st的一个子类,page就是页数了。
得到的网站如下:
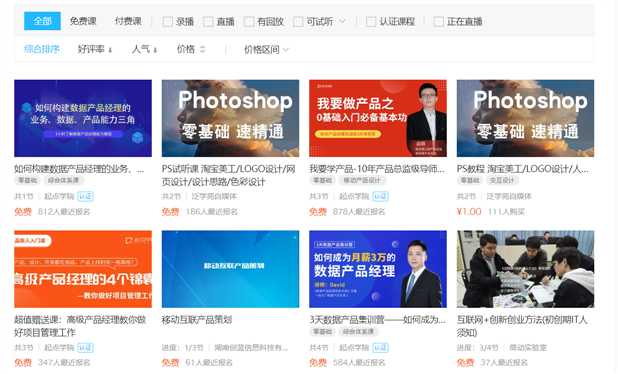
在这里我们需要的是每一个课程,其实思路很简单,按F12打开开发者工具,找到课程对应的dom块,用beautifulsoup4解析html内容,得到课程数组就可以了,代码如下:
# 获取课程数据
def get_course_data(mt, st, tt, page, category):
url = "https://ke.qq.com/course/list?mt=" + str(mt) + "&st=" + str(st) + "&tt=" + str(tt) + "&page=" + str(page)
response = requests.request("GET", url).text
bs = BeautifulSoup(response)
course_blocks = bs.find_all(name=‘li‘, attrs={"class": "course-card-item--v3 js-course-card-item"})
# print(course_blocks)
if len(course_blocks) != 0:
for i in range(len(course_blocks)):
bs = course_blocks[i]
img = bs.find(name="img", attrs={"class", "item-img"})
a = bs.find(name="a", attrs={"class", "item-img-link"})
save_to_mysql(img.attrs["alt"], a.attrs["href"], img.attrs["src"], category)
return True # 这里是返回该类别的下一页是否还有数据
else:
return False
得到数据之后再将这些数据存入到数据库中就可以了。
其实网易云课堂就和MOOC的API设计非常类似了,毕竟都是网易公司的程序员写的,规范也都差不多,看懂MOOC的api设计的同学直接去我的github看代码就可以了。
学堂在线的API设计就比较简单,直接通过一个API就可以获得所有的数据,https://next.xuetangx.com/api/v1/lms/get_product_list/?page=1,返回的数据格式如下:
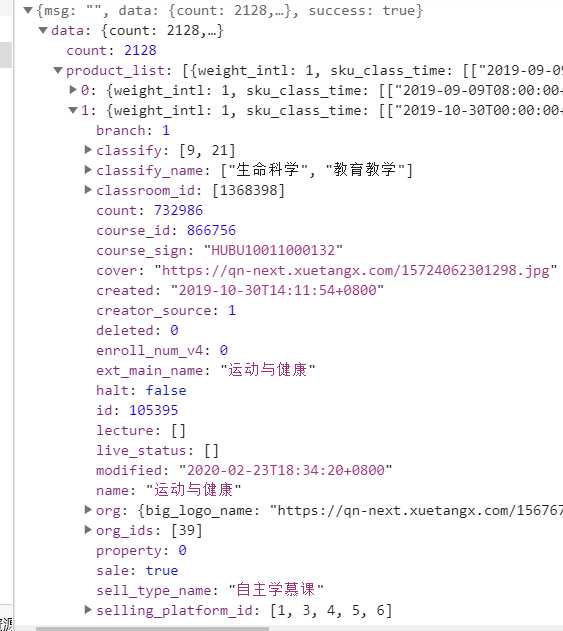
在这里一个API里面课程名称、分类、课程封面URL,课程id可以看的非常请求,下面我们就需要得到课程信息与课程url之间的关系,我们随意点开一个课程,分析他的URL,我们就可以发现,课程URL就是https://next.xuetangx.com/course/加上课程的course_sign组成的。
到这里就分析结束,存储到数据库即可。
从上述的分析我们可以看出,各大课程网站的api设计都是类似的,并且他们都没有做api请求限制,所以我在爬取过程中没有遇到过被封IP的情况,也算是省了不少事??。在这里把代码与思路分享给大家,希望能够给到大家一些帮助。所有代码请点击这里??
标签:inf api 课程 org 根据 一个 print lock 课堂
原文地址:https://www.cnblogs.com/Jacob98/p/12718425.html