标签:blog 多对多 boost 分类器 字符串 解析 txt 词汇 包含
文本分类属于文本挖掘。文本挖掘从已知文本提取未知的知识,即从非结构的文本中提取知识。文本挖掘主要领域:搜索和信息检索;文本聚类;文本分类;Web挖掘;信息抽取;自然语言处理;概念提取。[1]
文本分类方法:
一、基于模式系统。也称为专家系统,将知识以规则表达式的形式进行分类‘;
二、基于机器学习,即广义的归纳过程,采用一组与分类的例子,通过训练简历分类,是一种自动分类的技术。
一、单标签二分类算法
单标签的 label 标签取值只有两种,并且算法中只有一个需要预测的标签的label 标签,即分类算法构建一个分类线将数据划分为两个类别。
常用算法:Logistic、SVM、KNN、决策树等。
二、单标签多分类算法
单标签多分类:待预测的 label 只有一个,但是label 标签的取值有多个,例如,
假设有类["酸", "甜", "苦", "辣", "香"], "这个水果点酸"(label="酸"),"这个菜看起来很香"(label="香");
常见算法:Softmax、SVM、KNN、决策树(集成学习 ----RF(Bagging)、Boosting(Adaboost、GBDT);XGBoost)
多分类问题转换为二分类算法的延伸,即将多分类任务拆分为若 干个二分类任务求解,
具体的策略如下:
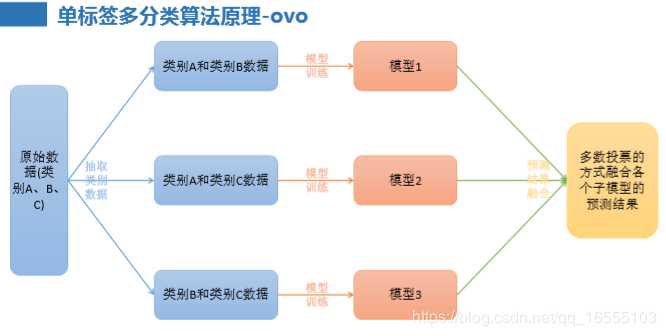
1、OVO(一对一)
原理:将K个类别中的两两类别数据进行组合,然后使用组合后的 数据训练出来一个模型,从而产生K(K-1)/2个分类器,将这些分类器的结果进行融合,并将分类器的预测结果使用多数投票的方式 输出最终的预测结果值。
2、OVR (一对多)
1、ovr与softmax的区别:
softmax 每一次训练模型用的是整个训练数据中的某一类别的数据,从而的该类别的权重系数,通过测试集计算各个类型权
重的预测值,取最大的预测值(或者概率)的类型作为预测类型。
ovr 每一次是代入所有的训练集数据来训练子模型,取出结果为正例的类别(多个正例取最大值)。
fasttext的命令包括: supervised: 训练一个监督分类器 quantize:量化模型以减少内存使用量 test:评估一个监督分类器 predict:预测最有可能的标签 predict-prob:用概率预测最可能的标签 skipgram:训练一个 skipgram 模型 cbow:训练一个 cbow 模型 print-word-vectors:给定一个训练好的模型,打印出所有的单词向量 print-sentence-vectors:给定一个训练好的模型,打印出所有的句子向量 nn:查询最近邻居 analogies:查找所有同类词
1、训练文本分类器,使用 fasttext.train_supervised 函数,如下所示:
import fasttext model = fasttext.train_supervised(‘data.train.txt‘)
其中,data.train.txt 是一个文本文件,每行包含一个训练语句以及标签。默认情况下,我们假定标签是带有字符串 __label__ 前缀的词
训练好模型后,可以检索单词和标签的列表:
print(model.words) print(model.labels)
为评估模型的精度和召回率,使用 test 函数:
def print_results(N, p, r): print("N\t" + str(N)) print("P@{}\t{:.3f}".format(1, p)) print("R@{}\t{:.3f}".format(1, r)) print_results(*model.test(‘test.txt‘))
也可为特定文本预测标签:
model.predict("Which baking dish is best to bake a banana bread ?")
一般地, predict 函数值返回一个标签:即概率最高的标签。也可通过指定参数 k 返回多个标签,例如:
model.predict("Which baking dish is best to bake a banana bread ?", k=3)
也可预测多个数据,可以传递一个列表,如:
model.predict(["Which baking dish is best to bake a banana bread ?", "Why not put knives in the dishwasher?"], k=3)
[1] https://www.cnblogs.com/xiaochi/p/10957729.html
[2] https://blog.csdn.net/qq_16555103/article/details/89104413
[3] https://pypi.org/project/fasttext
标签:blog 多对多 boost 分类器 字符串 解析 txt 词汇 包含
原文地址:https://www.cnblogs.com/yefan19/p/12820766.html