标签:log network 方法 校正 eval rman 限制 修改 ima
Chenguang Zhu
Microsoft Speech and Dialogue Research Group
提高生成式文本摘要的事实准确性
(Extractive and Abstractive Summarization 分别是抽取式和生成式)
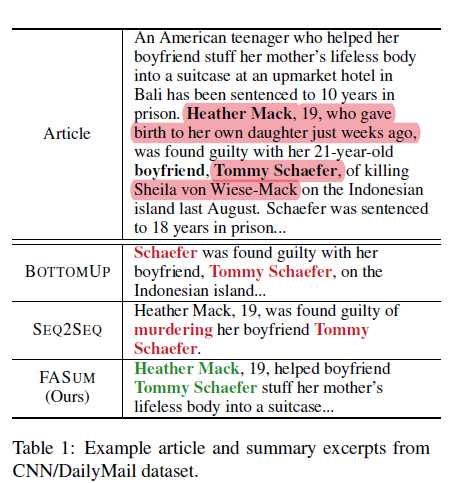

在实验中,我们利用了经过独立训练的,基于BERT的(Devlin等人,2018)事实正确性评估器(Kry′sci′nski等人,2019b)。结果显示,在CNN / DailyMail上,FASUM的事实正确性得分比UNILM(Dong等,2019)高1.2%,比BOTTOMUP(Gehrmann等,2018)高4.5%。 此外,通过FC校正后,BOTTOMUP的摘要的实际分数在CNN / DailyMail上增加了1.7%,在XSum上增加了1.2%,而TCONVS2S的摘要的分数在XSum上增加了3.9%。 我们还将进行人工评估,以验证我们模型的有效性。
在最近的文献中,对生成式文本摘要进行了深入研究。 大多数模型采用编解码器架构(seq2seq)(Sutskever等,2014)。Rush等(2015)为Abstract引入了基于注意力的seq2seq模型。参见等。(2017)使用复制生成机制,既可以通过生成器从词汇表中生成单词,也可以通过指针从文章中复制单词。 Paulus等。(2017)利用强化学习来提高摘要质量。 Gehrmann等。 (2018)使用内容选择器过度确定源文档中的短语,这有助于将模型约束到可能的短语。 朱等。 (2019)为摘要定义了预训练方案,并产生了zero-shot抽象摘要模型。 董等。 (2019)在NLP中为分类和生成任务采用了不同的掩蔽技术。生成的预训练模型UNILM在包括抽象摘要在内的各种任务上获得了最新的结果。
由于判断摘要与文章是否一致的任务类似于文本蕴涵问题,因此,最近的一些工作使用文本蕴涵模型来评估和增强摘要的事实正确性。Li等(2018)对编码器的摘要和蕴涵进行了训练,并采用了蕴涵感知的解码器。Falke等(2019)建议使用现成的蕴含模型对候选简要句子进行重新排名,以提高事实正确性。除了使用蕴含模型来确保事实的正确性外,Zhang等人。 (2019b)处理了医学领域中的事实正确性问题,其中事实的空间有限并且可以用描述符向量来描述。 提出的模型利用信息提取和强化学习。 曹等。 (2018)从文章中提取关系信息并将其映射到序列,作为编码器的附加输入。 Gunel等。 (2019)使用了一个实体感知的transformer结构来提高抽象总结中的事实正确性,其中实体来自Wikidata知识图。 相比之下,我们的模型利用从文章中提取的知识图,并通过图神经计算将其融合到生成的文本中。
为了评估摘要的事实正确性,Kry′sci′nski等人。 (2019a)依赖于人类标签,而Goodrich等(2019) (2019)建议使用提取的关系元组。 张等。 (2019a)使用BERT计算摘要和文章中的成对单词之间的相似度。Wang等。(2020)使用问答的准确性来衡量。 Kry′sci′nski等。 (2019b)将事实正确性描述为二元分类问题:摘要与文章一致或不一致。 它对摘要应用了正向和负向转换,以生成基于BERT的分类模型的训练数据。 评估人员FactCC的性能明显优于以前的模型,并且与人类指标高度相关。 因此,我们使用FactCC作为模型的事实评估者。
值得注意的是,事实感知摘要与事实验证相关但并不相同(Vlachos和Riedel,2014; Nadeem等,2019)。
在提出claim的事实验证中,需要从各种媒体来源检索相关文档,评估可信度并预测每篇文章的立场。 在了解事实的摘要中,摘要需要忠实地重申给定文章的内容。 此外,基于事实的摘要是一项生成任务,而基于事实的验证则是一项辨别任务。

其实就是数据集:(文章,摘要)的数据对。给文章,输出摘要。每个文章或者摘要就是一大串token组成。
我们利用FactCC评估器(Kry′sci′nski et al。,2019b),它将正确性评估映射为二进制分类问题,即找到一个函数

其实就是给一个文章和摘要的一句话,输出0和1,对于一个摘要,多句话就取分数的平均。
生成训练数据的思路:正面样本:backtranslation: 摘要-->中间语言-->回译; 负面:我们应用实体交换,否定和代词交换生成否定示例
根据Kry′sci′nski等。 (2019b),我们使用相同的超参数微调BERTBASE模型以微调FactCC。 我们将文章和生成的声明与特殊标记[CLS]和[SEP]串联在一起。 [CLS]的最终嵌入用于计算claim蕴含在content中的可能性。

encoder-decoder结构,从源文章提取知识融入到摘要生成过程中。
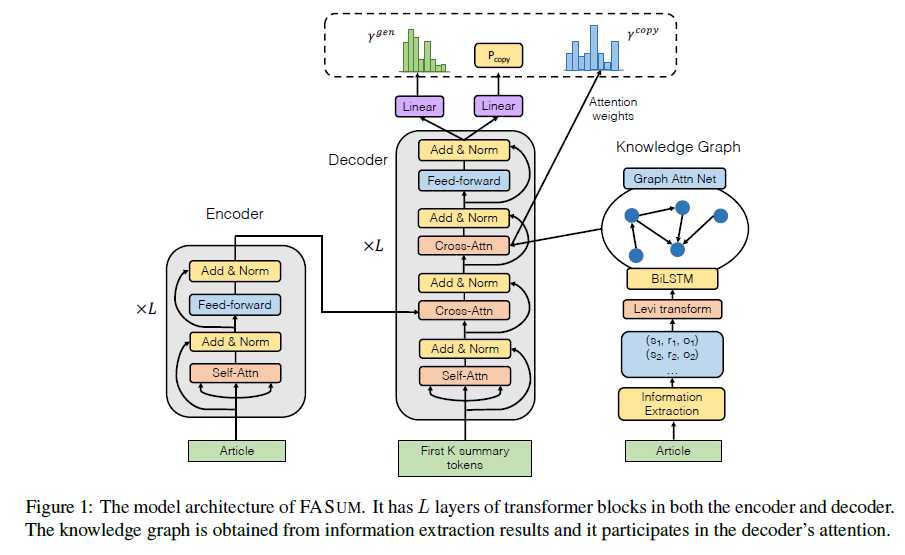
为了从文章中提取重要的实体关系信息,我们使用了斯坦福大学的OpenIE工具(Angeli等人,2015)。 提取的知识是元组列表。 每个元组包含一个主题(S),一个关系(R)和一个对象(O),每个都是文章文章的一部分。 在实验中,每篇文章平均提取165.4个元组。

抽取元组以后,把每个元组都变成三个结点,形成图,然后用graph attention network来获得embedding
与编码器并行地获得知识图嵌入。 然后,除了对编码器输出的规范交叉注意之外,每个解码器块还计算对知识图节点的嵌入的交叉注意:

用了copy-generate机制。

要么从词表选词,要么从node中选词

为了更好地利用现有的摘要系统,我们提出了一个事实校正器模型FC,以提高抽象系统生成的任何摘要的事实正确性。 FC将纠正过程归结为seq2seq问题:给定文章和候选摘要,模型将生成经过更正的摘要,并进行最少的更改以使事实与文章更加一致。
FC的模型架构为UniLM(Dong等,2019),由RoBERTa-Large的权重(Liu等,2019)初始化。 微调过程类似于训练去噪自动编码器。我们使用回译和实体交换来生成合成数据。 例如,事实摘要中的一个实体会随机替换为该文章中相同类型的另一个实体。修改后的摘要和文章将发送到校正器以恢复原始摘要。 在实验中,我们在CNN / DailyMail中生成了3.0M seq2seq数据样本,在XSum中生成了551.0K样本以进行微调。 我们在每个数据集中抽取1万个样本进行验证,其余的用于训练。
在本小节中,我们设计了一个易于计算的事实正确性度量标准,尤其是在没有ground-truth摘要的情况下。当知识图中的关系元组捕获文本中的事实信息时,我们计算摘要中提取的元组的精度。

实际就是从生成摘要里面提取的关系,在文章提取的关系中的命中率, 我们的度量标准的另一个优点是它不需要提供真实的摘要。
Boosting Factual Correctness of Abstractive Summarization with Knowledge Graph
标签:log network 方法 校正 eval rman 限制 修改 ima
原文地址:https://www.cnblogs.com/doragd/p/12840255.html