标签:调整 targe 分布 init contex 分布式 依赖关系 network voc
多篇开源CVPR 2020 语义分割论文
前言
1. DynamicRouting:针对语义分割的动态路径选择网络
Learning Dynamic Routing for Semantic Segmentation
作者团队:中科院&国科大&西安交大&旷视
论文链接:https://arxiv.org/abs/2003.10401
代码链接:https://github.com/yanwei-li/DynamicRouting
近年来,大量的人工搜索网络被应用于语义分割。然而,以前的工作意图在预定义的静态架构(如FCN、U-Net和DeepLab系列)中处理各种规模的输入。本文研究了一种新的概念化的语义表示方法,称为动态路由。该框架根据每个图像的尺度分布,生成与数据相关的路由。为此,提出了一种可微选通函数软条件门,用于动态选择尺度变换路径。此外,通过对选通函数给予预算约束,以端到端的方式进一步降低计算成本。进一步放宽了网络层的路由空间,以支持多径传播,并在每次转发时跳过连接,带来了可观的网络容量。为了证明动态特性的优越性,比较了几种静态结构,它们可以在路由空间中建模为特殊情况。为了说明动态框架的有效性,在Cityscapes and PASCAL VOC 2012上进行了广泛的实验。
注:性能优于Auto-DeepLab、PSPNet等网络,已收录于CVPR 2020(Oral)!
论文解读:CVPR 2020(Oral) | 旷视提出DynamicRouting:针对语义分割的动态路径选择网络
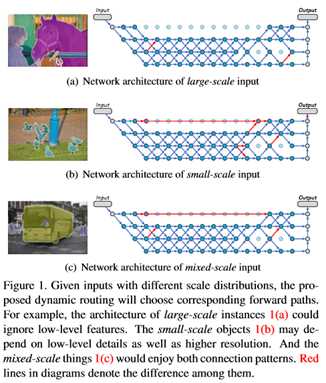
2. HANet:通过高度驱动注意力网络改善城市场景分割
Cars Can’t Fly up in the Sky: Improving Urban-Scene Segmentation via Height-driven Attention Networks
作者团队:LG&LLNL&高丽大学&韩国科学技术院
论文链接:https://arxiv.org/abs/2003.05128
代码链接:https://github.com/shachoi/HANet
本文利用城市场景图像的内在特征,提出了一个通用的附加模块高度驱动注意网络(HANet),用于改进城市场景图像的语义分割。它根据像素的垂直位置有选择地强调信息特征或类。在城市场景图像的水平分割区域中,像素级分布存在显著差异。同样,城市场景图像也有其独特的特征,但大多数语义分割网络并没有反映出这种独特的属性。该网络体系结构结合了利用属性对城市场景数据集进行有效处理的能力。验证了当采用HANet时,不同语义分割模型在两个数据集上的一致性性能(mIoU)的提高。这种广泛的定量分析表明,将模块添加到现有的模型中是容易和成本效益高的。在基于ResNet-101的分割模型中,方法在Cityscapes基准上获得了最新的性能,并且有很大的差距。通过对注意图的可视化和解释,证明了该模型与城市场景中观察到的事实是一致的。
注:在Cityscapes测试集高达83.2 mIoU!
论文解读:CVPR2020 | HANet:通过高度驱动的注意力网络改善城市场景语义分割
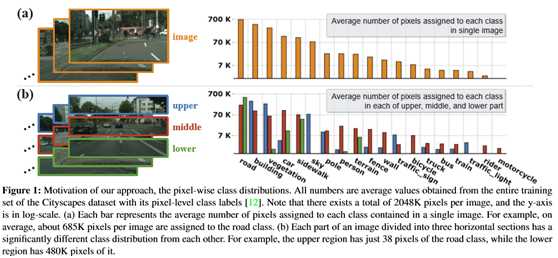
3. SPNet(条状池化):重新思考空间池化以进行场景解析
Strip Pooling: Rethinking Spatial Pooling for Scene Parsing
作者团队:新加坡国立大学&牛津大学&南开大学
论文链接:https://arxiv.org/abs/2003.13328
代码链接:https://github.com/Andrew-Qibin/SPNet
空间池在捕获像素级预测任务(如场景解析)的远程上下文信息方面已被证明是非常有效的。在本文中,除了通常具有规则NxN形状的传统空间池之外,通过引入一种新的池策略(称为条池策略)来重新考虑空间池的形式,该策略考虑了一个狭长的内核,即1xN或Nx1。在条带池的基础上,进一步研究了空间池的体系结构设计:1)引入了一个新的条带池模块,使骨干网能够有效地建模远程依赖关系;2)提出了一个以多种空间池为核心的新的构建块,(3)系统地比较了所提出的条带池和传统空间池技术的性能。这两种新的基于池的设计都是轻量级的,可以作为现有场景解析网络中的一个有效的即插即用模块。在流行基准(如ADE20K和Cityscapes)上进行的大量实验表明,我们的简单方法建立了新的最先进的结果。
注:本文提出SPNet语义分割新网络,含Strip池化方法,表现SOTA!性能优于CCNet、APNB和APCNet等网络
论文解读:CVPR2020 | Strip Pooling:语义分割新trick,条纹池化取代空间池化
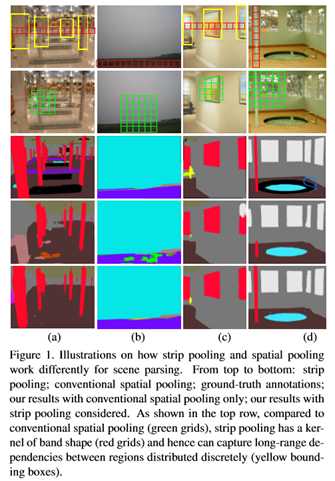
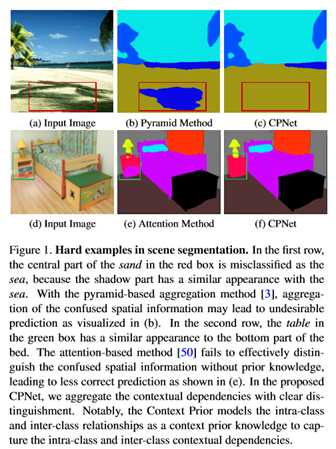
4. CPNet:场景分割的上下文先验(Prior)
Context Prior for Scene Segmentation
作者团队:华中科技大学&阿德莱德大学(沈春华)&港中文&腾讯(俞刚)
论文链接:https://arxiv.org/abs/2004.01547
代码链接:https://git.io/ContextPrior
近年来,为了获得更准确的分割结果,人们对上下文依赖进行了广泛的研究。然而,大多数方法很少区分不同类型的上下文依赖关系,这可能会影响场景理解。在这项工作中,直接监督特征聚合,以清楚地区分类内和类间上下文。具体来说,在监督亲和力损失之前开发一个上下文。在给定输入图像和相应的背景真实度的情况下,关联损失构造一个理想的关联映射来监督上下文的先验学习。学习的上下文先验提取属于同一类别的像素,而反向先验则聚焦于不同类别的像素。嵌入到传统的深层CNN中,提出的上下文优先层可以选择性地捕获类内和类间的上下文依赖关系,从而获得鲁棒的特征表示。为了验证其有效性,设计了一个有效的上下文优先网络(CPNet)。大量的定量和定性评估表明,所提出的模型优于目前最先进的语义分割方法。更具体地说,算法在ADE20K上达到46.3%的mIoU,在PASCAL上下文上达到53.9%的mIoU,在Cityscapes上达到81.3%的mIoU。
注:表现SOTA!性能优于ANL、EncNet和DenseASPP等网络论文解读:81.3%mIoU!华中科大等提出Context Prior:在语义分割中引入上下文先验 | CVPR2020
5. TDNet:用于快速视频语义分割的时间分布式网络
Temporally Distributed Networks for Fast Video Semantic Segmentation
作者团队:波士顿大学&Adobe研究院
论文链接:https://arxiv.org/abs/2004.01800
代码链接:https://github.com/feinanshan/TDNet
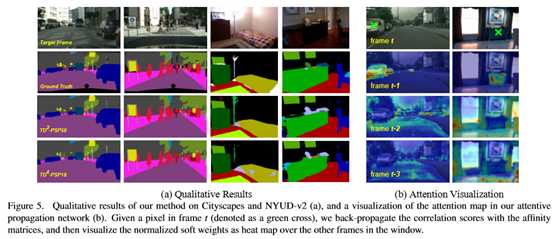
本文提出了一种时间分布的视频语义分割网络TDNet。从深层CNN的某一高层提取的特征可以通过组合从几个较浅的子网络提取的特征来近似。利用视频中固有的时间连续性,将这些子网络分布在连续帧上。因此,在每个时间步骤中,只需执行轻量级计算即可从单个子网络中提取子特征组。然后应用一种新的注意传播模块来补偿帧间的几何变形,从而重新构造用于分割的全部特征。为了进一步提高全特征层和子特征层的表示能力,还引入了分组知识蒸馏损失。在CityScape、CamVid和NYUD-v2上的实验表明,方法以更快的速度和更低的延迟达到了最先进的精度。
注:表现SOTA!性能优于PSPNet、BiseNet等网络。
6. SEAM:弱监督语义分割的自监督等变注意力机制
Self-supervised Equivariant Attention Mechanism for Weakly Supervised Semantic Segmentation
作者团队:中科院&国科大等
论文链接:https://arxiv.org/abs/2004.04581
代码链接:https://github.com/YudeWang/SEAM
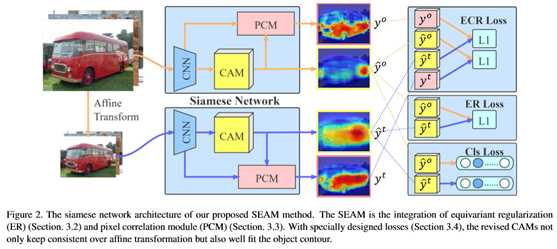
图像级弱监督语义分割是近年来深入研究的一个具有挑战性的问题。大多数高级解决方案利用类激活图(CAM)。然而,由于监控的充分性和薄弱性,CAMs很难作为目标遮罩。本文提出了一种自监督的等变注意机制(SEAM),以发现额外的监督并缩小差距。方法是基于在全监督语义分割中,等价性是一个隐含的约束条件,其像素级标签在数据增强过程中与输入图像采用相同的空间变换。然而,这种约束在由图像级监控训练的CAMs上丢失了。因此,提出了基于不同变换图像的预测CAMs一致性正则化,为网络学习提供自我监控。此外,还提出了一个像素相关模块(PCM),该模块利用上下文外观信息,并通过其相似邻域对当前像素进行细化预测,从而进一步提高了CAMs的一致性。在PASCAL VOC 2012数据集上的大量实验表明,方法优于使用相同监控级别的最新方法。
注:表现SOTA!性能优于AffinityNet、IRNet和DCSP等网络
7. SEAM:弱监督语义分割的自监督等变注意力机制
Unsupervised Intra-domain Adaptation for Semantic Segmentation through Self-Supervision
作者团队:韩国科学技术院(KAIST)
论文链接:https://arxiv.org/abs/2004.07703
代码链接:https://github.com/feipan664/IntraDA
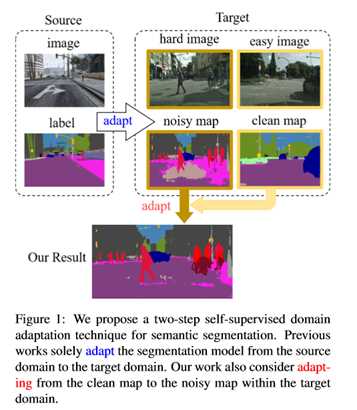
基于卷积神经网络的语义分割方法取得了显著的进展。然而,这些方法在很大程度上依赖于劳动密集型的注释数据。为了克服这一局限性,利用图形引擎生成的自动标注数据训练分割模型。然而,从合成数据中训练出来的模型很难转化为真实的图像。为了解决这个问题,以前的工作考虑直接将模型从源数据调整到未标记的目标数据(以减少域间的差距)。尽管如此,这些技术并没有考虑到目标数据本身之间的巨大分布差距(域内差距)。在这项工作中,提出了一个两步自监督域适应方法,以最小化域间和域内的差距。首先,对模型进行域间自适应;从这种自适应中,使用基于熵的排序函数将目标域分成容易和难分割的两部分。最后,为了减小域内的差距,建议采用一种自监督的自适应技术,从易分割到难分割。在大量基准数据集上的实验结果突出了方法相对于现有的最新方法的有效性。
注:表现SOTA!性能优于AdaptSegNet、AdvEnt和CyCADA等网络。
标签:调整 targe 分布 init contex 分布式 依赖关系 network voc
原文地址:https://www.cnblogs.com/wujianming-110117/p/12848380.html