标签:通过 相同 概念 flush family 切分 实时 服务器 均衡
HBase分布式数据库,面向列存储(准确的说是面向列族),支持实时、随机读写。HDFS 为 Hbase 提供可靠的底层数据存储服务,MapReduce 为 Hbase 提供高性能的计算能力,Zookeeper 为 Hbase 提供
稳定服务和Failover机制,因此,Hbase 是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
列式存储的好处:由于查询中的选择规则是通过列来定义的,因此整个数据库是自动索引化的。
Hbase根据列族来存储数据的,每个列族可以包含任意多的列,列族在创建表的时候就必须指定。像关系型数据库创建的时候必须指定具体的列是一样的。Hbase 的列族不是越多越好,官方推荐列族最好小于或者等于 3。我们使用的场景一般是1个列族
Rowkey类似mysql中的主键,Hbase使用Rowkey来唯一的区分某一行的数据。
完全是由用户指定的一串不重复的字符串;HBase中的数据永远是根据Rowkey的字典排序来排序的。
Hbase只支持3中查询方式:基于Rowkey的单行查询,基于Rowkey的范围扫描,全表扫描。
RowKey的作用:
读写数据时通过RowKey找到对应的Region;
MemStore中的数据按RowKey字典顺序排序;
HFile中的数据按RowKey字典顺序排序。
Rowkey对Region划分影响:
HBase 表的数据是按照 Rowkey 来分散到不同 Region,不合理的 Rowkey 设计会导致热点问题。热点问题是大量的 Client 直接访问集群的一个或极少数个节点,而集群中的其他节点却处于相对空闲状态。
Rowkey设计规则:
1)rowkey 长度原则
2)rowkey 散列原则
3)rowkey 唯一原则
Rowkey设计技巧:
1)生成随机数、hash、散列值
2)字符串反转
如何避免上面说到的热点问题呢?
避免热点的方法 - Salting
避免热点的方法 - Hashing
避免热点的方法 - Reversing
RowKey的长度
RowKey 可以是任意的字符串,最大长度64KB(因为 Rowlength 占2字节)。建议越短越好,原因如下:
数据的持久化文件HFile中是按照KeyValue存储的,如果rowkey过长,比如超过100字节,1000w行数据,光rowkey就要占用100*1000w=10亿个字节,将近1G数据,这样会极大影响HFile的存储效率;
MemStore将缓存部分数据到内存,如果rowkey字段过长,内存的有效利用率就会降低,系统不能缓存更多的数据,这样会降低检索效率;
目前操作系统都是64位系统,内存8字节对齐,控制在16个字节,8字节的整数倍利用了操作系统的最佳特性。
HBase Rowkey设计指南
Region类似关系型数据库的分区或者分片。Hbase将一个大表的数据基于Rowkey的不同范围分配到不同的Region中,每个Region负责一定范围的数据访问和存储。一张巨大的表,由于被切割到不通的region,访问起来时延也很低。
TimeStamp是实现Hbase多版本的关键。在Hbase中使用不同的timestame来标识相同rowkey行对应的不通版本的数据。在写入数据的时候,如果用户没有指定对应的timestamp,Hbase会自动添加一个timestamp,timestamp 和服务器时间保持一致。在Hbase中,相同rowkey的数据按照timestamp倒序排列。默认查询的是最新的版本,用户可指定timestamp的值来读取旧版本的数据。
注意:HBase中存储的数据都是字符串,没有数据类型;HBase可以保留多个版本是因为,HBase存储底层依赖于HDFS,HDFS只允许追加数据,不允许对数据进行部分修改。
Hbase由Client、Zookeeper、Master、HRegionServer、HDFS等组件组成。
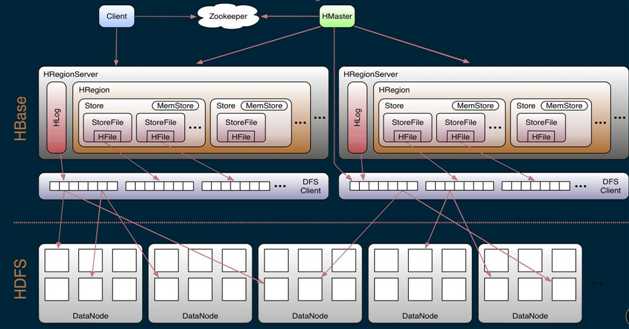
Client包含了访问Hbase的接口,同时在cache缓存中维护着已经访问过的Region位置信息,用来加快后续数据访问过程,比如cache的.META.元数据的信息。
Hbase通过Zookeeper来做master的高可用、RegionServer 的监控、元数据的入口以及集群配置的维护等工作。具体工作如下:
主服务器master主要负责表和Region的管理工作:
HregionServer是HBase最核心的模块,负责维护分配给自己的Region,并直接响应用户的读写请求,是真正的“干活”的节点。它的功能概括如下:
第 1 步:Client请求ZK获取.META.所在的RegionServer的地址。
第 2 步:Client请求.META.所在的RegionServer获取访问数据所在的RegionServer地址,client会将.META.的相关信息cache下来,以便下一次快速访问。
第 3 步:Client请求数据所在的RegionServer,获取所需要的数据。
HDFS为Hbase提供最终的底层数据存储服务,同时为Hbase提供高可用(Hlog存储在HDFS)的支持。
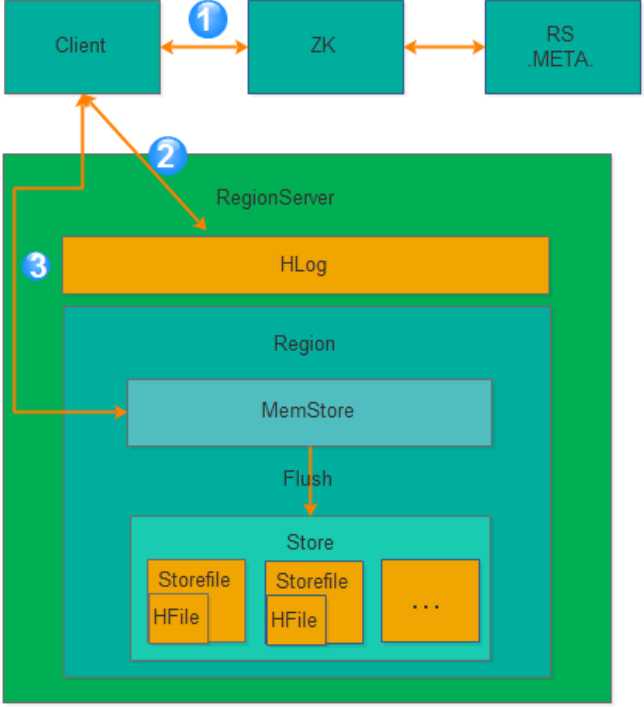
获取 RegionServer
第 1 步:Client 获取数据写入的 Region 所在的 RegionServer
请求写 Hlog
第 2 步:请求写 Hlog, Hlog 存储在 HDFS,当 RegionServer 出现异常,需要使用 Hlog 来
恢复数据。
请求写 MemStore
第 3 步:请求写 MemStore,只有当写 Hlog 和写 MemStore 都成功了才算请求写入完成。
MemStore 后续会逐渐刷到 HDFS 中。
为了提高 Hbase 的写入性能,当写请求写入 MemStore 后,不会立即刷盘。而是会等到一定的时候进行刷盘的操作。具体是哪些场景会触发刷盘的操作呢?总结成如下的几个场景:
全局内存控制
MemStore 达到上限
2. 当 MemStore 的大小达到 hbase.hregion.memstore.flush.size 大小的时候会触发刷盘,默认 128M 大小
RegionServer 的 Hlog 数量达到上限
3. 前面说到 Hlog 为了保证 Hbase 数据的一致性,那么如果 Hlog 太多的话,会导致故障恢复的时间太长,因此 Hbase 会对 Hlog 的最大个数做限制。当达到 Hlog 的最大个数的时候,会强制刷盘。这个参数是 hase.regionserver.max.logs,默认是 32 个。
手工触发
4. 可以通过 hbase shell 或者 java api 手工触发 flush 的操作。
关闭 RegionServer 触发
5. 在正常关闭 RegionServer 会触发刷盘的操作,全部数据刷盘后就不需要再使用 Hlog 恢复数据。
Region 使用 HLOG 恢复完数据后触发
6. 当 RegionServer 出现故障的时候,其上面的 Region 会迁移到其他正常的RegionServer 上,在恢复完 Region 的数据后,会触发刷盘,当刷盘完成后才会提供给业务访问。
标签:通过 相同 概念 flush family 切分 实时 服务器 均衡
原文地址:https://www.cnblogs.com/eugene0/p/11574884.html