标签:lob 其他 ota osc 集成 sel ber 自动加载 clust
这篇文章将承接此前关于使用Prometheus配置自定义告警规则的文章。在本文中,我们将demo安装Prometheus的过程以及配置Alertmanager,使其能够在触发告警时能发送邮件,但我们将以更简单的方式进行这一切——通过Rancher安装。
专门配置运行指向Kubernetes集群的kubectl
有关kubectl的知识,因为我们可以使用Rancher UI
一个谷歌云平台账号(免费的即可),其他云也是一样的
Rancher v2.4.2(文章发布时的最新版本)
首先,启动一个Rancher实例。你可以根据Rancher的指引启动:
https://www.rancher.cn/quick-start/
使用Rancher来设置并配置一个Kubernetes集群。你可以访问下方链接获取文档:
https://rancher2.docs.rancher.cn/docs/cluster-provisioning/_index
我们将利用Rancher的应用商店来安装Prometheus。Rancher的应用商店主要集合了许多Helm Chart,以便于用户能够重复部署应用程序。
我们的集群起来并且开始运行之后,让我们在“Apps”的标签下选择为其创建的默认项目,然后单击“Launch”按钮。

现在我们来搜索我们感兴趣的chart。我们可以设置很多字段——但是对于本次demo来说我们将保留默认值。你可以在Detailed Description部分找到关于这些值的有用信息。无需担心出现问题,尽管去查看它们的用途。在页面底部,点击【Launch】。Prometheus Server以及Alertmanager将会被安装以及配置。
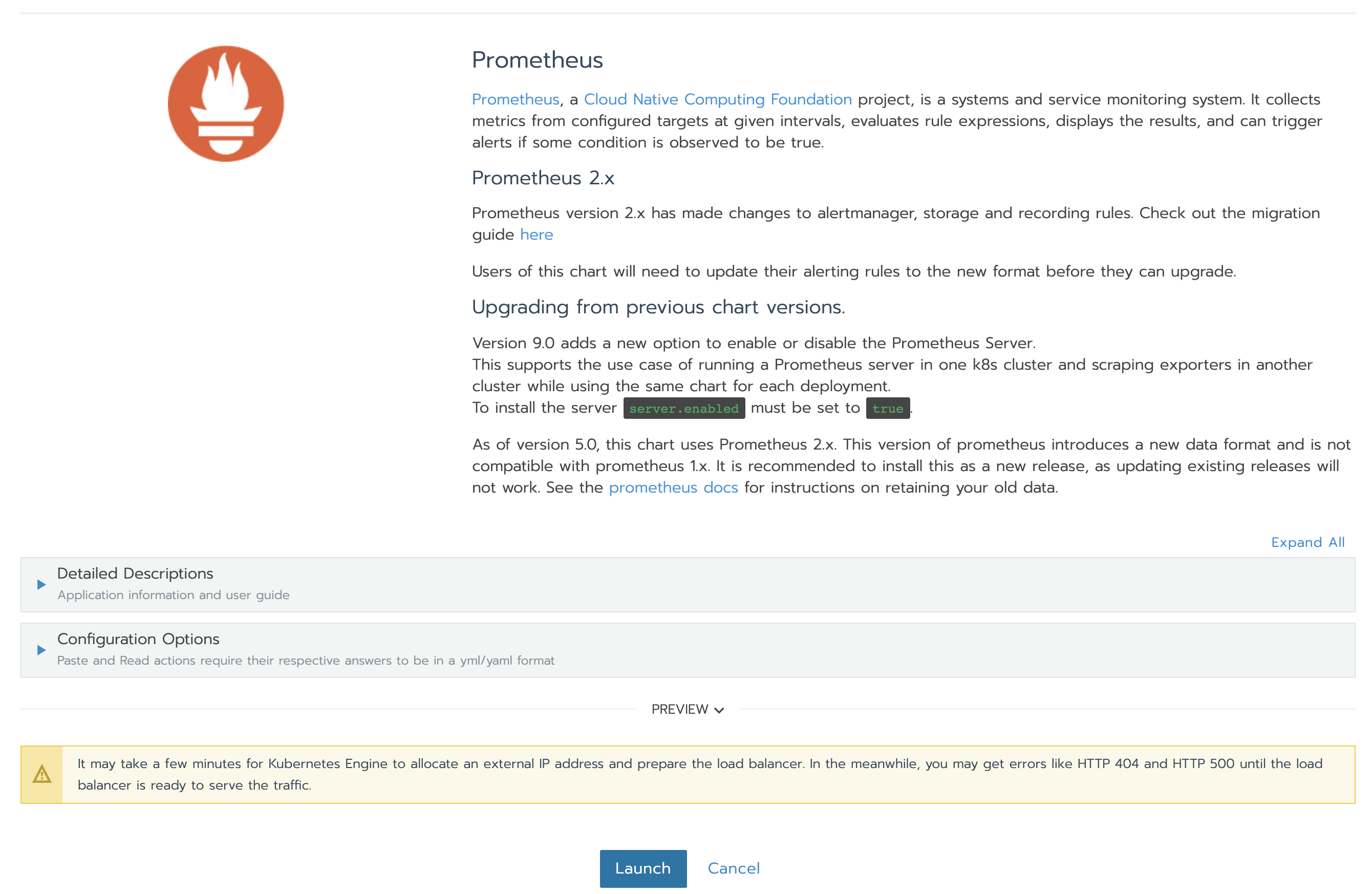
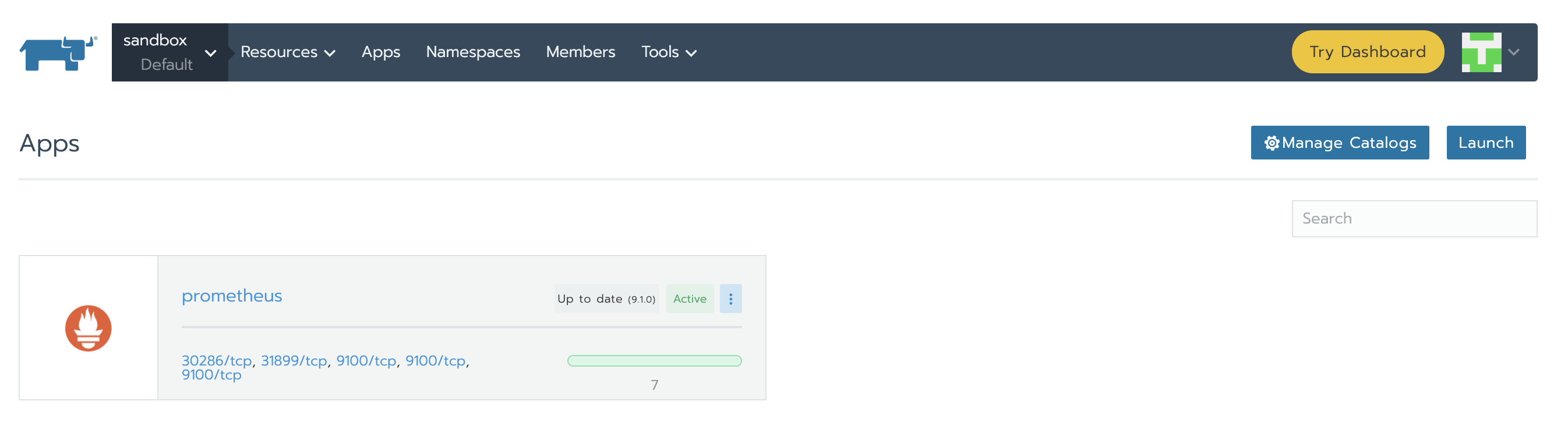
当安装完成时,页面如下所示:
接下来,我们需要创建Services以访问Prometheus Server以及Alertmanager。点开资源下方的工作负载标签,在负载均衡部分,我们可以看到目前还没有配置。点击导入YAML,选择prometheus namespace,一次性复制两个YAML并点击导入。稍后你将了解我们如何知道使用那些特定的端口和组件tag。
apiVersion: v1
kind: Service
metadata:
name: prometheus-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 9090
protocol: TCP
selector:
component: server
apiVersion: v1
kind: Service
metadata:
name: alertmanager-service
spec:
type: LoadBalancer
ports:
- port: 80
targetPort: 9093
protocol: TCP
selector:
component: alertmanager 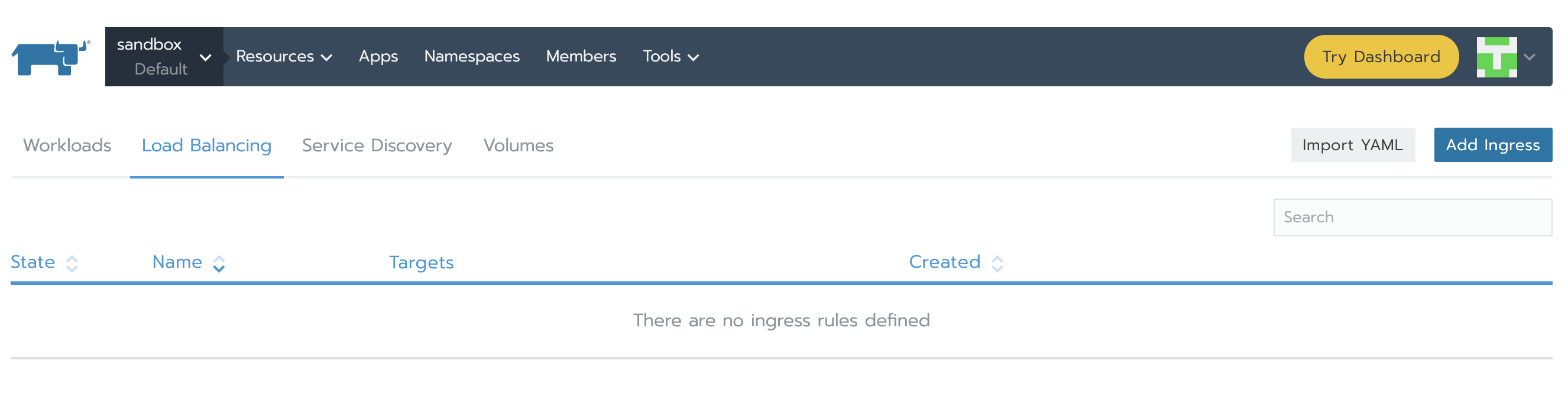
完成之后,service将显示Active。
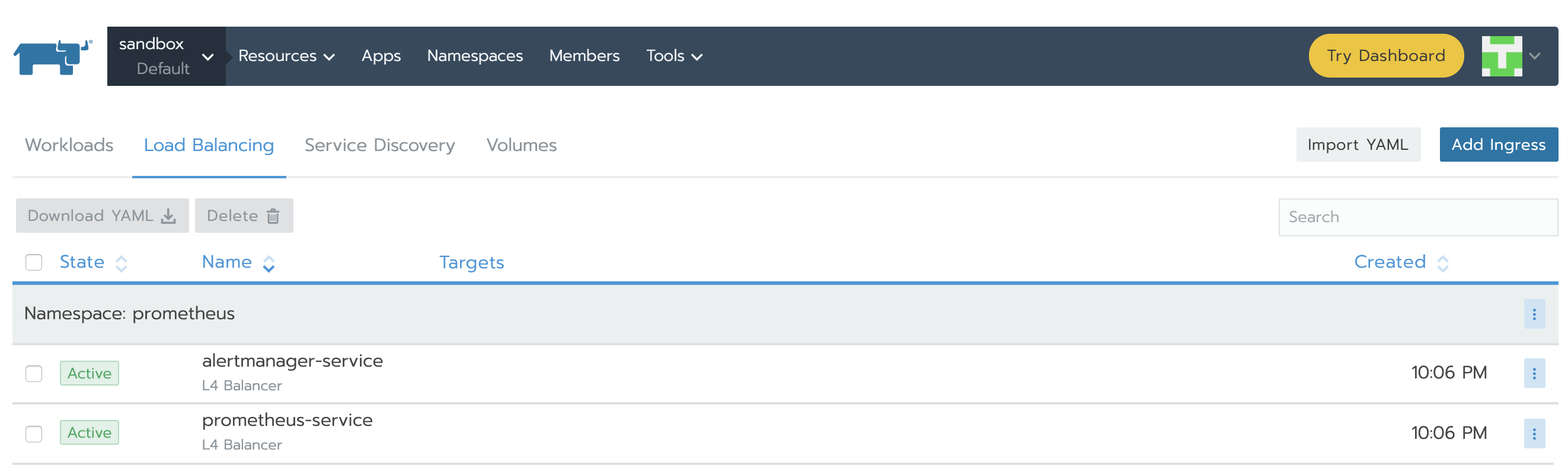
在右侧垂直省略号的下拉菜单里你能找到IP并点击View/Edit YAML。在yaml文件的底部,你将会看到类似的部分:
status:
loadBalancer:
ingress:
- ip: 34.76.22.14
访问IP将为我们展示Prometheus Server和Alertmanager的GUI。你会发现这时没有什么内容可以查看的,因为尚未定义规则以及配置告警。
规则可以让我们触发告警。这些规则都是基于Prometheus的表达式语言。无论何时,只要符合条件,告警就会被触发并发送给Alertmanager。
现在来看看我们如何添加规则。
在资源->工作负载标签下,我们可以看到Deployment在运行chart时创建了什么。我们来详细看看prometheus-server和prometheus-alertmanager。
我们从第一个开始并理解其配置,我们如何编辑它并了解服务在哪个端口上运行。点击垂直省略号菜单按钮并点击View/Edit YAML。
首先,我们看到的是两个与Deplolyment关联的容器:prometheus-server-configmap-reload和prometheus-server。容器prometheus-server的专属部分有一些相关信息:
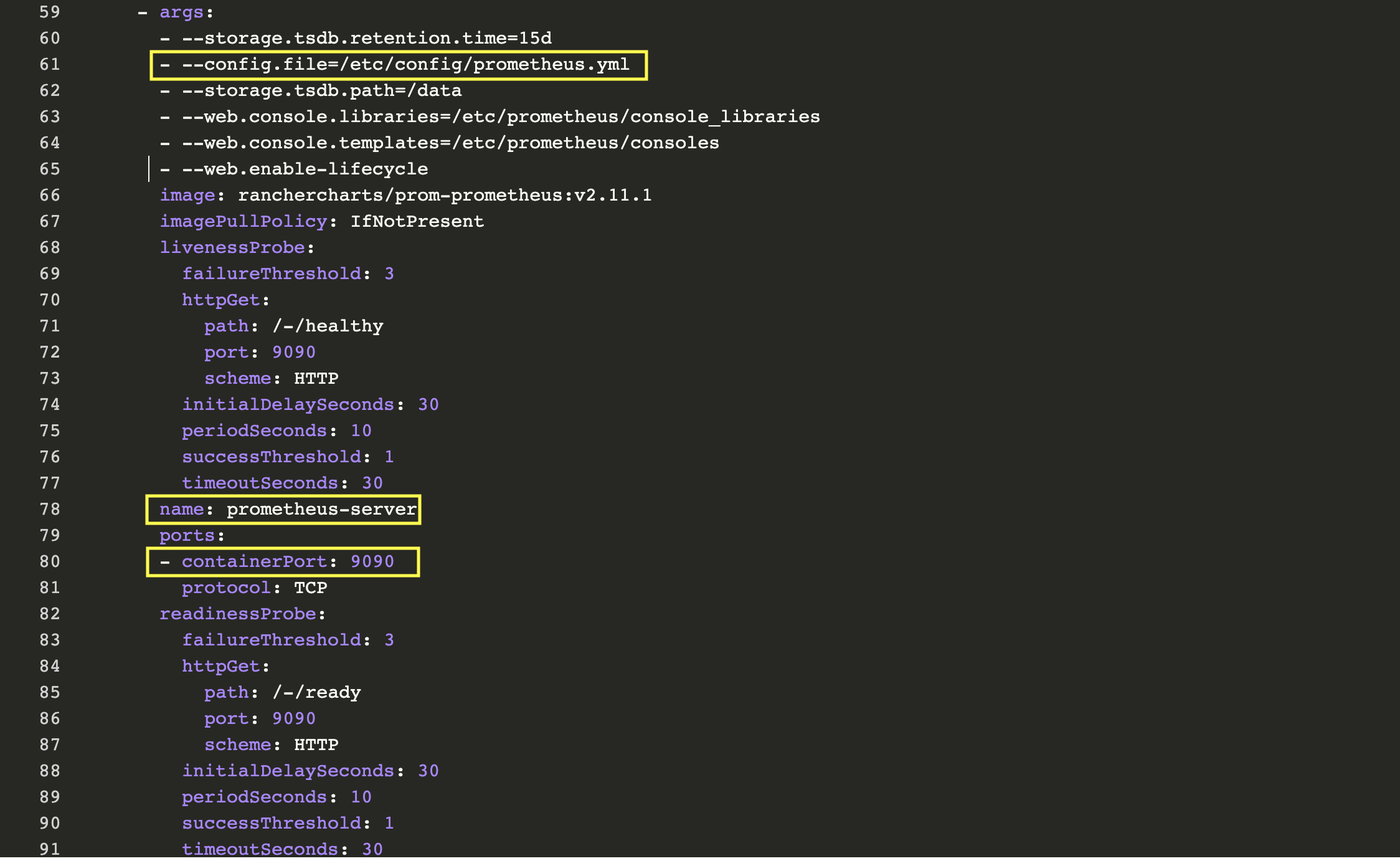
正如我们所了解的,Prometheus通过prometheus.yml进行配置。该文件(以及其他在serverFiles中列出的文件)将挂载到server pod。为了添加/编辑规则,我们需要修改这个文件。实际上,这就是一个Config Map,可以在Resources Config的标签页下找到。点击垂直的省略菜单按钮并Edit。在规则部分,让我们添加新的规则并点击保存。
groups:
- name: memory demo alert
rules:
- alert: High Pod Memory
expr: container_memory_usage_bytes{pod_name=~"nginx-.*", image!="", container!="POD"} > 5000000
for: 1m
labels:
severity: critical
annotations:
summary: High Memory Usage
- name: cpu demo alert
rules:
- alert: High Pod CPU
expr: rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m]) > 0.04
for: 1m
labels:
severity: critical
annotations:
summary: High CPU Usage 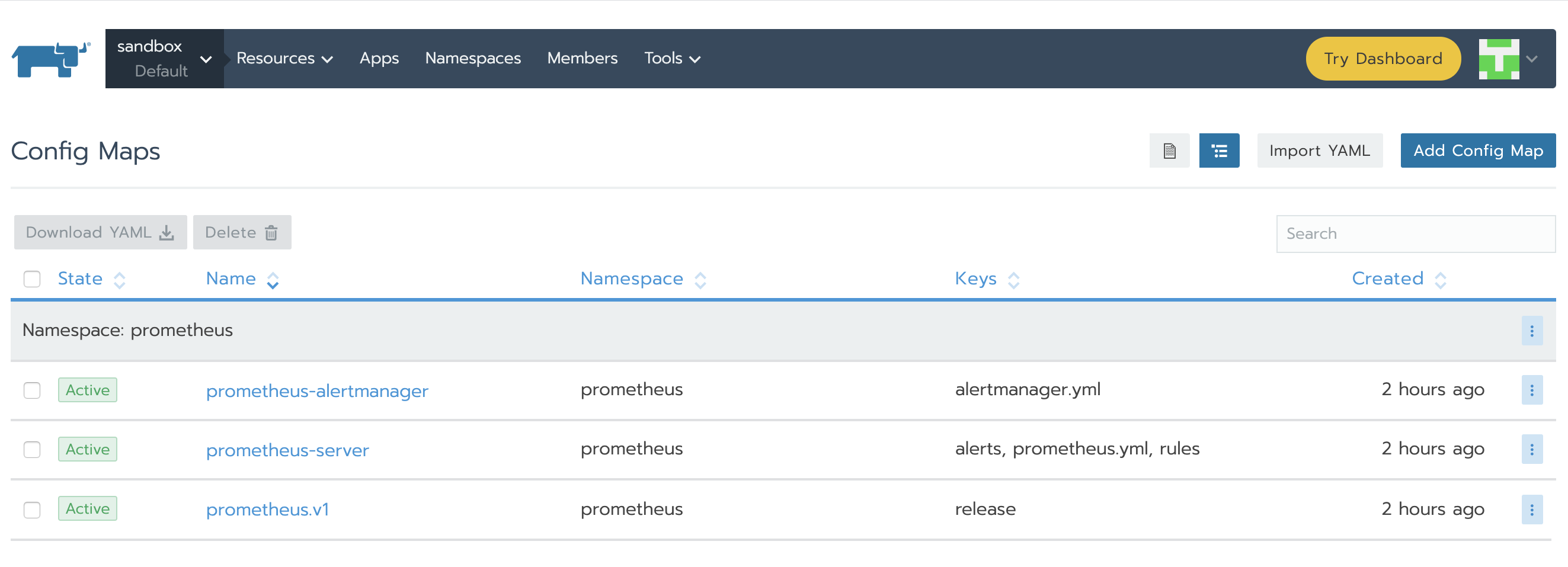
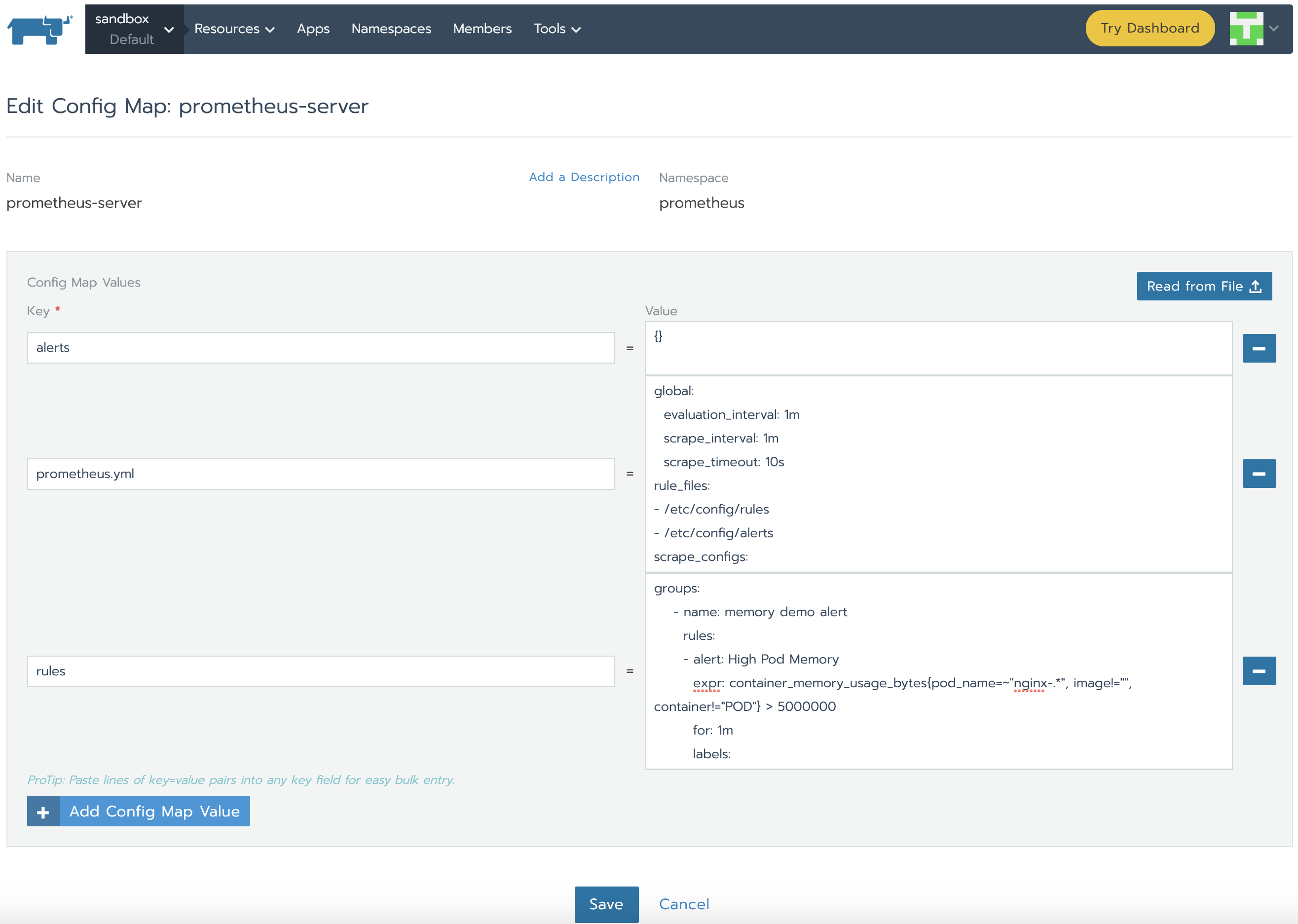
规则将会由Prometheus Server自动加载,然后我们在Prometheus Server GUI中能看到它们:
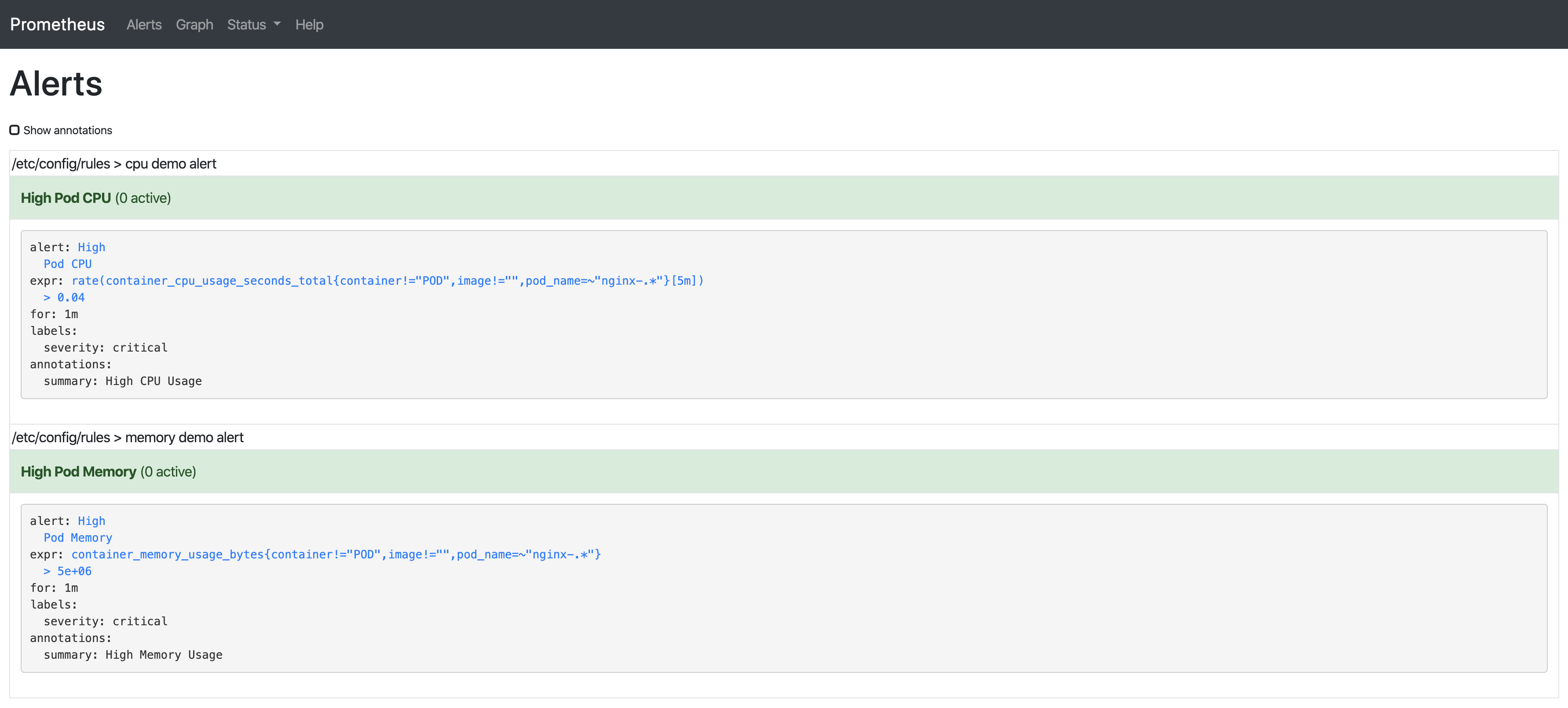
这是关于以上两条规则的解释:
container_memory_usage_bytes:当前内存使用情况(以字节为单位),包括所有内存,无论任何时候访问。
container_cpu_usage_seconds_total:累积的CPU时间(以秒为单位)
所有的指标都能够在以下页面中找到:
https://github.com/google/cadvisor/blob/master/metrics/prometheus.go
在Prometheus中所有正则表达式都使用RE2 syntax。使用正则表达式,我们只能为名称与特定模式匹配的Pod选择时间序列。在我们的示例中,我们需要寻找以nginx-开头的pod,并且排除“POD”,因为这是容器的父cgroup,而且会显示pod内所有容器的统计信息。
对于container_cpu_usage_seconds_total来说,我们使用所谓的子查询(Subquery)。它会每5分钟返回我们的指标。
如果你想了解更多关于查询以及例子,可以在官方的Prometheus文档中查看。
只要出现问题,告警就能立即提醒我们,使得我们能够立刻知道系统中发生了错误。而Prometheus通过Alertmanager组件来提供告警。
与Prometheus Server的操作步骤相同:在资源->工作负载标签页下,点击prometheus-alertmanager右侧菜单栏按钮,选择View/Edit YAML,检查其配置:
Alertmanager通过alertmanager.yml进行配置。该文件(及其他列在alertmanagerFiles内的文件)将挂载到alertmanager pod上。接下来我们需要修改与alertmanager相关联的configMap以便于设置告警。在Config标签页下,点击prometheus-alertmanager行的菜单栏,然后选择Edit。使用以下代码代替基本配置:
global:
resolve_timeout: 5m
route:
group_by: [Alertname]
# Send all notifications to me.
receiver: demo-alert
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
routes:
- match:
alertname: DemoAlertName
receiver: "demo-alert"
receivers:
- name: demo-alert
email_configs:
- to: your_email@gmail.com
from: from_email@gmail.com
# Your smtp server address
smarthost: smtp.gmail.com:587
auth_username: from_email@gmail.com
auth_identity: from_email@gmail.com
auth_password: 16letter_generated token # you can use gmail account password, but better create a dedicated token for this
headers:
From: from_email@gmail.com
Subject: "Demo ALERT" 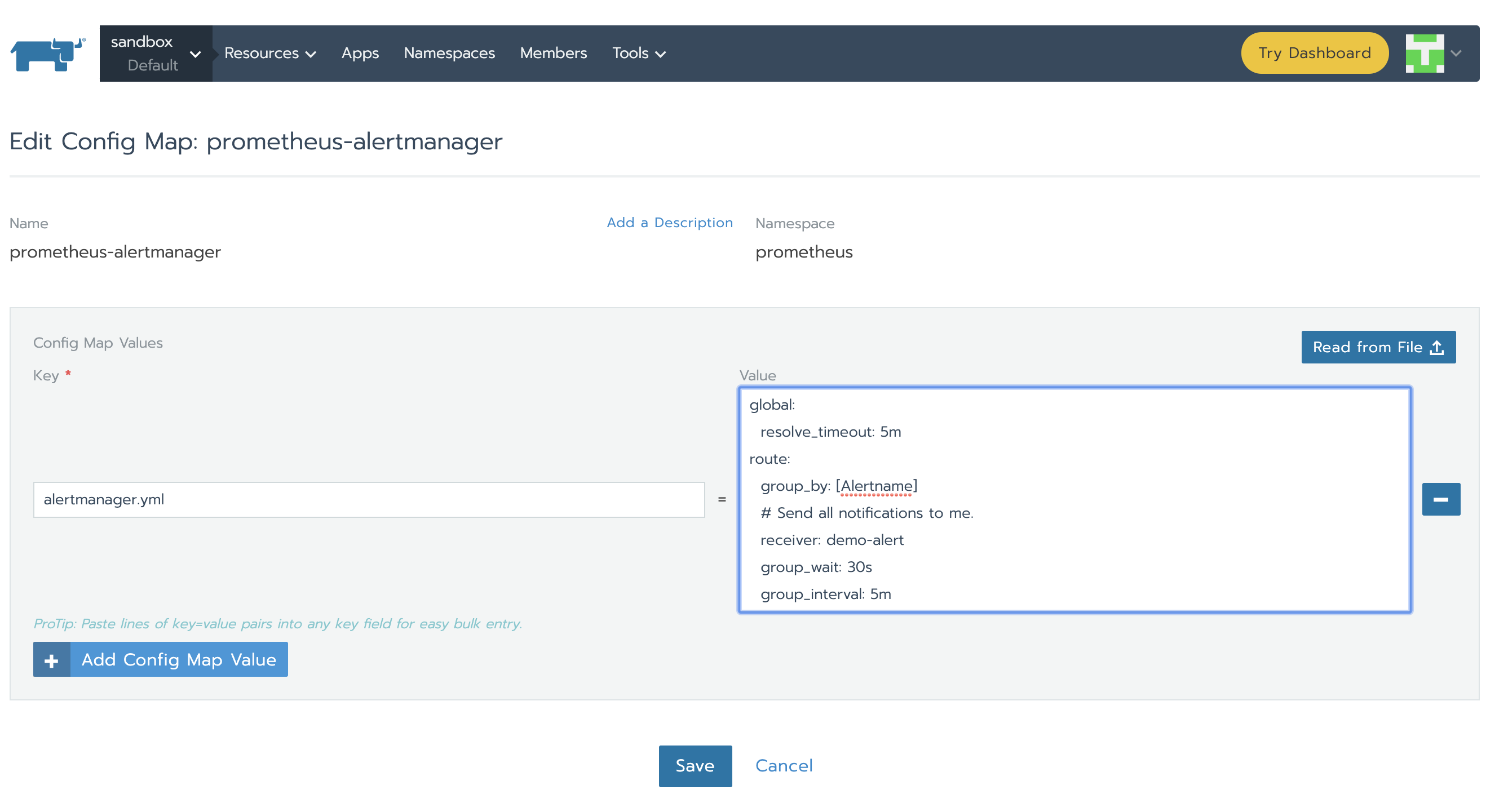
新配置将会由Alertmanager重新加载,并且我们能在Status标签页下看到GUI。
让我们部署一些组件来进行监控。对于练习来说部署一个简单的nginx deployment就足够了。使用Rancher GUI,在资源->工作负载标签页下点击导入YAML,粘贴以下代码(本次使用默认的命名空间)并点击导入:
apiVersion: apps/v1 # for versions before 1.9.0 use apps/v1beta2
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 3 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80 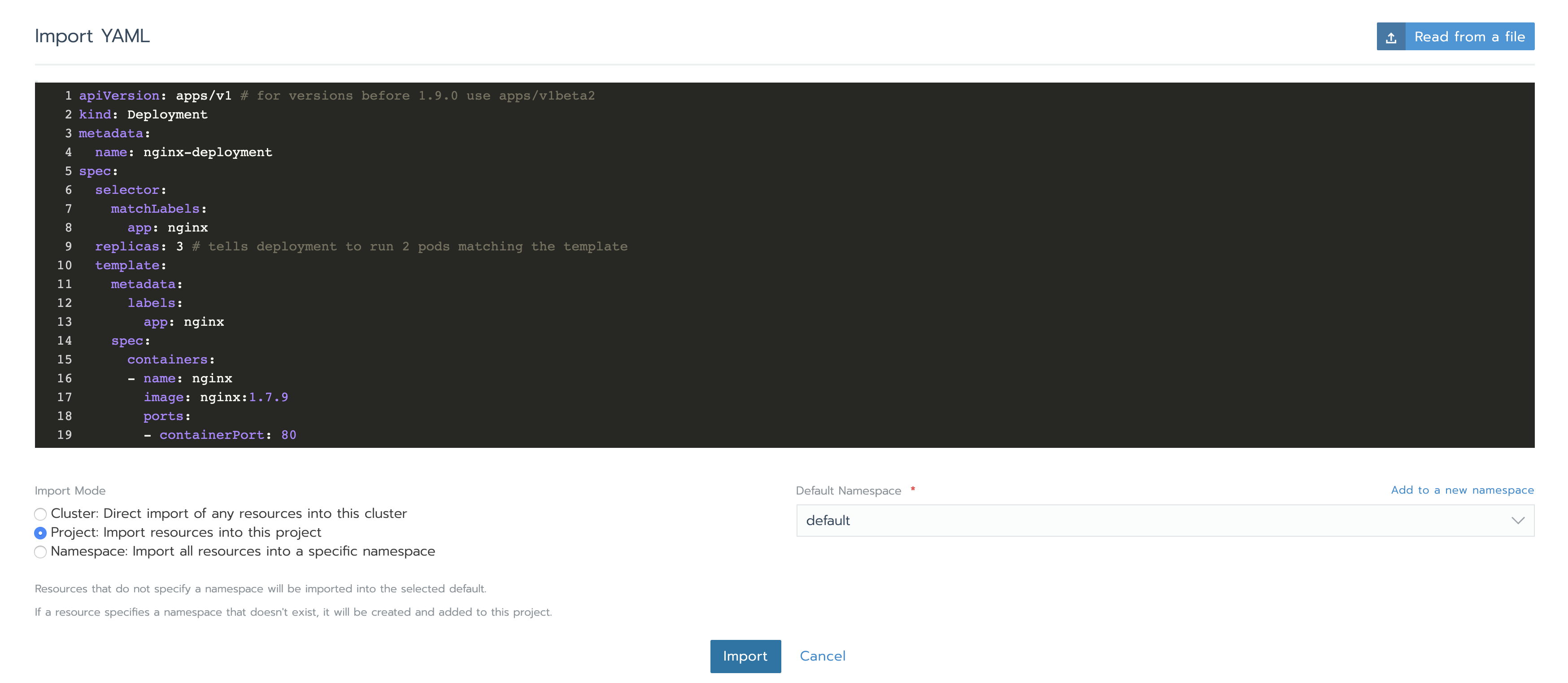
在Prometheus UI中,我们为使用此前为告警配置的两个表达式中的1个来查看一些指标:
rate (container_cpu_usage_seconds_total{pod_name=~"nginx-.*", image!="", container!="POD"}[5m]) 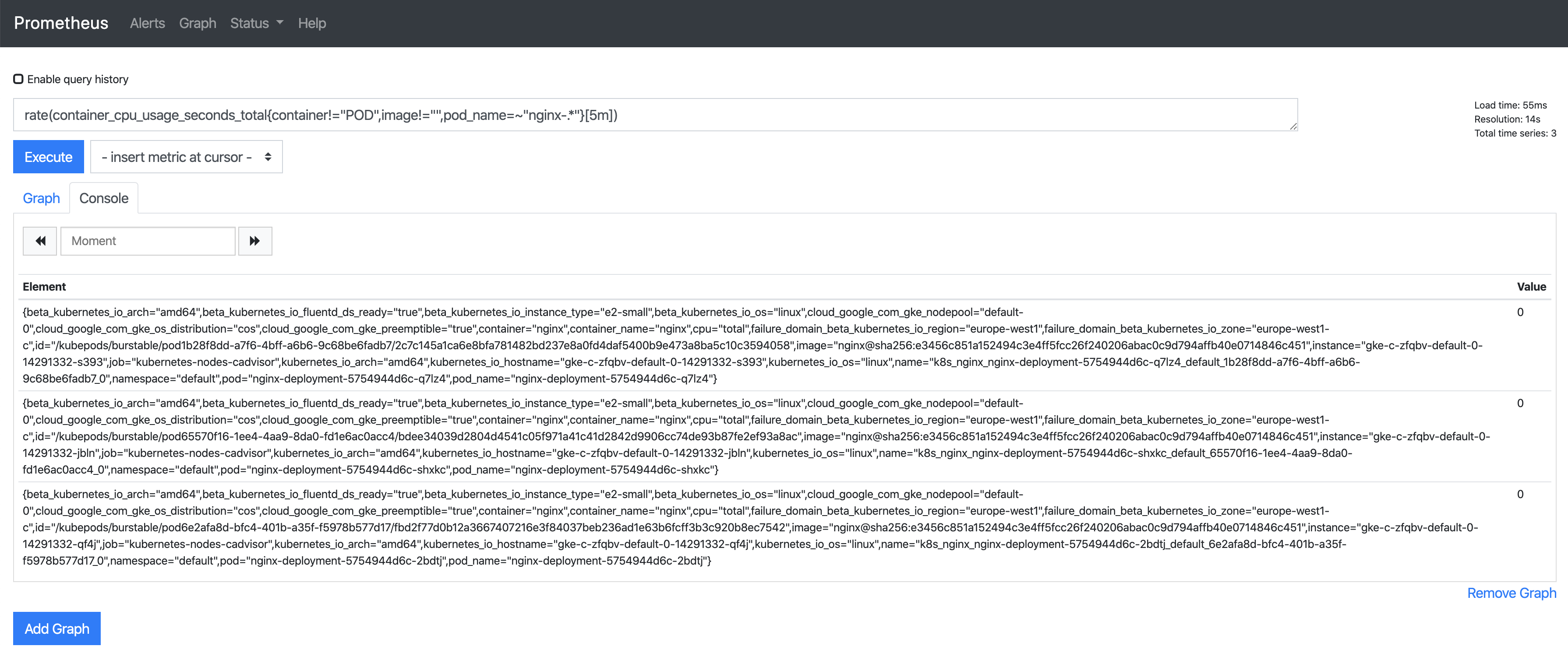
让我们在其中一个Pod中添加一些负载以查看值的变化。当值大于0.04时,我们应该获得告警。为此,我们需要选择其中一个nginx Deployment Pod并点击Execute Shell。在其中我们将执行一个命令:
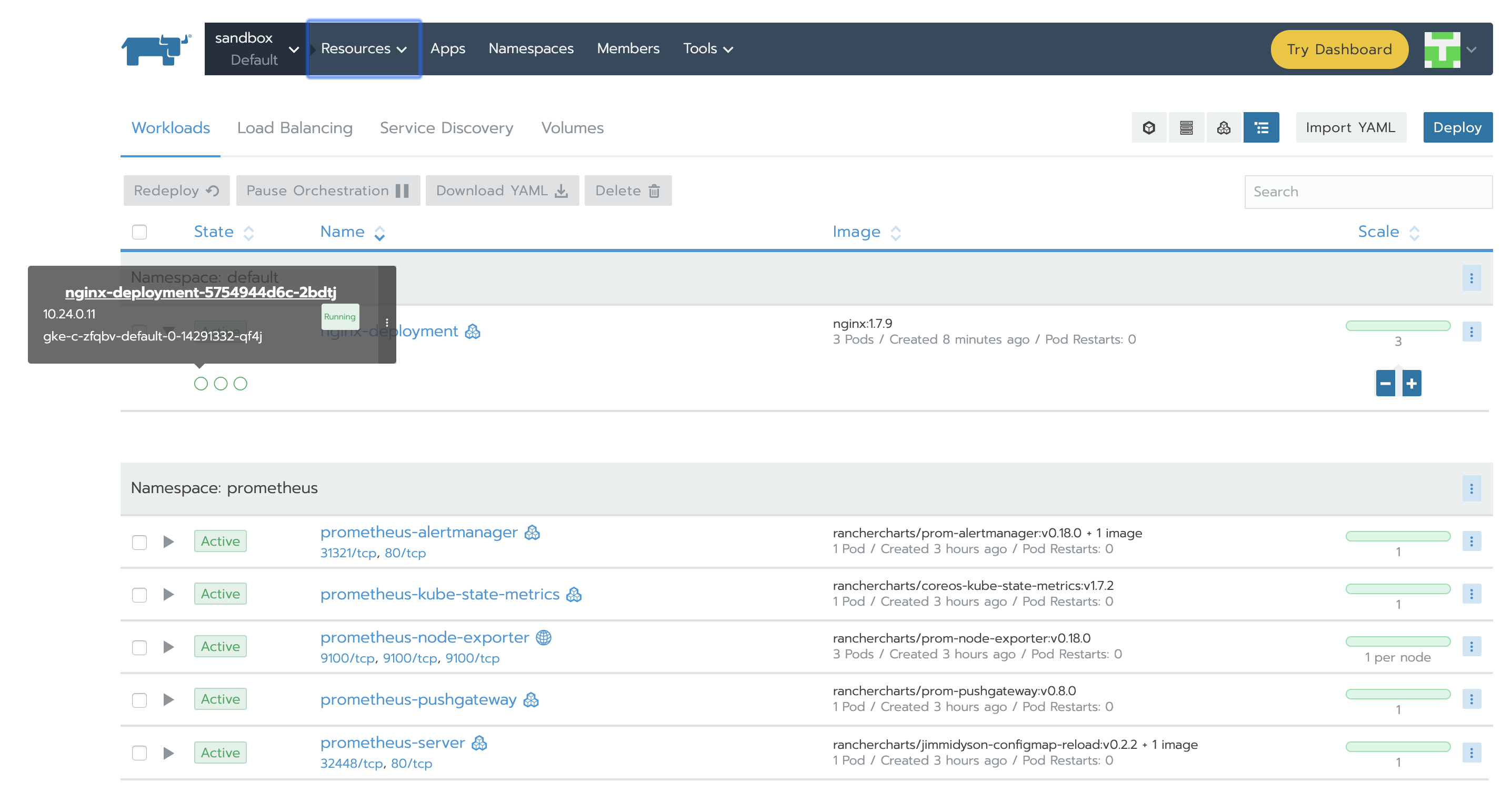

告警有3个阶段:
Inactive-条件不满足
Pending-满足条件
我们已经看到告警处于inactive状态,所以继续在CPU上增加负载让我们能观察到剩余两种状态:
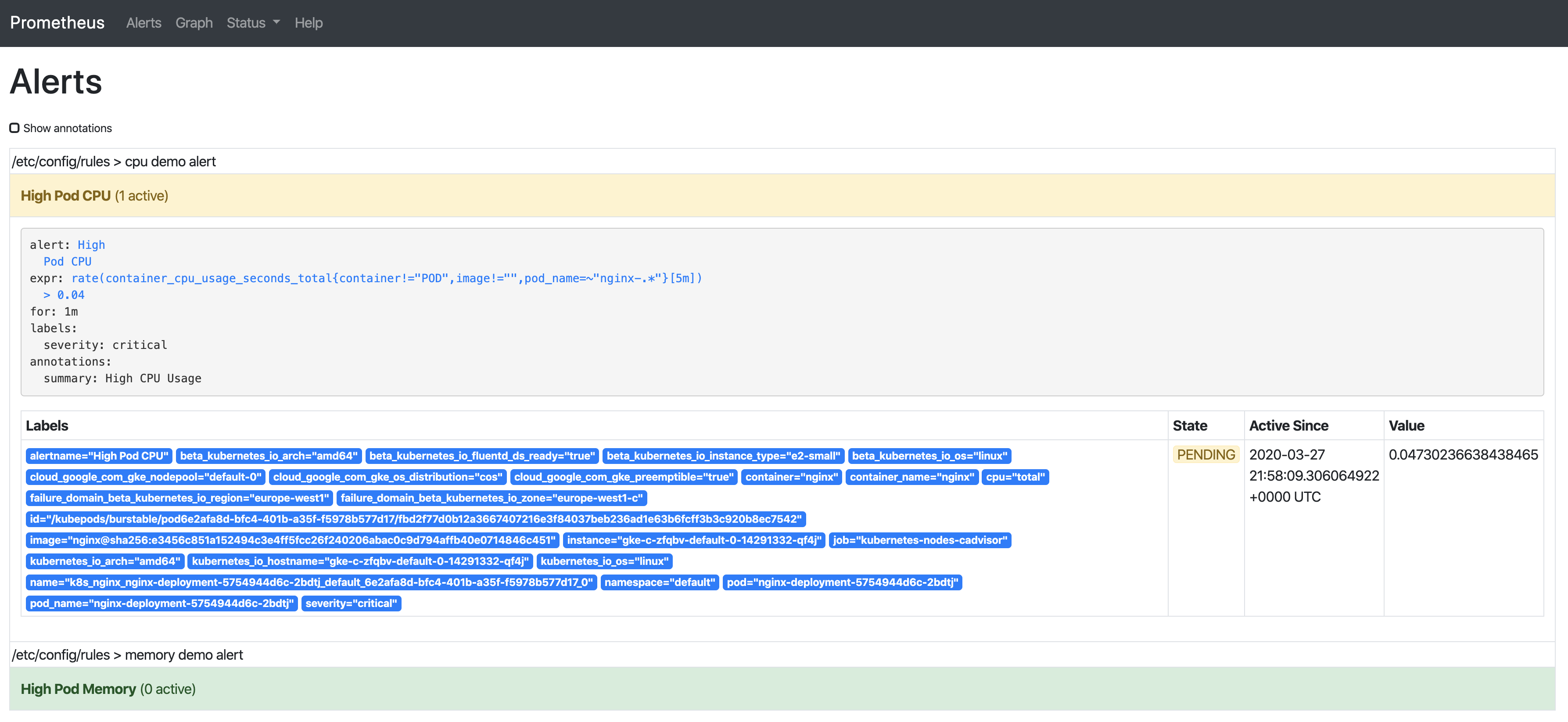
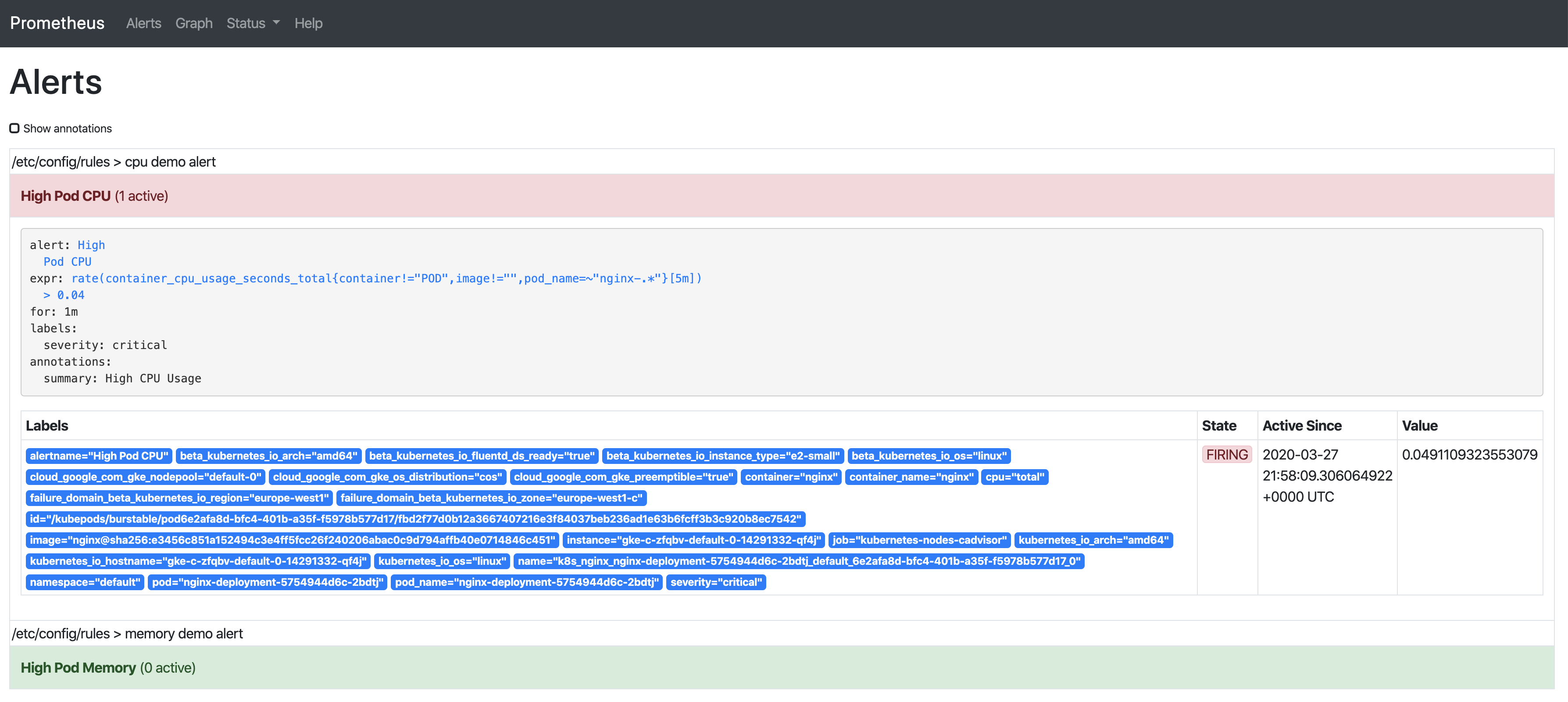
只要告警触发,将会显示在Alertmanager中:
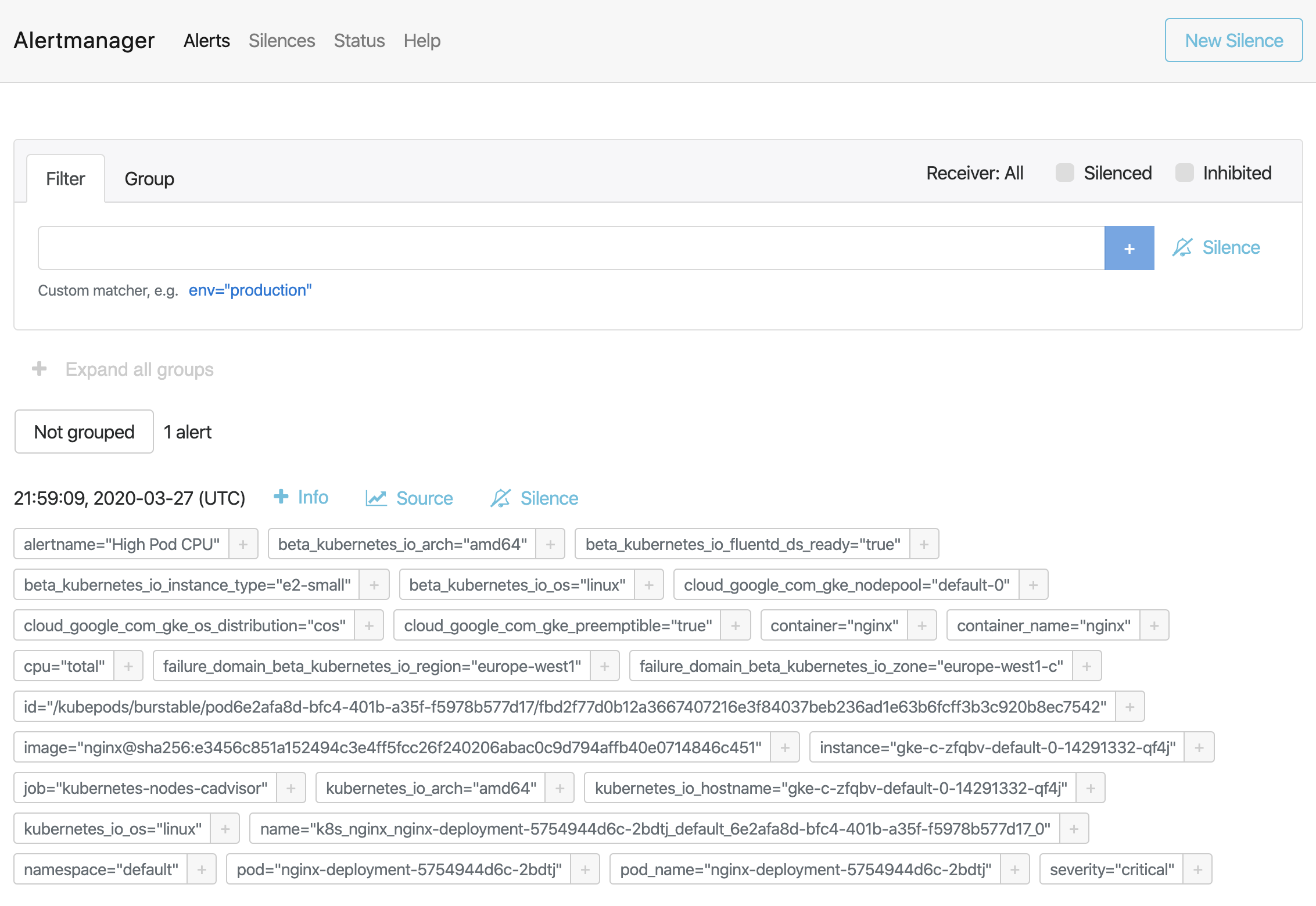
将Alertmanager配置为在我们收到告警时发送电子邮件。如果我们查看收件箱,则会看到类似的内容:

我们都知道监控在整个运维过程中多么重要,但是如果没有告警,监控是不完整的。告警可以在问题发生时,然后我们立刻知道系统中出现了问题。Prometheus囊括了这两种功能:监控解决方案以及其Alertmanager组件的告警功能。本文中我们看到了使用Rancher部署Prometheus如此容易并且将Prometheus Server与Alertmanager集成。我们还使用Rancher配置了告警规则并推送了Alertmanager的配置,所以它能在问题发生时提醒我们。最后,我们了解了如何根据Alertmanager的定义/集成收到一封包含触发告警详细信息的电子邮件(也可以通过Slack或PagerDuty发送)。
标签:lob 其他 ota osc 集成 sel ber 自动加载 clust
原文地址:https://blog.51cto.com/12462495/2491983