标签:soc 解释器 就是 同步锁 上下文 垃圾回收机制 pre src 主程序
multiprocessing 的 Lock()
不加锁:未加锁部分并发执行,加锁部分串行执行,速度慢,数据安全
在start之后立刻使用jion,肯定会将100个任务的执行变成串行,毫无疑问,最终n的结果也肯定是0,是安全的,但问题是
#start后立即join:任务内的所有代码都是串行执行的,而加锁,只是加锁的部分即修改共享数据的部分是串行的
#单从保证数据安全方面,二者都可以实现,但很明显是加锁的效率更高.
线程执行速度快,直接创建,
进程要先创建进程,申请空间。
线程 > 主程序 > 进程
垃圾回收 是 线程,干活的。进程是一块内存空间,空间里有主线程,和其它线程。
https://www.cnblogs.com/xiaoyuanqujing
data_bytes = bytes(data,enconding= ‘utf-8‘) # 转二进制的一种方式
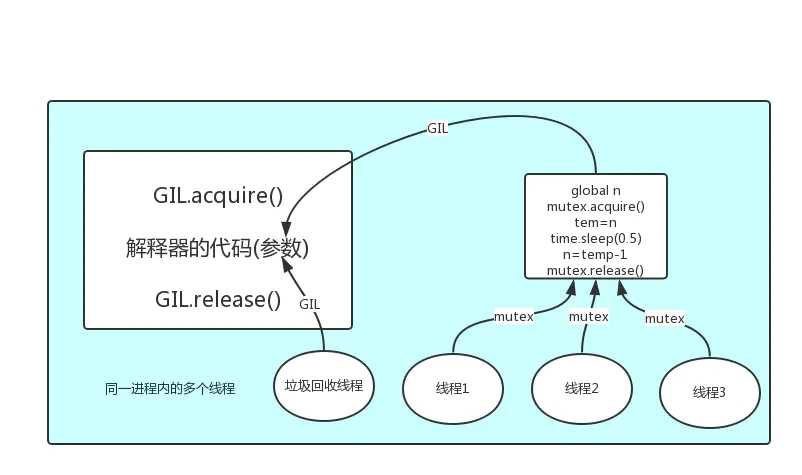
GIL:防止一个进程内(内存共享),多个线程(垃圾回收机制也是一个线程)同时运行,造成的内存管理的不安全。如果多个线程同时操作一个数据,那就错乱了。所以CPython解释器层面的锁就是GIL锁。阻止你多个线程同时运行,变成串行。一个一个操作。
当遇到io操作的时候,延迟的时候,sleep的时候,就会释放锁。所以,换了GIL锁之后,数据状态也许被每个线程存储了,输出结果都是一样的,所以,自己再加一个互斥锁mutex。
with mutex:
pass
mutex.acquire()
mutex.release()
GIL 内存管理,统一进程多线程不安全,
GIL保护的是解释器级的数据,保护用户自己的数据则需要自己加锁处理
关于为什么要 有 GIL :https://www.cnblogs.com/Mr-hu/articles/7791546.html
GIL 关于内存管理(垃圾回收机制)的作用:https://www.jianshu.com/p/86c0e9d3b982
多线程用于IO密集型,如socket,爬虫,web
多进程用于计算密集型,如金融分析
单核的情况下永远肯定是串行的,cpu真正执行的时候,因为一会儿执行1,一会儿执行2,一会儿执行3.....一会儿又切回到1,就是这样如此反复切换上下文。多核情况下,可以同时有几个线程并行,这是正常的线程执行过程。但是,在python中,无论你有多少核,永远都是假象。无论你是4核,8核,还是16核.......不好意思,同一时间执行的线程只有一个线程,它就是这个样子的。这个是python的一个开发时候,设计的一个缺陷,所以说python中的线程是假线程。
在任意时刻,只有一个线程在解释器中运行。对CPython 解释器的访问由全局解释器锁(GIL)来控制,正是这个锁能保证同一时刻只有一个线程在运行。
GIL是限制同一个进程中只有一个线程进入Python解释器。。。。。
而线程锁是由于在线程进行数据操作时保证数据操作的安全性(同一个进程中线程之间可以共用信息,如果同时对数据进行操作,则会出现公共数据错误)
其实线程锁完全可以替代GIL,但是Python的后续功能模块都是加在GIL基础上的,所以无法更改或去掉GIL,这就是Python语言最大的bug…只能用多进程或协程改善,或者直接用其他语言写这部分
python GIL 之所以会影响多线程等性能,是因为在多线程的情况下,只有当线程获得了一个全局锁的时候,那么该线程的代码才能运行,而全局锁只有一个,所以使用python多线程,在同一时刻也只有一个线程在运行,因此在即使在多核的情况下也只能发挥出单核的性能。
GIL cpython解释器的锁,出现io操作或者sleep等,会移交锁的权限。
GIL 不能保证所有的数据安全,因为出现io操作等,也会换其他进程操作数据
所以,要自己加锁。同步锁,即Lock(multiprocessing)提供的锁
两个锁,分别被两个进程或线程抢到,互相又释放不了,造成死锁。
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire()
print(‘%s 抢到了面条‘%name)
fork_lock.acquire()
print(‘%s 抢到了叉子‘%name)
print(‘%s 吃面‘%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print(‘%s 抢到了叉子‘ % name)
time.sleep(1)
noodle_lock.acquire()
print(‘%s 抢到了面条‘ % name)
print(‘%s 吃面‘ % name)
noodle_lock.release()
fork_lock.release()
for name in [‘哪吒‘,‘egon‘,‘yuan‘]:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
死锁问题
解决方法,递归锁,在Python中为了支持在同一线程中多次请求同一资源,python提供了可重入锁RLock。
这个RLock内部维护着一个Lock和一个counter变量,counter记录了acquire的次数,从而使得资源可以被多次require。直到一个线程所有的acquire都被release,其他的线程才能获得资源。上面的例子如果使用RLock代替Lock,则不会发生死锁:
import time
from threading import Thread,RLock
fork_lock = noodle_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print(‘%s 抢到了面条‘%name)
fork_lock.acquire()
print(‘%s 抢到了叉子‘%name)
print(‘%s 吃面‘%name)
fork_lock.release()
noodle_lock.release()
def eat2(name):
fork_lock.acquire()
print(‘%s 抢到了叉子‘ % name)
time.sleep(1)
noodle_lock.acquire()
print(‘%s 抢到了面条‘ % name)
print(‘%s 吃面‘ % name)
noodle_lock.release()
fork_lock.release()
for name in [‘哪吒‘,‘egon‘,‘yuan‘]:
t1 = Thread(target=eat1,args=(name,))
t2 = Thread(target=eat2,args=(name,))
t1.start()
t2.start()
递归锁解决死锁问题
标签:soc 解释器 就是 同步锁 上下文 垃圾回收机制 pre src 主程序
原文地址:https://www.cnblogs.com/pythonwl/p/12769635.html