标签:分类 bsp 数据集 amp logistic 图片 预测 朝鲜语 好的
1.逻辑回归是怎么防止过拟合的?为什么正则化可以防止过拟合?(大家用自己的话介绍下)
答(1):
1. 增加样本量,这是万能的方法,适用任何模型。
2. 如果数据稀疏,使用L1正则,其他情况,用L2要好,可自己尝试。
3. 通过特征选择,剔除一些不重要的特征,从而降低模型复杂度。
4. 如果还过拟合,那就看看是否使用了过度复杂的特征构造工程,比如,某两个特征相乘/除/加等方式构造的特征,不要这样做了,保持原特征
5. 检查业务逻辑,判断特征有效性,是否在用结果预测结果等。
6.(补充)最总要的,逻辑回归特有的防止过拟合方法:进行离散化处理,所有特征都离散化。
答(2):
要拟合训练数据,就要足够大的模型空间;用了足够大的模型空间,挑选到测试性能 好的模型的概率就会下降。因此,就会出现训练数据拟合越好,测试性能越差的过拟合现象。
2.用logiftic回归来进行实践操作,数据不限。
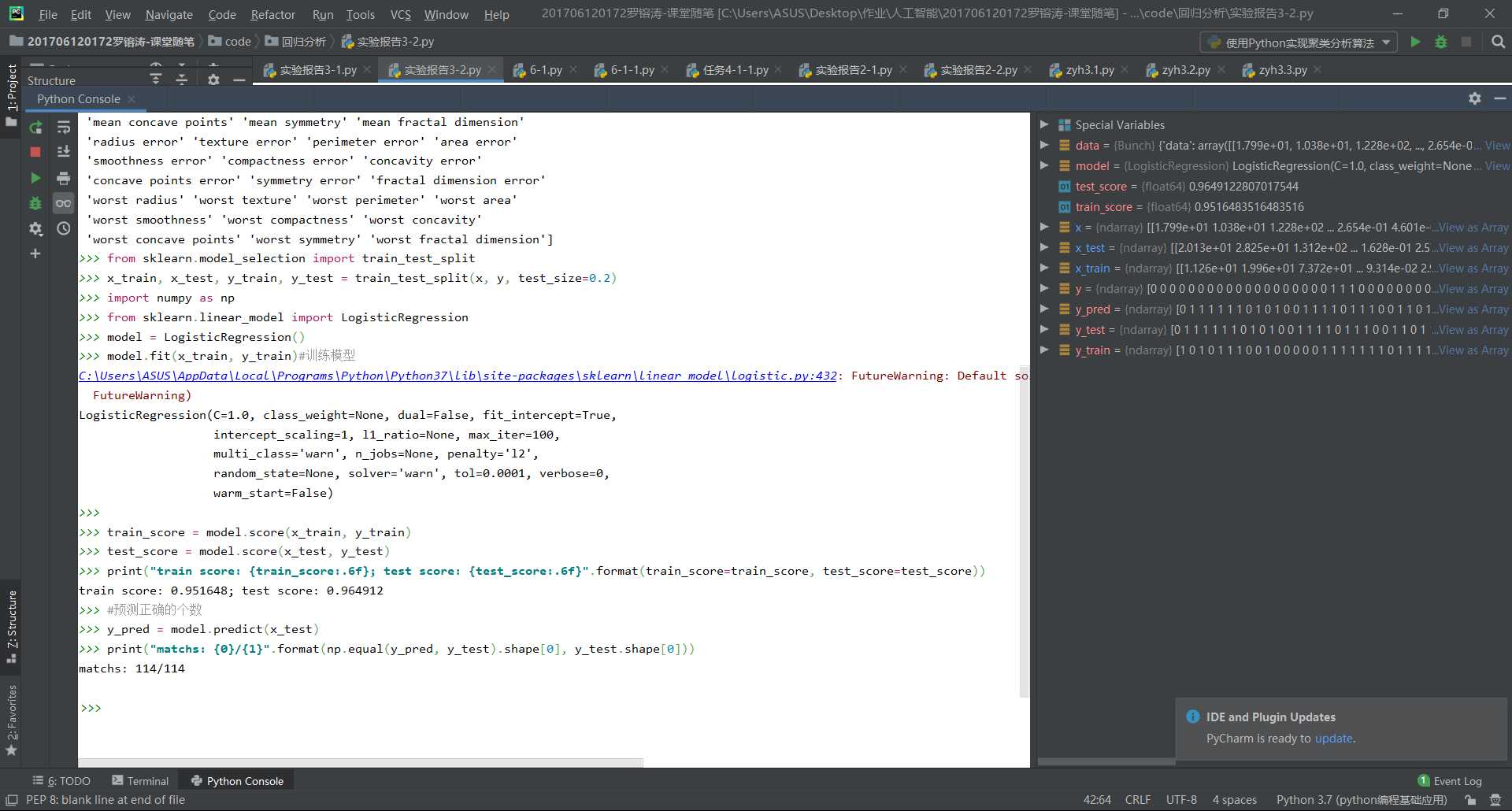
1 print(‘201706120172,罗镕涛,软件1702‘) 2 from sklearn.datasets import load_breast_cancer 3 from sklearn.model_selection import train_test_split 4 from sklearn.metrics import classification_report#分类报告 5 import pandas as pd 6 #加载数据集 7 data = load_breast_cancer()10 x = data[‘data‘] 11 y = data[‘target‘] 12 print("Shape of x: {0}; positive example: {1}; negative: {2}".format(x.shape, y[y==1].shape[0], y[y==0].shape[0])) # 查看数据的形状和类别分布 13 print("Cancer data feature name: ", data.feature_names) # 查看数据的特征 14 from sklearn.model_selection import train_test_split 15 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2) 16 import numpy as np 17 from sklearn.linear_model import LogisticRegression 18 19 model = LogisticRegression() 20 model.fit(x_train, y_train)#训练模型 21 22 train_score = model.score(x_train, y_train) 23 test_score = model.score(x_test, y_test) 24 print("train score: {train_score:.6f}; test score: {test_score:.6f}".format(train_score=train_score, test_score=test_score)) 25 #预测正确的个数 26 y_pred = model.predict(x_test) 27 print("matchs: {0}/{1}".format(np.equal(y_pred, y_test).shape[0], y_test.shape[0]))
翻译 朗读 复制 正在查询,请稍候…… 重试 朗读 复制 复制 朗读 复制 via 谷歌翻译(国内) 译
标签:分类 bsp 数据集 amp logistic 图片 预测 朝鲜语 好的
原文地址:https://www.cnblogs.com/moxiaomo/p/12804795.html