标签:整理 from numpy info end import png app 连接
# 在对数据进行分析时,主要细分为明确目标、应用思维和如下8个具体步骤:
1、读取数据
2、清洗数据
3、操作数据
4、转换数据
5、整理数据
6、分析数据
7、展现数据
8、总结报告
接下来将介绍使用python来具体处理数据,包括上面几个步骤的实现,以及给出具体的操作例子。
需要记住的是使用python处理数据所用到的 具体函数、方法。
# 一、python读取数据
‘‘‘‘‘‘
1、简要
2、如何从Excel文件中读取数据
3、如何从MySQL数据库中读取数据
4、如何从网页中读取数据
‘‘‘‘‘‘
1、简要
读取数据时数据分析的第一步,相对来说比较简单,读取数据类型可以大致分为几类,一般用到的都是从 excel表、数据库、网页中进行读取。
我们使用python中的pandas库来实现读取操作。
2、如何从Excel文件中读取数据
Python代码如下:
读取数据之前需要导入pandas库
#导入pandas库
import pandas as pd
#导入Excel文件
df = pd.read_excel(‘文件名.xlsx‘)
3、如何从MySQL数据库中读取数据
读取数据之前需要安装pymysql模块
# 安装pymysql模块(在终端操作)
pip install pymysql
#安装后,读取操作代码如下:
import pandas as pd
import pymysql
# 创建数据库连接
conn = pymysql.connect(host=‘‘, user=‘‘, passwd=‘‘, database=‘‘)
# 创建游标
cursor = conn.cursor()
# 写SQL语句
sql = "select * from 表名"
#读取数据
df = pd.read_sql(sql,conn)
df.head()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
4、如何从网页中读取数据
访问网页时需要用到ssl模块,解决证书不受信任问题
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
# 网址
url = ‘http://s.askci.com/stock/a/?reportTime=2019-03-31&pageNum=1‘
#读取网页中表格数据
dfs = pd.read_html(url)
# 二、python清洗数据
‘‘‘
1、如何查找异常
2、如何排除重复
3、如何删除缺失
4、如何补全缺失
5、应用案例
‘‘‘
下面使用待清洗的扑克牌作为示例,来完成以上操作。
import numpy as np
import andas as pd
pd.set_option(‘max_rows‘,10)
df = df.read_excel("待清洗的扑克牌.xlsx")
df
返回结果如下:
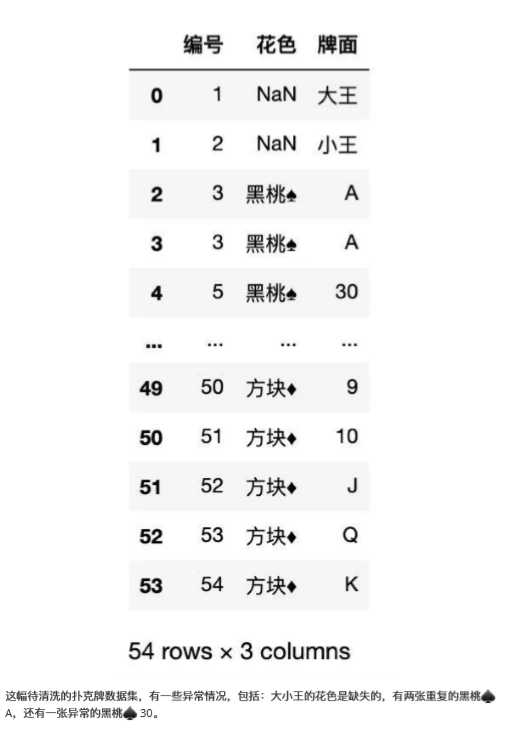
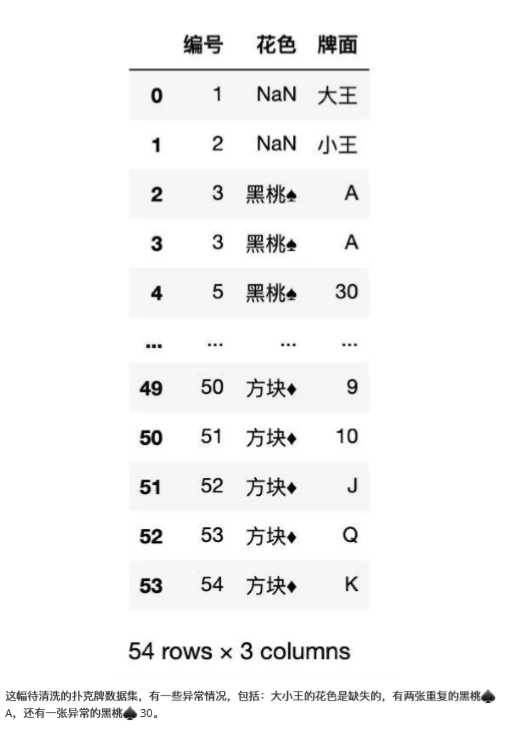
1、如何查找异常
在清洗数据之前需要把异常的数据查找出来,观察异常数据特征,然后确定清洗方法。
一般查找数据异常方式:
查找某一列缺失
查找重复的行列
查找某一列的唯一值
#查找花色缺失的行
df[df.花色.isnull()]
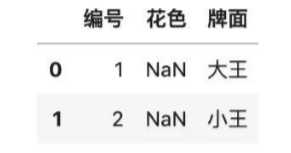
# 查找完全重复的行
df[df.duplicated()]

# 查找某一列重复的行
df[df.编号.duplicated()]

#查找牌面所有唯一值
df.牌面.unique()
返回结果如下:
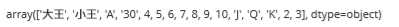
根据常识可以得出,‘30‘为异常值。
#查找牌面包含30的异常值
df[df.牌面.isin([‘30‘])]

2、如何排除重复
使用drop_duplicates()函数,在排除重复后会得到新的返回值。
#排除完全重复的行,默认保留第一行
df.drop_duplicates()
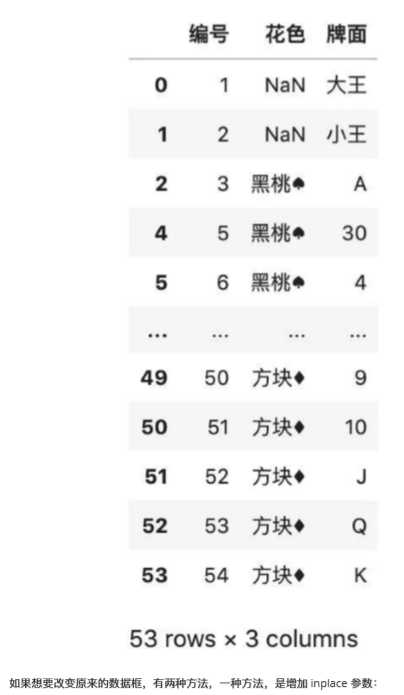
# 按照莫一列排除重复,默认保留第一行
df.drop_duplicates([‘花色‘])
# 按照莫一列排除重复,默认保留最后一行
df.drop_duplicates([‘花色‘],keep = ‘last‘)
3、如何删除缺失
使用dropna()默认删除包含缺失的行
使用扑克牌中不重复的花色为例
color = df.drop_duplicates([‘花色‘])
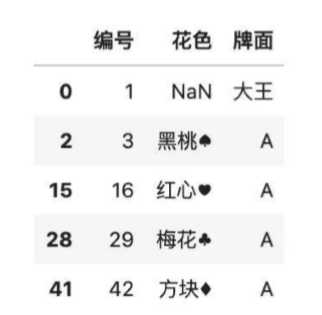
#删除花色缺失的行
color.dropna()
#删除整行全部为空的行,需要指定how参数
color.dropna(how=‘all‘)
#删除包含缺失值的列
color.dropna(axis = 1)
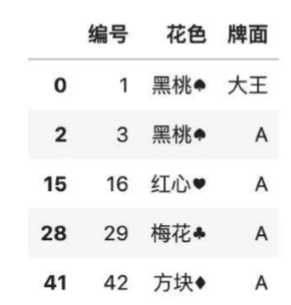
4、如何补全缺失
# 使用fillna()函数可以将缺失值填充成制定的值。
color.fillna(‘joker‘)

# 使用临近值填充需要指定method参数
#用后面的值填充
color.fillna(method= ‘bfill‘)
# 按字典填充
# 先制定一个缺失值
color.loc[2,‘牌面‘] = np.nan
color
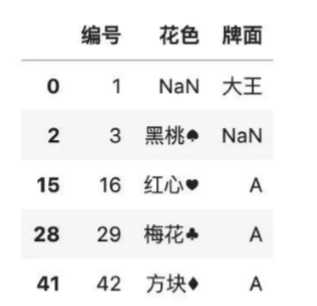
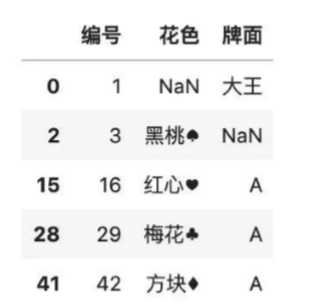
#按列自定义补全缺失值
color.fillna({‘花色‘:0,‘牌面‘:1})
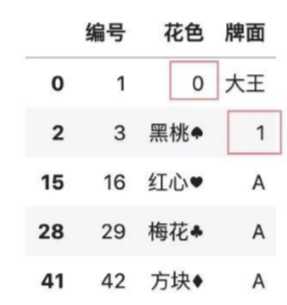
5、应用案例
import numpy as np
import pandas as pd
# 设置最多显示10行
pd.set_option(‘max_rows‘,10)
#从Excel文件中读取原始数据
df = pd.read_excel(‘待清洗的扑克牌‘.xlsx)
#补全缺失值
df = pd.fillna(‘joker‘)
#排除重复值
df = pd.drop_duplicates()
# 修改异常值
df.loc[4,‘牌面‘] = 3
# 增加一张缺少的牌
df = df.append({‘编号‘:4,‘花色‘:‘黑桃♠‘,‘牌面‘:2},ignore_index = True)
#按编号排序
df = df.sort_values(‘编号‘)
# 重置索引
df = df.reset_index()
# 删除多余的列
df = df.drop([‘index‘],axis = 1)
#清洗好的数据保存到excel文件中
df.to_excel(‘清洗好的扑克牌‘.xlsx,index = False)
df
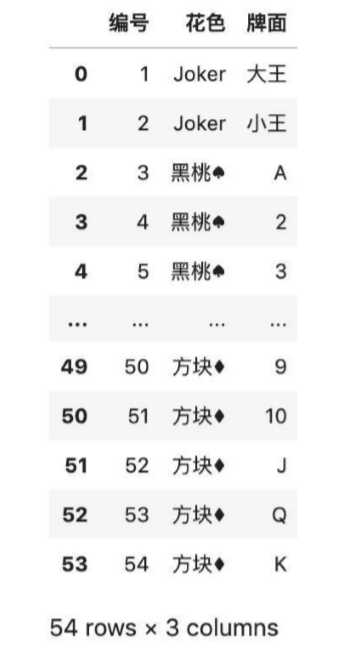
上图为完整的扑克牌数据。
标签:整理 from numpy info end import png app 连接
原文地址:https://www.cnblogs.com/xxstudyshare/p/12746033.html