标签:min 认证 items ip修改 spool 地址栏 技术 check toc
我们按照【三节点大数据环境安装教程1】已经完成虚拟机的克隆,但是我们克隆出来的三台虚拟机的配置是一样的需要做简单的修改.
1.启动第一台虚拟机
2.启动第二台虚拟机
3.启动第三台虚拟机
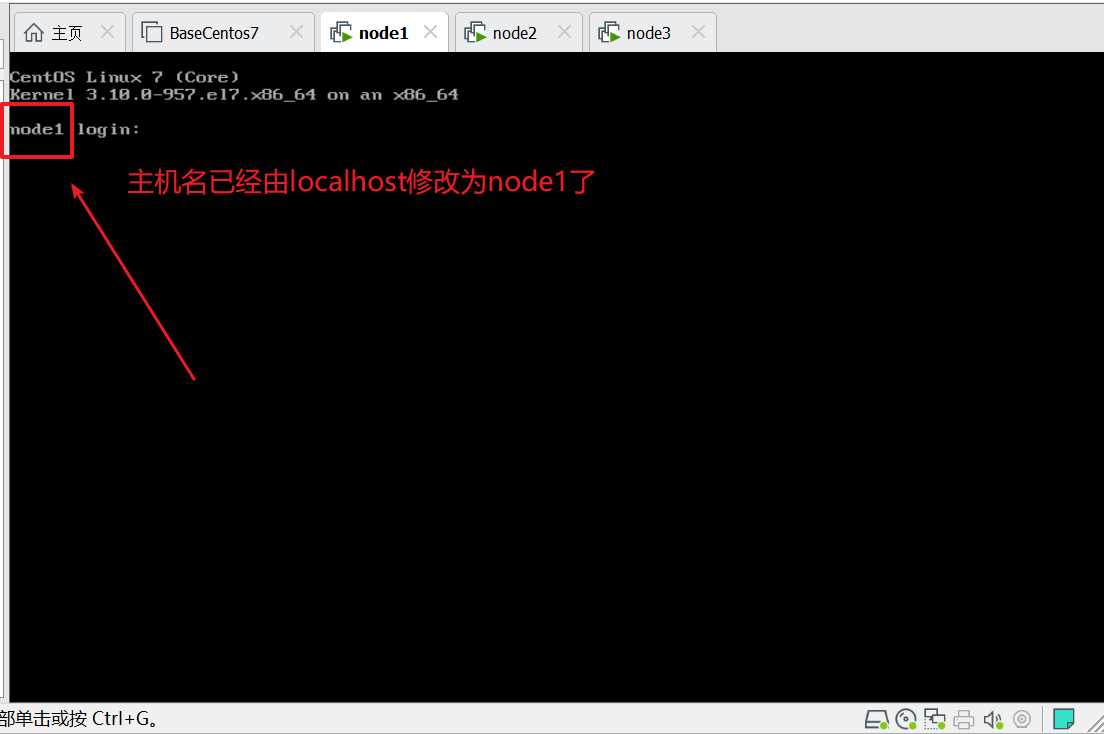
第一台机器上设置主机名node1
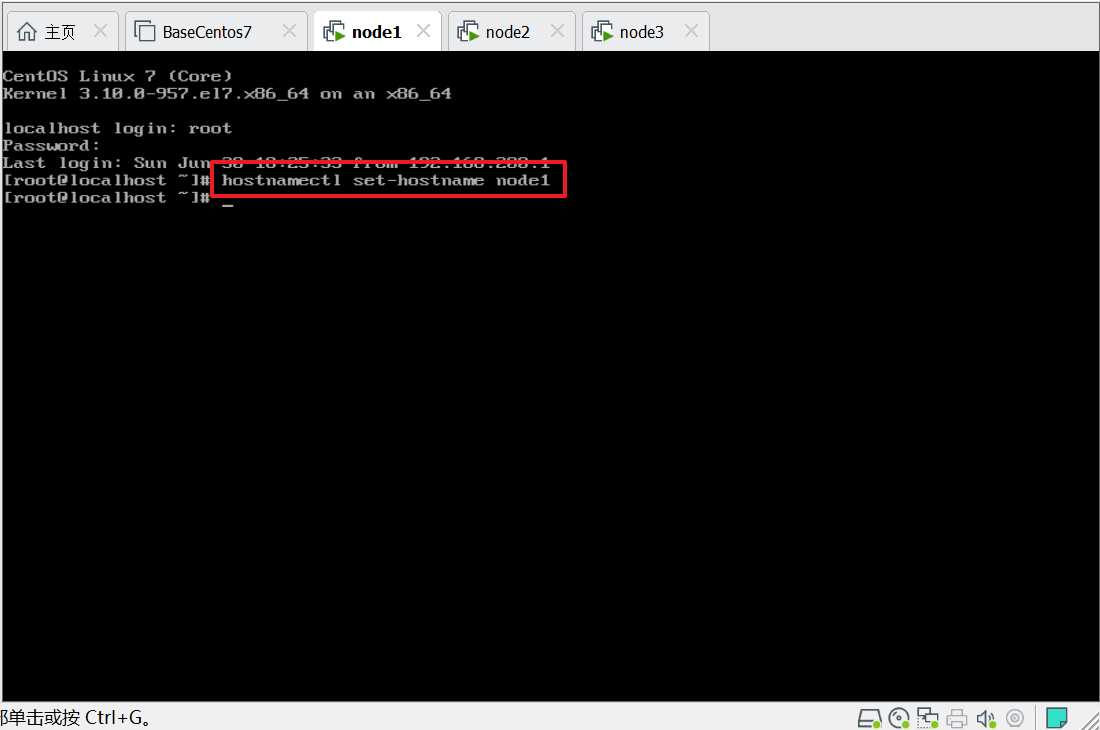
第二台机器上设置主机名node2
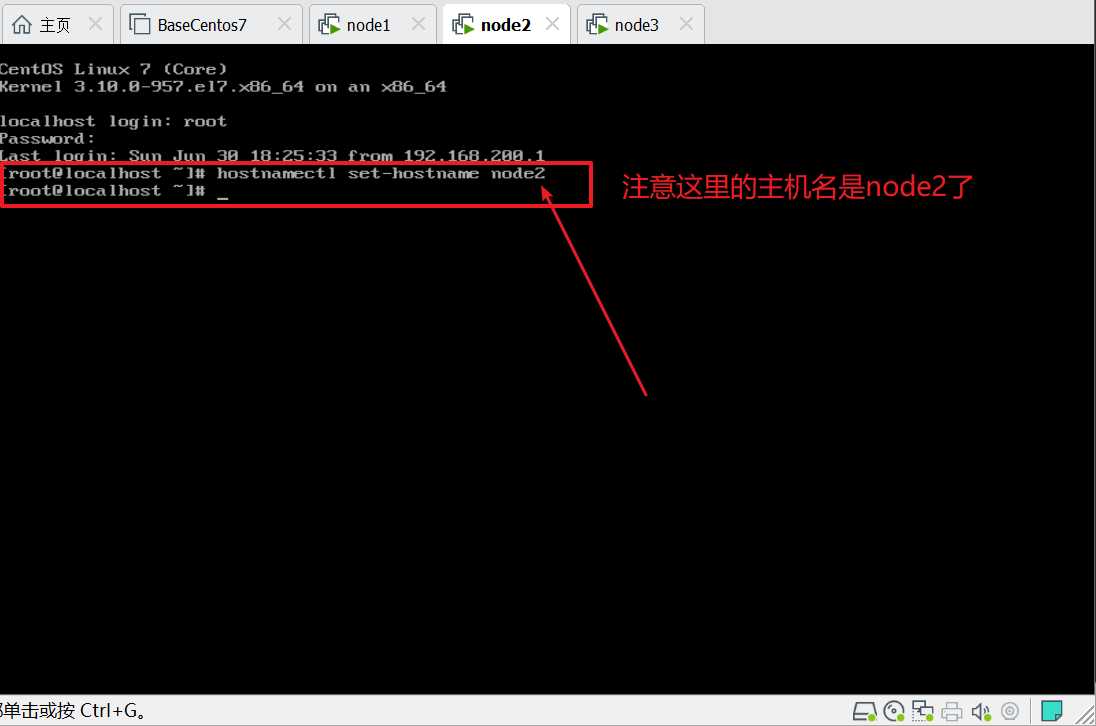
第三台机器上设置主机名node3
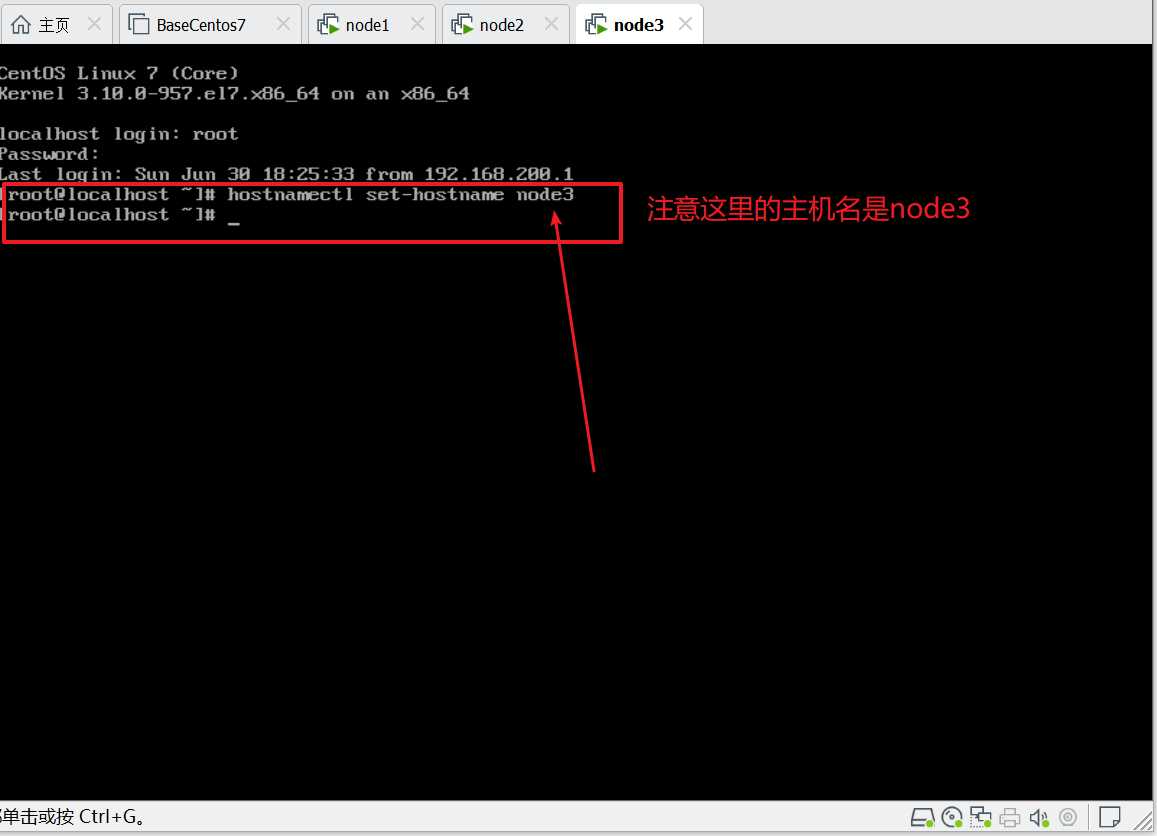
然后在三台机器上分别执行命令:logout
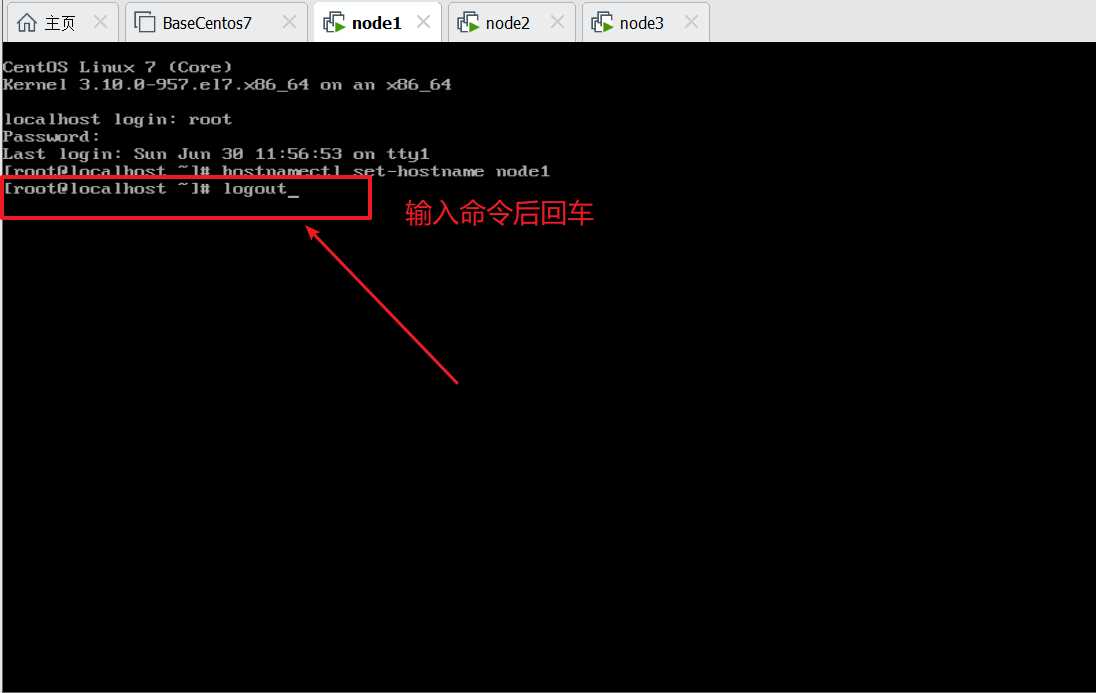
发现主机名已经修改成node1了,相同的操作大家在其他两台机器上执行下看看效果.
三节点ip规划如下:
| 节点名称 | ip |
|---|---|
| node1 | 192.168.200.11 |
| node2 | 192.168.200.12 |
| node3 | 192.168.200.13 |
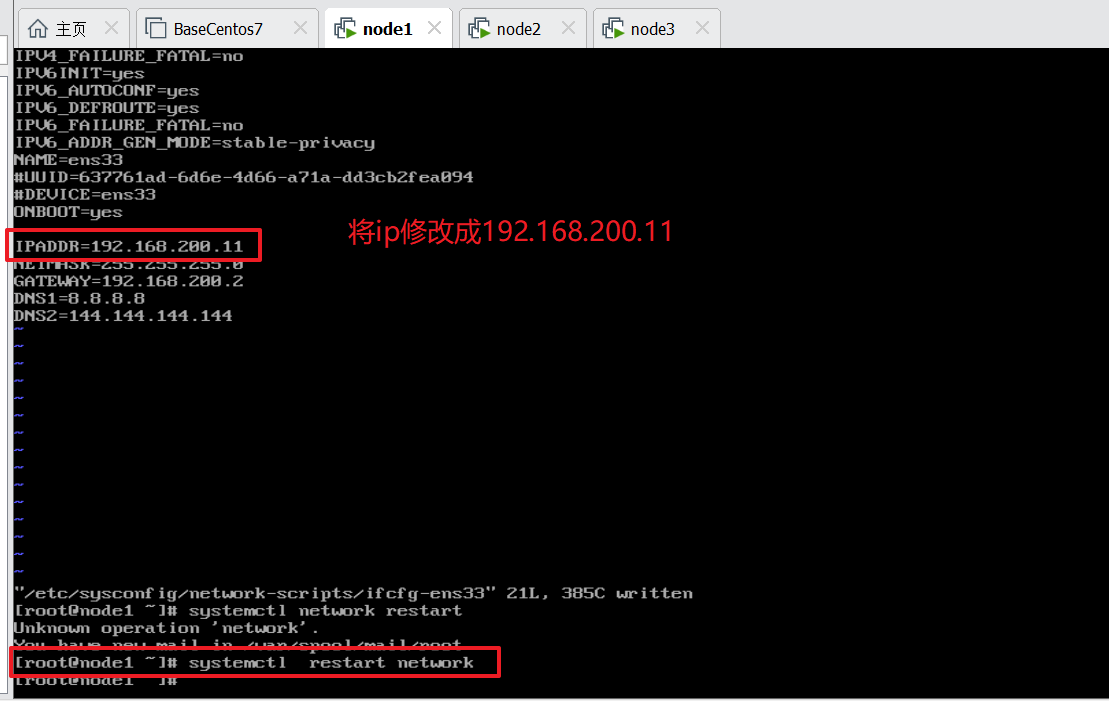
如下图,将node1上的ip修改为192.168.200.11,修改完后使用命令:systemctl restart network重启网卡
按照上面步骤一次修改node2的ip为:192.168.200.12,修改完后使用systemctl restart nework命令重启网卡,node3的ip修改方法一样,修改为192.168.200.13,修改完后重启网卡.
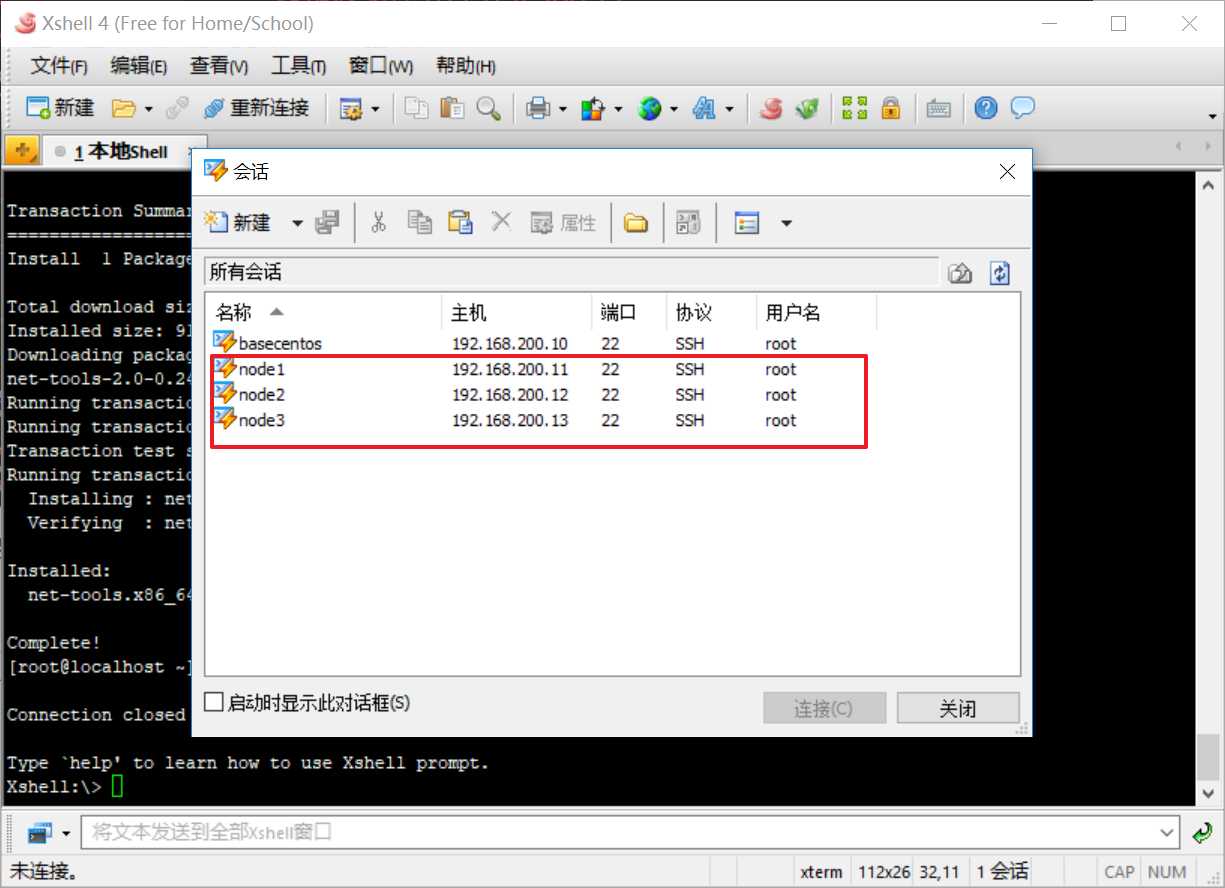
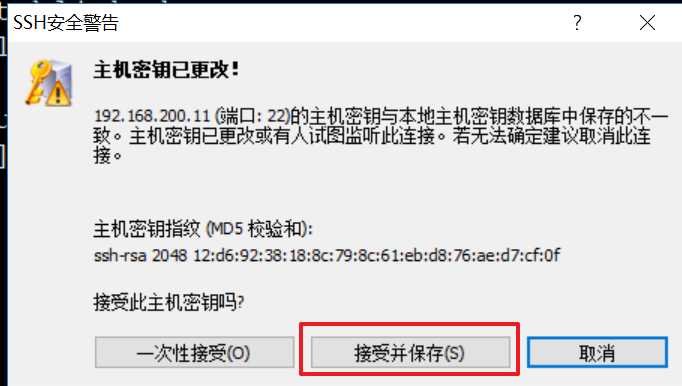
按住Ctrl一次选择三台虚拟机的会话连接,点击连接,这时会一次性打开三台虚拟机的连接会话
会出现三次安全警告,连续点击三次接受并保存即可.
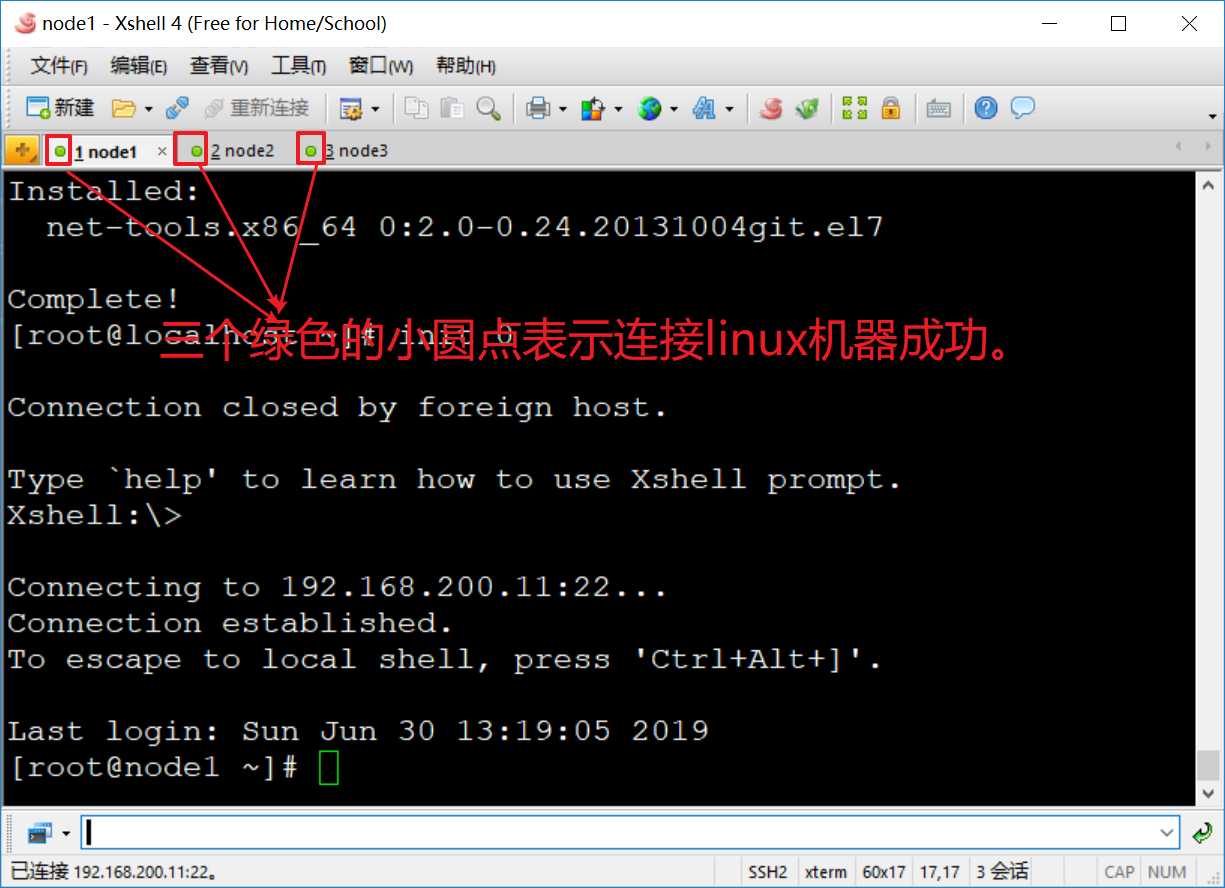
? 使用此命令:ssh-keygen -t rsa 分别在三台机器中都执行一遍,这里只在node1上做演示,其他两台机器也需要执行此命令。
[root@node1 ~]# ssh-keygen -t rsa #<--回车
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): #<--回车
#会在root用户的家目录下生成.ssh目录,此目录中会保存生成的公钥和私钥
Created directory ‘/root/.ssh‘.
Enter passphrase (empty for no passphrase): #<--回车
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:gpDw08iG9Tq+sGZ48TXirWTY17ajXhIea3drjy+pU3g root@node1
The key‘s randomart image is:
+---[RSA 2048]----+
|. . |
| * = |
|. O o |
| . + . |
| o . + S. |
| ..+..o*. E |
|o o+++*.=o.. |
|.=.+oo.=oo+o |
|+.. .oo.o=o+o |
+----[SHA256]-----+
You have new mail in /var/spool/mail/root
[root@node1 ~]#
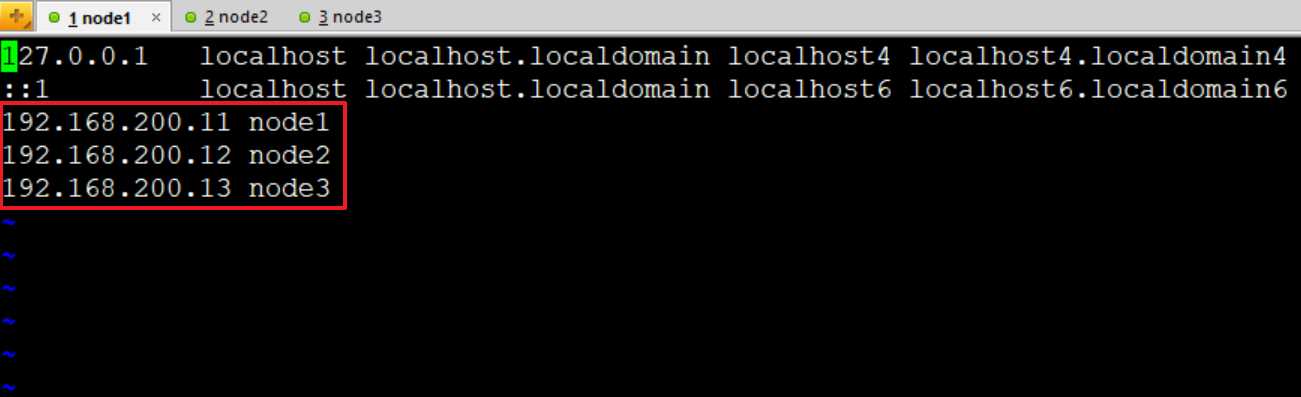
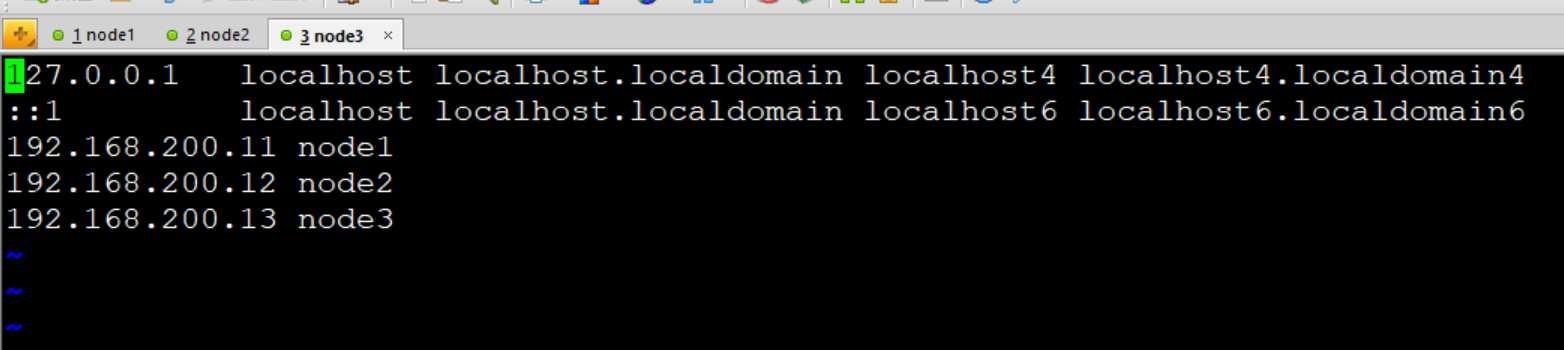
#hosts文件中配置三台机器ip和主机名的映射关系,其他两台机器按照相同的方式操作.
[root@node1 ~]# vi /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.200.11 node1
192.168.200.12 node2
192.168.200.13 node3
node1的配置:
node2的配置:
node3的配置:
3.4 拷贝公钥文件
以下以node1为例执行秘钥复制命令:ssh-copy-id -i 主机名
#复制到node2上
[root@node1 ~]# ssh-copy-id -i node2
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host ‘node2 (192.168.200.12)‘ can‘t be established.
ECDSA key fingerprint is SHA256:rJzUyoggUP/Zn9v5rvqKpWppnG9xZ4gBZuXqHWxPy5k.
ECDSA key fingerprint is MD5:f3:37:16:c4:bb:00:3e:59:ec:b3:37:23:1b:24:88:e6.
Are you sure you want to continue connecting (yes/no)? yes #询问是否要连接输入yes回车
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node2‘s password: #输入root用户的密码root后回车
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ‘node2‘"
and check to make sure that only the key(s) you wanted were added.
#复制到node3上
[root@node1 ~]# ssh-copy-id -i node3
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub"
The authenticity of host ‘node3 (192.168.200.13)‘ can‘t be established.
ECDSA key fingerprint is SHA256:rJzUyoggUP/Zn9v5rvqKpWppnG9xZ4gBZuXqHWxPy5k.
ECDSA key fingerprint is MD5:f3:37:16:c4:bb:00:3e:59:ec:b3:37:23:1b:24:88:e6.
Are you sure you want to continue connecting (yes/no)? yes #询问是否要连接输入yes回车
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
root@node3‘s password: #输入root用户的密码root后回车
Number of key(s) added: 1
Now try logging into the machine, with: "ssh ‘node3‘"
and check to make sure that only the key(s) you wanted were added.
[root@node1 ~]#
此操作只在node1上操作,其他机器上大家在验证。
#使用ssh 命令登录node2
[root@node1 ~]# ssh node2
Last login: Sun Jun 30 13:56:53 2019 from node1
#登录成功后这里的命令提示符已经变为[root@node2 ~]#说明登录成功
[root@node2 ~]# logout #退出node2继续 验证登录node3
Connection to node2 closed.
#登录node3
[root@node1 ~]# ssh node3
Last login: Sun Jun 30 13:56:55 2019 from node1
#登录成功
[root@node3 ~]# logout
Connection to node3 closed.
You have new mail in /var/spool/mail/root
[root@node1 ~]#
#进入到root用户的家目录下
[root@node1 ~]# cd ~
[root@node1 ~]# cd .ssh/
#讲生成的公钥添加到认证文件中
[root@node1 .ssh]# cat id_rsa.pub >> authorized_keys
[root@node1 .ssh]#
创建hadoop用户组和hadoop用户需要在三台机器上分别操作
#1.创建用户组hadoop
[root@node1 ~]# groupadd hadoop
#2.创建用户hadoop并添加到hadoop用户组中
[root@node1 ~]# useradd -g hadoop hadoop
#3.使用id命令查看hadoop用户组和hadoop用户创建是否成功
[root@node1 ~]# id hadoop
#用户uid 用户组id gid 用户组名
uid=1000(hadoop) gid=1000(hadoop) groups=1000(hadoop)
#设置hadoop用户密码为hadoop
[root@node1 ~]# passwd hadoop
Changing password for user hadoop.
New password: #输入hadoop后回车
BAD PASSWORD: The password is shorter than 8 characters
Retype new password: #再次输入hadoop后回车
passwd: all authentication tokens updated successfully.
[root@node1 ~]# chown -R hadoop:hadoop /home/hadoop/
[root@node1 ~]# chmod -R 755 /home/hadoop/
#把root用户的环境变量文件复制并覆盖hadoop用户下的.bash_profile
[root@node1 ~]# cp .bash_profile /home/hadoop/
对hadoop用户做免密码登录配置参考root用户的方式
[hadoop@node1 ~] su - hadoop
[hadoop@node1 ~] source .bash_profile
#使用su - hadoop切换到hadoop用户下执行如下操作
[hadoop@node1 ~]# ssh-keygen -t rsa #<--回车
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa): #<--回车
#会在root用户的家目录下生成.ssh目录,此目录中会保存生成的公钥和私钥
Created directory ‘/root/.ssh‘.
Enter passphrase (empty for no passphrase): #<--回车
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:gpDw08iG9Tq+sGZ48TXirWTY17ajXhIea3drjy+pU3g root@node1
The key‘s randomart image is:
+---[RSA 2048]----+
|. . |
| * = |
|. O o |
| . + . |
| o . + S. |
| ..+..o*. E |
|o o+++*.=o.. |
|.=.+oo.=oo+o |
|+.. .oo.o=o+o |
+----[SHA256]-----+
You have new mail in /var/spool/mail/root
[hadoop@node1 ~]#
#修改.ssh目录权限
[hadoop@node1 ~]$ chmod -R 755 .ssh/
[hadoop@node1 ~]$ cd .ssh/
[hadoop@node1 .ssh]$ chmod 644 *
[hadoop@node1 .ssh]$ chmod 600 id_rsa
[hadoop@node1 .ssh]$ chmod 600 id_rsa.pub
[hadoop@node1 .ssh]$ ssh-copy-id -i node3 # 将hadoop用户下得公钥配置到其他机器
[hadoop@node1 .ssh]$ cat id_rsa.pub >> authorized_keys #将自己的公钥也配置进去
在一台机器上配置好后复制到其他机器上即可,这样保证三台机器的hadoop配置是一致的.
#1.创建hadoop安装目录
[root@node1 ~]# mkdir -p /opt/bigdata
#2.解压hadoop-3.1.2.tar.gz
[root@node1 ~]# tar -xzvf hadoop-3.1.2.tar.gz -C /opt/bigdata/
1.配置环境变量
[root@node1 ~]# vi .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
HADOOP_HOME=/opt/bigdata/hadoop-3.1.2
PATH=$PATH:$HOME/bin:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export JAVA_HOME
export HADOOP_HOME
export PATH
~
:wq!
2.验证环境变量
#1.使环境变量生效
[root@node1 ~]# source .bash_profile
#2.显示hadoop的版本信息
[root@node1 ~]# hadoop version
#3.显示出hadoop版本信息表示安装和环境变量成功.
Hadoop 3.1.2
Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a
Compiled by sunilg on 2019-01-29T01:39Z
Compiled with protoc 2.5.0
From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9
This command was run using /opt/bigdata/hadoop-3.1.2/share/hadoop/common/hadoop-common-3.1.2.jar
[root@node1 ~]#
hadoop用户下也需要按照root用户配置环境变量的方式操作一下
这个文件只需要配置JAVA_HOME的值即可,在文件中找到export JAVA_HOME字眼的位置,删除最前面的#
export JAVA_HOME=/usr/java/jdk1.8.0_211-amd64
[root@node1 ~]# cd /opt/bigdata/hadoop-3.1.2/etc/hadoop/
You have new mail in /var/spool/mail/root
[root@node1 hadoop]# pwd
/opt/bigdata/hadoop-3.1.2/etc/hadoop
[root@node1 hadoop]# vi hadoop-env.sh
切换到cd /opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下
[root@node1 ~]# cd /opt/bigdata/hadoop-3.1.2/etc/hadoop/
<configuration>
<!-- 指定hdfs的namenode主机的hostname -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:9000</value>
</property>
<!-- io操作流的配置 -->
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<!--hadoop集群临时数据存储目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/tmpdata</value>
</property>
</configuration>
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的hdfs-site.xml
<configuration>
<!--namenode元数据存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/hadoop/hdfs/name/</value>
</property>
<!--指定block块的的大小-->
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<!-- -->
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<!--工作节点的数据块存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/bigdata/hadoop-3.1.2/hadoop/hdfs/data/</value>
</property>
<!--block的副本数-->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的mapred-site.xml
<!--指定运行mapreduce的环境是yarn -->
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=${HADOOP_HOME}</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*, $HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的yarn-site.xml
<configuration>
<!--指定resourcemanager的位置-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>node1:18040</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>node1:18030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>node1:18025</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>node1:18141</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>node1:18088</value>
</property>
</configuration>
8.编辑works
此文件用于配置集群有多少个数据节点,我们把node2,node3作为数据节点,node1作为集群管理节点.
配置/opt/bigdata/hadoop-3.1.2/etc/hadoop/目录下的works
[root@node1 hadoop]# vi workers
#将localhost这一行删除掉
node2
node3
~
#1.进入到root用户家目录下
[root@node1 hadoop]# cd ~
#2.使用scp远程拷贝命令将root用户的环境变量配置文件复制到node2
[root@node1 ~]# scp .bash_profile root@node2:~
.bash_profile 100% 338 566.5KB/s 00:00
#3.使用scp远程拷贝命令将root用户的环境变量配置文件复制到node3
[root@node1 ~]# scp .bash_profile root@node3:~
.bash_profile 100% 338 212.6KB/s 00:00
[root@node1 ~]#
#4.进入到hadoop的share目录下
[root@node1 ~]# cd /opt/bigdata/hadoop-3.1.2/share/
You have new mail in /var/spool/mail/root
[root@node1 share]# ll
total 0
drwxr-xr-x 3 1001 1002 20 Jan 29 12:05 doc
drwxr-xr-x 8 1001 1002 88 Jan 29 11:36 hadoop
#5.删除doc目录,这个目录存放的是用户手册,比较大,等会儿下面进行远程复制的时候时间比较长,删除后节约复制时间
[root@node1 share]# rm -rf doc/
[root@node1 share]# cd ~
You have new mail in /var/spool/mail/root
[root@node1 ~]# scp -r /opt root@node2:/
[root@node1 ~]# scp -r /opt root@node3:/
在node2,node3的root用户家目录下使环境变量生效
node2节点如下操作:
[root@node2 hadoop-3.1.2]# cd ~
[root@node2 ~]# source .bash_profile
[root@node2 ~]# hadoop version
Hadoop 3.1.2
Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a
Compiled by sunilg on 2019-01-29T01:39Z
Compiled with protoc 2.5.0
From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9
This command was run using /opt/bigdata/hadoop-3.1.2/share/hadoop/common/hadoop-common-3.1.2.jar
[root@node2 ~]#
node3节点如下操作:
[root@node3 bin]# cd ~
[root@node3 ~]# source .bash_profile
[root@node3 ~]# hadoop version
Hadoop 3.1.2
Source code repository https://github.com/apache/hadoop.git -r 1019dde65bcf12e05ef48ac71e84550d589e5d9a
Compiled by sunilg on 2019-01-29T01:39Z
Compiled with protoc 2.5.0
From source with checksum 64b8bdd4ca6e77cce75a93eb09ab2a9
This command was run using /opt/bigdata/hadoop-3.1.2/share/hadoop/common/hadoop-common-3.1.2.jar
[root@node3 ~]#
node2,node3也需要进行如下操作
#1.修改目录所属用户和组为hadoop:hadoop
[root@node1 ~]# chown -R hadoop:hadoop /opt/
You have new mail in /var/spool/mail/root
You have new mail in /var/spool/mail/root
#2.修改目录所属用户和组的权限值为755
[root@node1 ~]# chmod -R 755 /opt/
[root@node1 ~]# chmod -R g+w /opt/
[root@node1 ~]# chmod -R o+w /opt/
[root@node1 ~]#
#切换
[root@node1 ~]# su - hadoop
[hadoop@node1 hadoop]$ hdfs namenode -format
2019-06-30 16:11:35,914 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = node1/192.168.200.11
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 3.1.2
#此处省略部分日志
2019-06-30 16:11:36,636 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at node1/192.168.200.11
************************************************************/
[hadoop@node1 hadoop]$
[hadoop@node1 ~]$ start-all.sh
WARNING: Attempting to start all Apache Hadoop daemons as hadoop in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [node1]
Starting datanodes
Starting secondary namenodes [node1]
Starting resourcemanager
Starting nodemanagers
#使用jps显示java进程
[hadoop@node1 ~]$ jps
40852 ResourceManager
40294 NameNode
40615 SecondaryNameNode
41164 Jps
[hadoop@node1 ~]$
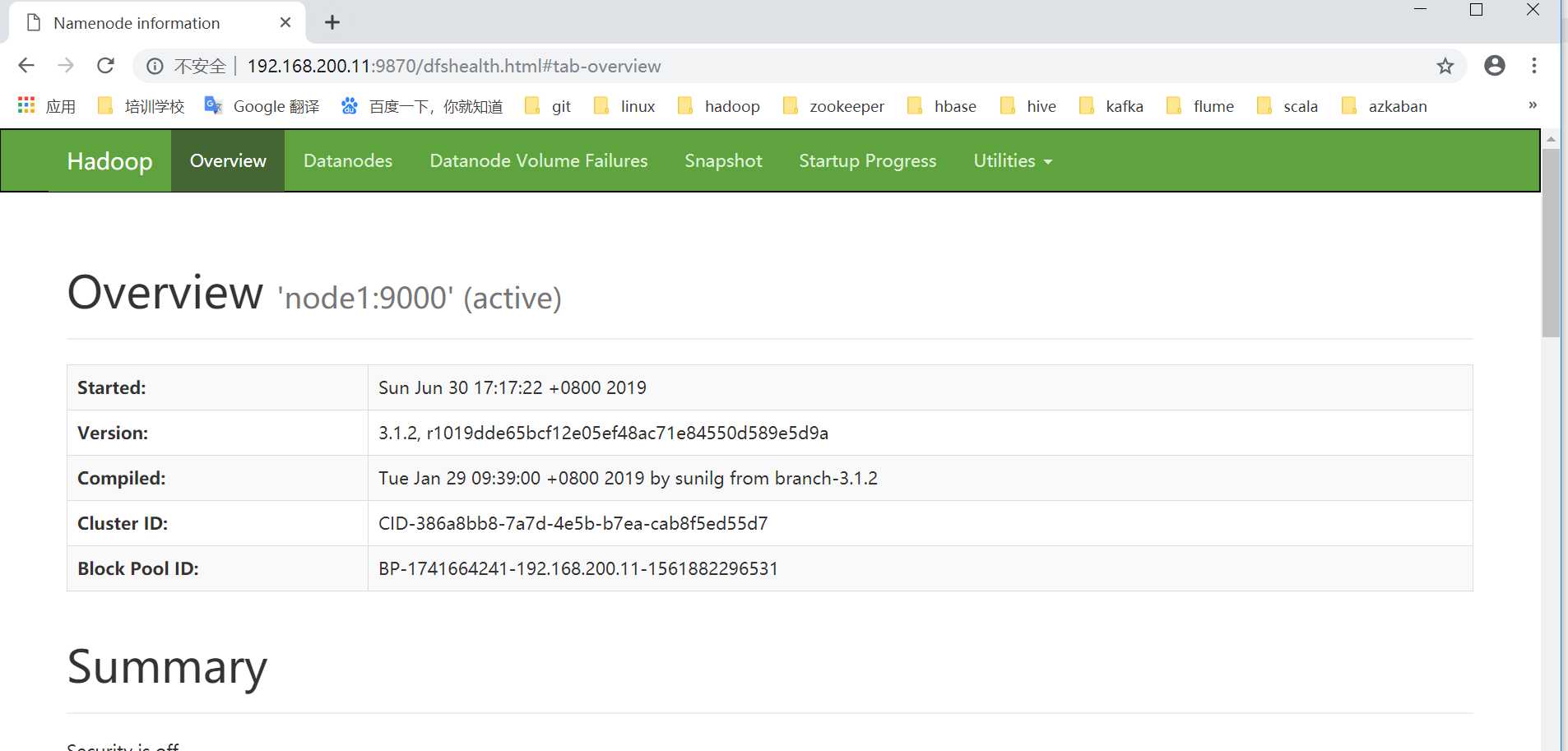
在浏览器地址栏中输入:http://192.168.200.11:9870查看namenode的web界面.
#1.使用hdfs dfs -ls / 命令浏览hdfs文件系统,集群刚开始搭建好,由于没有任何目录所以什么都不显示.
[hadoop@node1 ~]$ hdfs dfs -ls /
#2.创建测试目录
[hadoop@node1 ~]$ hdfs dfs -mkdir /test
#3.在此使用hdfs dfs -ls 发现我们刚才创建的test目录
[hadoop@node1 ~]$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2019-06-30 17:23 /test
#4.使用touch命令在linux本地目录创建一个words文件
[hadoop@node1 ~]$ touch words
#5.文件中输入如下内容
[hadoop@node1 ~]$ vi words
i love you
are you ok
#6.将创建的本地words文件上传到hdfs的test目录下
[hadoop@node1 ~]$ hdfs dfs -put words /test
#7.查看上传的文件是否成功
[hadoop@node1 ~]$ hdfs dfs -ls -r /test
Found 1 items
-rw-r--r-- 3 hadoop supergroup 23 2019-06-30 17:28 /test/words
#/test/words 是hdfs上的文件存储路径 /test/output是mapreduce程序的输出路径,这个输出路径是不能已经存在的路径,mapreduce程序运行的过程中会自动创建输出路径,数据路径存在的话会报错,这里需要同学注意下.
[hadoop@node1 ~]$ hadoop jar /opt/bigdata/hadoop-3.1.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.2.jar wordcount /test/words /test/output
2019-06-30 17:32:23,685 INFO client.RMProxy: Connecting to ResourceManager at node1/192.168.200.11:18040
2019-06-30 17:32:24,060 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1561886252942_0001
2019-06-30 17:32:24,215 INFO input.FileInputFormat: Total input files to process : 1
2019-06-30 17:32:24,291 INFO mapreduce.JobSubmitter: number of splits:1
2019-06-30 17:32:24,394 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1561886252942_0001
2019-06-30 17:32:24,395 INFO mapreduce.JobSubmitter: Executing with tokens: []
2019-06-30 17:32:24,592 INFO conf.Configuration: resource-types.xml not found
2019-06-30 17:32:24,593 INFO resource.ResourceUtils: Unable to find ‘resource-types.xml‘.
2019-06-30 17:32:24,806 INFO impl.YarnClientImpl: Submitted application application_1561886252942_0001
2019-06-30 17:32:24,861 INFO mapreduce.Job: The url to track the job: http://node1:18088/proxy/application_1561886252942_0001/
2019-06-30 17:32:24,862 INFO mapreduce.Job: Running job: job_1561886252942_0001
2019-06-30 17:32:33,025 INFO mapreduce.Job: Job job_1561886252942_0001 running in uber mode : false
2019-06-30 17:32:33,030 INFO mapreduce.Job: map 0% reduce 0%
2019-06-30 17:32:39,174 INFO mapreduce.Job: map 100% reduce 0%
2019-06-30 17:32:43,229 INFO mapreduce.Job: map 100% reduce 100%
2019-06-30 17:32:43,266 INFO mapreduce.Job: Job job_1561886252942_0001 completed successfully
2019-06-30 17:32:43,369 INFO mapreduce.Job: Counters: 53
File System Counters
FILE: Number of bytes read=54
FILE: Number of bytes written=432335
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=116
HDFS: Number of bytes written=28
HDFS: Number of read operations=8
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3346
Total time spent by all reduces in occupied slots (ms)=2290
Total time spent by all map tasks (ms)=3346
Total time spent by all reduce tasks (ms)=2290
Total vcore-milliseconds taken by all map tasks=3346
Total vcore-milliseconds taken by all reduce tasks=2290
Total megabyte-milliseconds taken by all map tasks=3426304
Total megabyte-milliseconds taken by all reduce tasks=2344960
Map-Reduce Framework
Map input records=2
Map output records=6
Map output bytes=46
Map output materialized bytes=54
Input split bytes=93
Combine input records=6
Combine output records=5
Reduce input groups=5
Reduce shuffle bytes=54
Reduce input records=5
Reduce output records=5
Spilled Records=10
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=472
CPU time spent (ms)=1380
Physical memory (bytes) snapshot=492576768
Virtual memory (bytes) snapshot=5577179136
Total committed heap usage (bytes)=407371776
Peak Map Physical memory (bytes)=294256640
Peak Map Virtual memory (bytes)=2788634624
Peak Reduce Physical memory (bytes)=198320128
Peak Reduce Virtual memory (bytes)=2788544512
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=23
File Output Format Counters
Bytes Written=28
[hadoop@node1 ~]$ hdfs dfs -ls -r /test/output
Found 2 items
-rw-r--r-- 3 hadoop supergroup 28 2019-06-30 17:32 /test/output/part-r-00000
-rw-r--r-- 3 hadoop supergroup 0 2019-06-30 17:32 /test/output/_SUCCESS
[hadoop@node1 ~]$ hdfs dfs -text /test/output/part-r-00000
are 1
i 1
love 1
ok 1
you 2
[hadoop@node1 ~]$
至此三节点的hadoop集群环境搭建完成,谢谢大家能够有耐心的看完!

标签:min 认证 items ip修改 spool 地址栏 技术 check toc
原文地址:https://www.cnblogs.com/fushengliuyi/p/12801849.html